
效能監控的好工具 - NewRelic 簡介(轉)
首先你需要在網站上註冊一個新帳號,根據伺服器端的應用框架選擇安裝對應的外掛,它提供了很多常見應用框架外掛,以Rails為例子,只需要在Gemfile配置,執行bundle install即可:
gem 'newrelic_rpm'
然後下載對應的newrlic.yml配置檔案,放入到應用目錄,進行一些引數的調整。將應用重新部署以後,等幾分鐘,讓外掛收集到效能相關資料,再去訪問NewRelic網站,就可以看到各種圖表了。
首先需要關注的是請求的響應時間圖表,用這個圖表可以對請求在伺服器端耗時有個整體印象:
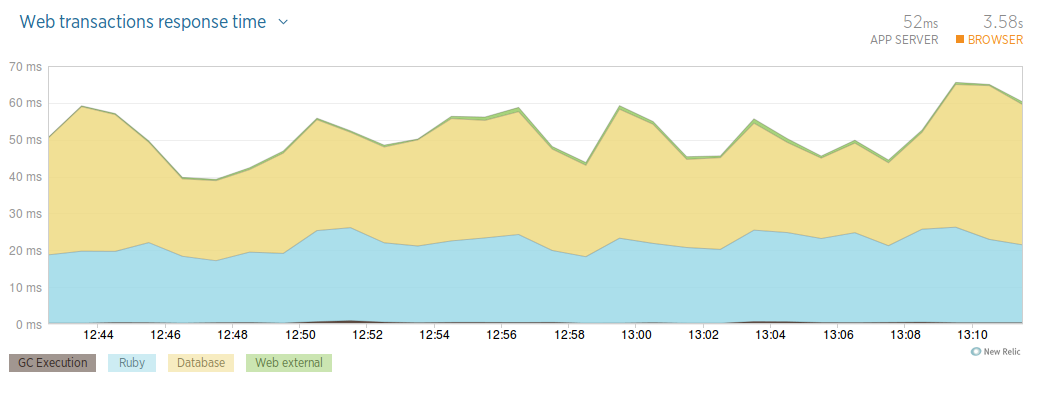
從圖表上可以看到,在這個時間段,請求的平均耗時是52ms,同時可以看到每個請求的Ruby程式碼和資料庫執行時間佔據了絕大部分,還有少量的外部服務呼叫時間(比如第3方Oauth或者API)。由於我們使用OOB GC,所以在圖表上幾乎沒有GC的時間。
另外右上角有一個3.58s的瀏覽器時間,這個是指使用者訪問網頁,從請求發出,到整個頁面完全載入完成(包括圖片,css,js等)。
第二個圖表是Apdex (Application Performance Index),從這裡可以看到大部分使用者是否滿意你的應用響應速度:
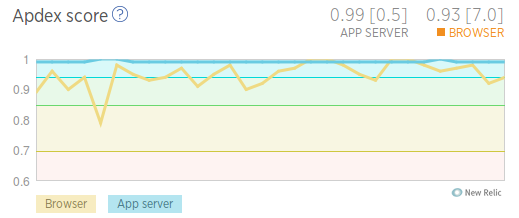
從圖表可以看到,99%的使用者非常滿意請求響應時間(在我們的應用裡面,大部分請求是客戶端呼叫api),93%的使用者非常滿意頁面載入完成的時間。我們用的指標是NewRelic預設設定的500ms和7s,你還可以自己進行調整。
第3個圖表是吞吐量
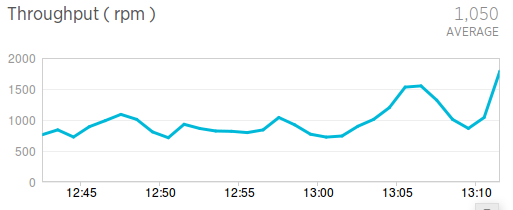
可以看出在這半個小時的區間,平均每分鐘有1050個請求。用這個圖表,通過調整時間段(,瞭解整個應用什麼時候是高峰,什麼時候是低谷,方便將一些批處理,備份等任務放在訪問低谷的時間段進行。還有當使用者報告無法訪問的時候,可以通過檢視吞吐量是否有急劇下降,來判斷是個例還是整體故障,來確定解決問題的優先順序。免費版本的NewRelic,只能檢視過去24小時的資料,升級到付費帳號,可以檢視所有的歷史資料。
第4個圖表是根據請求的時間和請求的次數,列出一個最耗時的請求
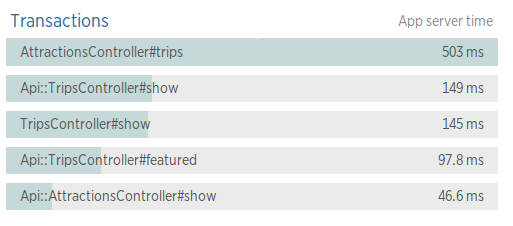
我們可以根據這個排列順序,來考慮對於訪問量大,同時又耗時的請求進行重點效能優化。
點選具體的請求,還可以看到請求耗時的分佈情況:
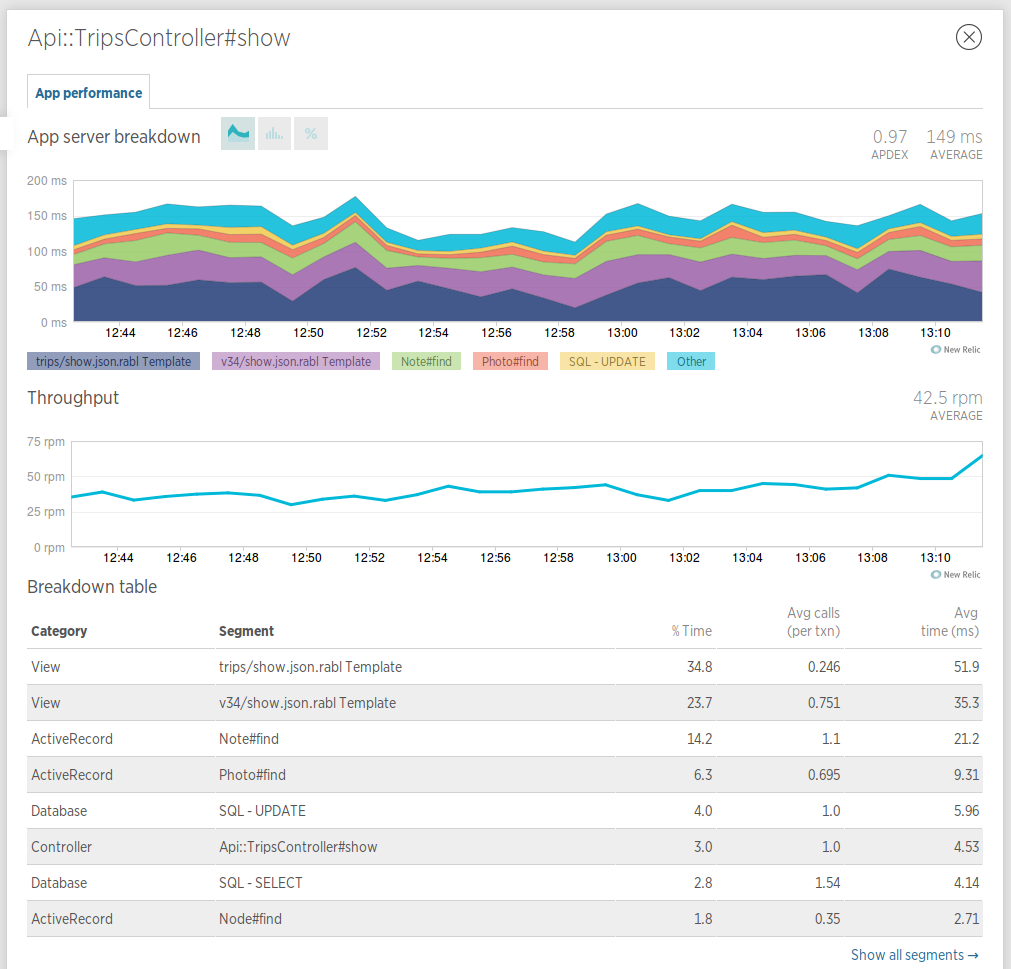
從圖表上可以看到這個請求,在渲染json資料耗費了比較多的時間,另外在ActiveRecord的查詢上也耗費了一些時間,如果要優化的話,就可以從渲染結果加片段快取,或者查詢優化入手。升級到付費版本,還能檢視到具體的sql語句執行情況,如果有slow query,還能顯示explain的結果。
第5個圖表,是錯誤率
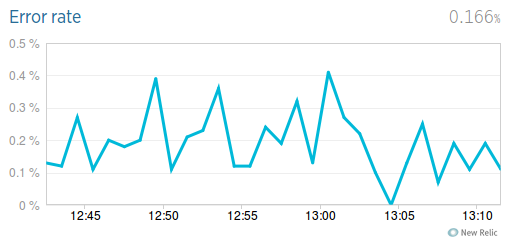
在我們應用中引發錯誤的大部分是一些爬蟲404,還有一些是異常資料沒有處理好導致,這裡就不詳細介紹了。這個圖表對於使用者反饋錯誤定位也是很有幫助的。
第6個圖表,是應用效能分佈到各個伺服器狀態
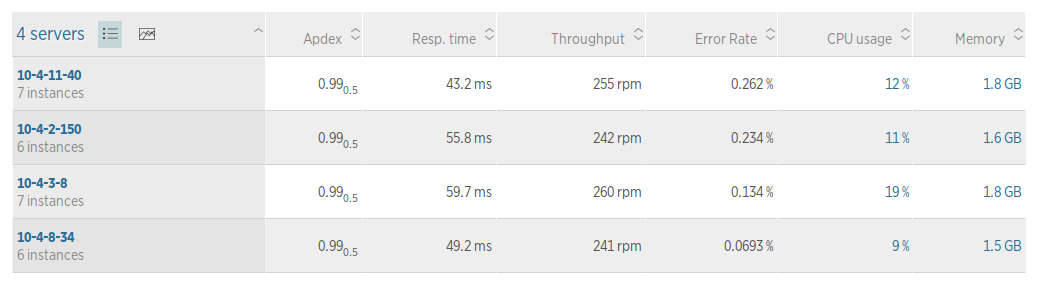
對於瞭解伺服器資源和擴容計劃很有幫助。順便說一個實際遇到的事情,發現過某臺主機(我們用的雲主機)的響應時間就是比其他臺要慢50%以上,對比發現這臺的CPU和Disk IO都比其他臺要弱,後來報告給雲主機服務商,通過遷移到了新的物理機解決了。
除了上述的這些效能圖表,NewRelic也提供了很多監控的選項,比如ping,記憶體/儲存警報等,可以將報警傳送到郵件,或者推送到移動客戶端: