
[玩轉MySQL之七]InnoDB儲存引擎架構簡介
一、引言
在MySQL做完優化工作後,真正執行SQL語句的部件是儲存引擎。在MySQL眾多引擎之中,InnoDB是目前預設的儲存引擎,也是使用最廣泛的引擎。
InnoDB是事務安全的MySQL儲存引擎,支援ACID事務。其設計目標主要面向線上事務處理(OLTP)的應用。其特點是行鎖設計、支援外來鍵,並支援非鎖定讀,即預設讀操作不會產生鎖。InnoDB儲存資料是基於磁碟儲存的,且其記錄是按照頁的方式進行管理。那麼將引出如下疑問:
- 當前的磁碟速度和CPU之間擁有一條巨大的鴻溝,InnoDB如何解決?。
- 資料庫對資料進行操作(查詢,修改,插入)時,資料在磁碟上的位置是隨機的,將會更加影響操作資料的效能,InnoDB又是如何解決的?
- 針對問題1,非常有效的辦法是引入快取來解決,但是引入快取後,會導致快取資料和磁碟資料一致性和MySQL非正常死亡時快取資料丟失的問題。
- InnoDB有哪些重要特性?
二、InnoDB體系架構
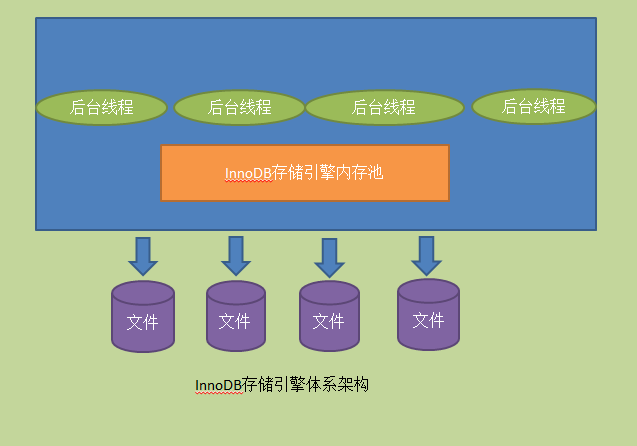
如圖所示,InnoDB儲存引擎由記憶體池和一些後臺執行緒組成,其各自主要的工作是:
記憶體池主要工作
- 維護所有程序/執行緒需要訪問的多個內部資料結構
- 快取磁碟上的資料,方便快速讀取,同時在對磁碟檔案修改之前進行快取
- 快取重做日誌(redo log)
後臺執行緒主要工作
- 重新整理記憶體池中的資料,保證緩衝池中快取的資料最新
- 將已修改資料檔案重新整理到磁碟檔案
- 保證資料庫異常時InnoDB能恢復到正常執行狀態
2.1、 InnoDB記憶體池
2.1.1. InnoDB記憶體池架構圖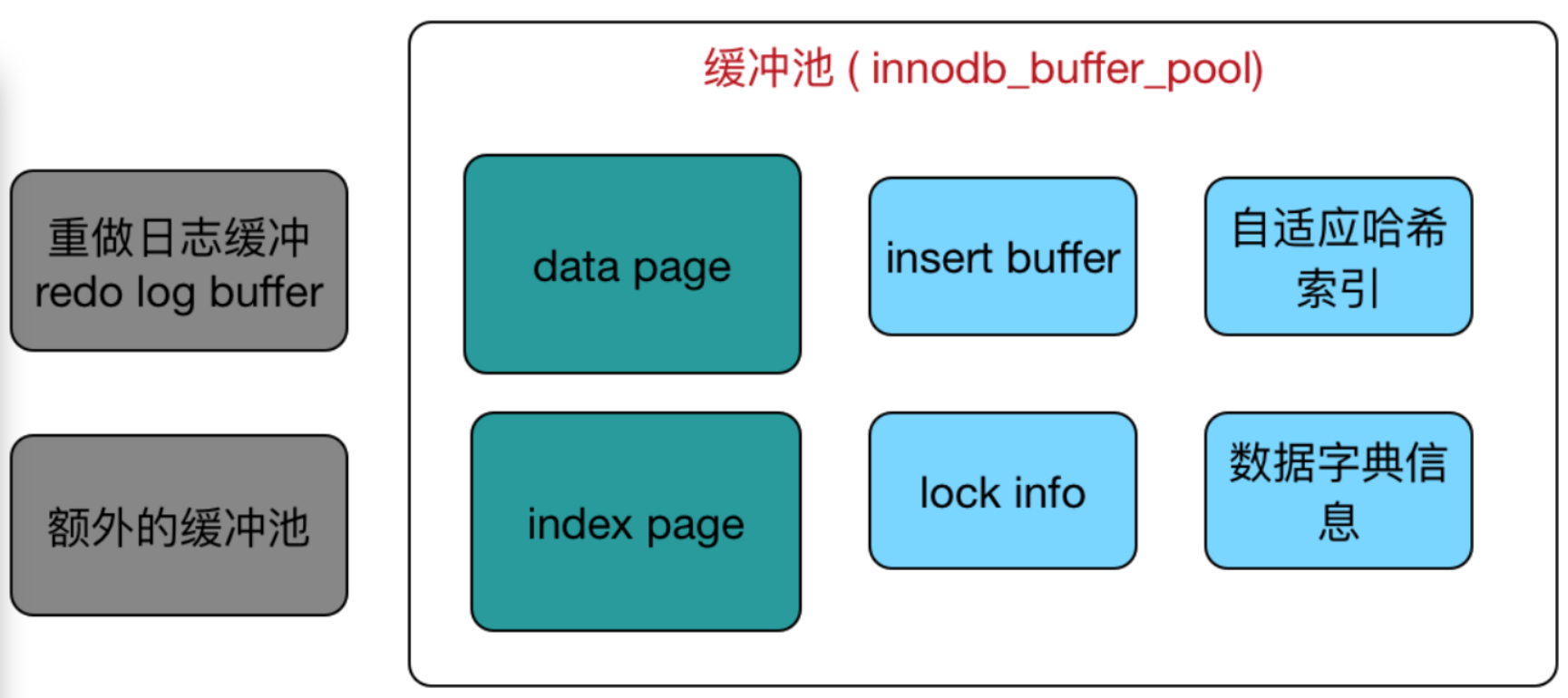
2.1.2、 緩衝池
InnoDB緩衝池是為了通過記憶體的速度來彌補磁碟速度慢對資料庫效能造成的影響。其工作方式總是將資料庫檔案按頁(每頁16K)讀取到緩衝池,然後按最近最少使用(LRU)的演算法來保留在緩衝池中的快取資料。在資料庫中進行讀操作時,首先將從磁碟讀到的頁存放在緩衝池中,下一次讀取相同的頁時,首先判定是否存在緩衝池中,如果有就是被命中直接讀取,沒有的話就從磁碟中讀取。在資料庫進行改操作時,首先修改緩衝池中的頁(修改後,該頁即為髒頁),然後在以一定的頻率重新整理到磁碟上。這裡的重新整理機制不是每頁在發生變更時觸發。而是通過一種checkpoint機制重新整理到磁碟的。
所以緩衝池的大小直接影響著資料庫的整體效能,可以通過配置引數innodb_buffer_pool_size來設定。
從架構圖中可以看出緩衝池中快取的資料頁型別有:索引頁、資料頁、 undo 頁、插入緩衝、自適應雜湊索引、 InnoDB 的鎖資訊、資料字典資訊等。索引頁和資料頁佔緩衝池的很大一部分。
- 資料頁和索引頁: Page是Innodb儲存的最基本結構,也是Innodb磁碟管理的最小單位,與資料庫相關的所有內容都儲存在Page結構裡。Page分為幾種型別,資料頁和索引頁就是其中最為重要的兩種型別。
- 插入快取: 在InnoDB引擎上進行插入操作時,一般需要按照主鍵順序進行插入,這樣才能獲得較高的插入效能。當一張表中存在非聚簇的且不唯一的索引時,在插入時,資料頁的存放還是按照主鍵進行順序存放,但是對於非聚簇索引葉節點的插入不再是順序的了,這時就需要離散的訪問非聚簇索引頁,由於隨機讀取的存在導致插入操作效能下降。
InnoDB為此設計了Insert Buffer來進行插入優化。對於非聚簇索引的插入或者更新操作,不是每一次都直接插入到索引頁中,而是先判斷插入的非聚集索引是否在緩衝池中,若在,則直接插入;若不在,則先放入到一個Insert Buffer中。看似資料庫這個非聚集的索引已經查到葉節點,而實際沒有,這時存放在另外一個位置。然後再以一定的頻率和情況進行Insert Buffer和非聚簇索引頁子節點的合併操作。這時通常能夠將多個插入合併到一個操作中,這樣就大大提高了對於非聚簇索引的插入效能。 -
自適應雜湊索引: InnoDB會根據訪問的頻率和模式,為熱點頁建立雜湊索引,來提高查詢效率。InnoDB儲存引擎會監控對錶上各個索引頁的查詢,如果觀察到建立雜湊索引可以帶來速度上的提升,則建立雜湊索引,所以叫做自適應雜湊索引。
自適應雜湊索引是通過緩衝池的B+樹頁構建而來,因此建立速度很快,而且不需要對整張資料表建立雜湊索引。其 有一個要求,即對這個頁的連續訪問模式必須是一樣的,也就是說其查詢的條件(WHERE)必須完全一樣,而且必須是連續的。 - 鎖資訊 : nnoDB儲存引擎會在行級別上對錶資料進行上鎖。不過InnoDB也會在資料庫內部其他很多地方使用鎖,從而允許對多種不同資源提供併發訪問。資料庫系統使用鎖是為了支援對共享資源進行併發訪問,提供資料的完整性和一致性。關於鎖的具體知識我們之後再進行詳細學習。
-
資料字典資訊 : InnoDB有自己的表快取,可以稱為表定義快取或者資料字典。當InnoDB開啟一張表,就增加一個對應的物件到資料字典。
資料字典是對資料庫中的資料、庫物件、表物件等的元資訊的集合。在MySQL中,資料字典資訊內容就包括表結構、資料庫名或表名、欄位的資料型別、檢視、索引、表字段資訊、儲存過程、觸發器等內容。MySQL INFORMATION_SCHEMA庫提供了對資料局元資料、統計資訊、以及有關MySQL server的訪問資訊(例如:資料庫名或表名,欄位的資料型別和訪問許可權等)。該庫中儲存的資訊也可以稱為MySQL的資料字典。
2.1.3. 重做日誌衝池
InnoDB有buffer pool(簡稱bp)。bp是資料庫頁面的快取,對InnoDB的任何修改操作都會首先在bp的page上進行,然後這樣的頁面將被標記為dirty並被放到專門的flush list上,後續將由master thread或專門的刷髒執行緒階段性的將這些頁面寫入磁碟(disk or ssd)。這樣的好處是避免每次寫操作都操作磁碟導致大量的隨機IO,階段性的刷髒可以將多次對頁面的修改merge成一次IO操作,同時非同步寫入也降低了訪問的時延。然而,如果在dirty page還未刷入磁碟時,server非正常關閉,這些修改操作將會丟失,如果寫入操作正在進行,甚至會由於損壞資料檔案導致資料庫不可用。為了避免上述問題的發生,Innodb將所有對頁面的修改操作寫入一個專門的檔案,並在資料庫啟動時從此檔案進行恢復操作,這個檔案就是redo log file。這樣的技術推遲了bp頁面的重新整理,從而提升了資料庫的吞吐,有效的降低了訪問時延。帶來的問題是額外的寫redo log操作的開銷(順序IO,當然很快),以及資料庫啟動時恢復操作所需的時間。
redo日誌由兩部分構成:redo log buffer、redo log file。innodb是支援事務的儲存引擎,在事務提交時,必須先將該事務的所有日誌寫入到redo日誌檔案中,待事務的commit操作完成才算整個事務操作完成。在每次將redo log buffer寫入redo log file後,都需要呼叫一次fsync操作,因為重做日誌緩衝只是把內容先寫入作業系統的緩衝系統中,並沒有確保直接寫入到磁碟上,所以必須進行一次fsync操作。因此,磁碟的效能在一定程度上也決定了事務提交的效能。
InnoDB 儲存引擎先將重做日誌資訊放入這個緩衝區,然後以一定頻率將其重新整理到重做日誌檔案。重做日誌檔案一般不需要設定得很大,因為在下列三種情況下重做日誌緩衝中的內容會重新整理到磁碟的重做日誌檔案中。
- Master Thread 每一秒將重做日誌緩衝重新整理到重做日誌檔案
- 每個事物提交時會將重做日誌緩衝重新整理到重做日誌檔案
- 當重做日誌緩衝剩餘空間小於1/2時,重做日誌緩衝重新整理到重做日誌檔案
2.1.4. 額外的緩衝池
在 InnoDB 儲存引擎中,對一些資料結構本身的記憶體進行分配時,需要從額外的記憶體池中進行申請。例如: 分配了緩衝池,但是每個緩衝池中的幀緩衝還有對應的緩衝控制物件,這些物件記錄以一些諸如 LRU, 鎖,等待等資訊,而這個物件的記憶體需要從額外的記憶體池中申請。
2.2 主要後臺執行緒
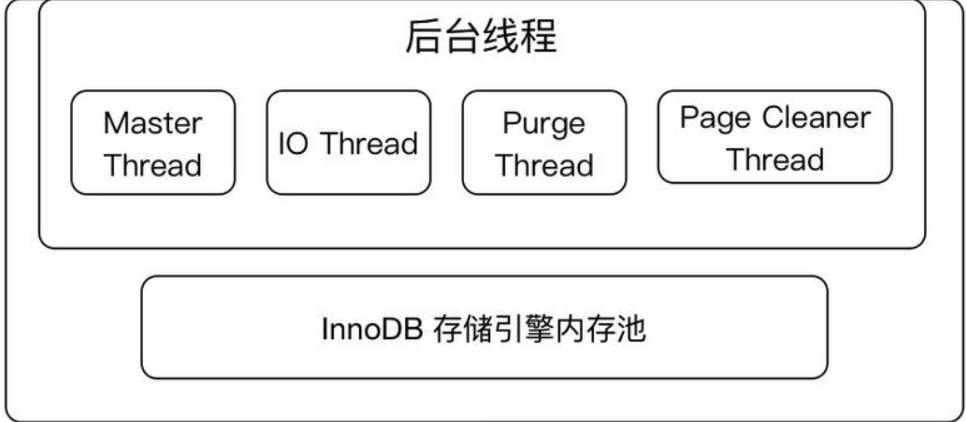
2.2.1. master thread
核心的後臺執行緒,主要負責將緩衝池中的資料非同步重新整理到磁碟,保證資料的一致性,包括髒頁的重新整理、合併插入緩衝、undo頁的回收等。
Master thread在主迴圈中,分兩大部分操作,每秒鐘的操作和每10秒鐘的操作:
-
每秒一次的操作
- 日誌緩衝重新整理到磁碟: 即使這個事務還沒有提交(總是),這點解釋了為什麼再大的事務commit時都很快;
- 合併插入緩衝(可能): 合併插入並不是每秒都發生,InnoDB會判斷當前一秒內發生的IO次數是否小於5,如果是,則系統認為當前的IO壓力很小,可以執行合併插入緩衝的操作。
- 至多重新整理100個InnoDB的緩衝池的髒頁到磁碟(可能) : 這個重新整理100個髒頁也不是每秒都在做,InnoDB引擎通過判斷當前緩衝池中髒頁的比例(buf_get_modified_ratio_pct)是否超過了配置檔案中innodb_max_drity_pages_pct引數(預設是90,即90%),如果超過了這個閾值,InnoDB引擎認為需要做磁碟同步操作,將100個髒頁寫入磁碟。
-
每10秒一次的操作
- 重新整理100個髒頁到磁碟(可能): InnoDB引擎先判斷過去10秒內磁碟的IO操作是否小於200次,如果是,認為當前磁碟有足夠的IO操作能力,即將100個髒頁重新整理到磁碟。
- 合併至多5個插入緩衝(總是): 此次的合併插入緩衝操作總會執行,不同於每秒操作時可能發生的合併操作。
- 將日誌緩衝重新整理到磁碟(總是): InnoDB引擎會再次執行日誌緩衝重新整理到磁碟的操作,與每秒發生的操作一樣。
- 刪除無用的undo頁(總是): 當對錶執行update,delete操作時,原先的行會被標記為刪除,但是為了一致性讀的關係,需保留這些行版本的資訊,在進行10S一次的刪除操作時,InnoDB引擎會判斷當前事務系統中已被刪除的行是否可以刪除,如果可以,InnoDB會立即將其刪除。InnoDB每次最多刪除20個Undo頁。
- 產生一個檢查點(checkpoing);
2.2.2. IO threads
在 InnoDB 儲存引擎中大量使用了非同步 IO 來處理寫 IO 請求,IO Thread 的工作主要是負責這些 IO 請求的回撥.。分別為write、read、insert buffer和log IO thread。執行緒數量可以通過引數進行調整。5.6以後的版本可以通過innodb_write_io_threads和innodb_read_io_threads來限制讀寫執行緒,而在5.6版本以前,只有一個引數innodb_file_io_threads來控制讀寫匯流排程數。
2.2.3. purge threads
負責回收已經使用並分配的undo頁,purge操作預設是由master thread中完成的,為了減輕master thread的工作,提高cpu使用率以及提升儲存引擎的效能。使用者可以在引數檔案中新增如下命令來啟動獨立的purge thread。
innodb_purge_threads=1
從innodb1.2版本開始,可以指定多個innodb_purge_threads來進一步加快和提高undo回收速度。
2.2.4. page cleaner threads
Page Cleaner Thread是在InnoDB1.2.X版本中引入的。其作用是將之前版本中髒頁的重新整理操作都放入到單獨的執行緒中來完成。 其目的是減輕master thread的工作以及對於使用者查詢執行緒的阻塞,進一步提高InnoDB儲存引擎的效能。
三、InnoDB重要特性
MySQL InnoDB通過如下重要特性實現了更好的新能和更高的特性
- 插入緩衝(insert buffer)
- 兩次寫(Double write)
- 自適應雜湊索引(adaptive hash index)
- 非同步io(Async IO)
- 重新整理領接頁(Flush Neighbor Page)
3.1 插入緩衝
3.1.1. 舉個栗子
我們去圖書館還書,對應圖書館來說,他是做了insert(增加)操作,管理員在1小時內接受了100本書,這時候他有2種做法把還回來的書歸位到書架上:
1)每還回來一本書,根據這本書的編碼(書櫃區-排-號)把書送回架上
2)暫時不做歸位操作,先放到櫃面上,等不忙的時候,再把這些書按照書櫃區-排-號先排好,然後一次性歸位
用方法1,管理員需要進出(IO)藏書區100次,不停的登高爬低完成圖書歸位操作,累死累活,效率很差。
用方法2,管理員只需要進出(IO)藏書區1次,對同一個位置的書,不管多少,都只要爬一次樓梯,大大減輕了管理員的工作量。
所以圖書館都是按照方法2來做還書動作的。但是你要說,我的圖書館就20本書,1個0.5米的架子,方法2和1管理起來都很方便,這種情況不在我們討論的範圍。當資料量非常小的時候,就不存在效率問題了。
關係資料庫在處理插入操作的時候,處理的方法和上面類似,每一次插入都相當於還一本書,它也需要一個櫃檯來儲存插入的資料,然後分類歸檔,在不忙的時候做批量的歸位。這個櫃檯就是insert buffer.
這就是為什麼會有insert buffer,更多的是處於效能優化的考慮。
3.1.2. 什麼是插入緩衝
insert buffer是一種特殊的資料結構(B+ tree)並不是快取的一部分,而是物理頁。對於非聚集索引的插入或更新操作,不是每一次直接插入索引頁.而是先判斷插入的非聚集索引頁是否在緩衝池中.如果在,則直接插入,如果不再,則先放入一個插入緩衝區中.然後再以一定的頻率執行插入緩衝和非聚集索引頁子節點的合併操作.使用條件:非聚集索引,非唯一,原因如下:
- primary key 是按照遞增的順序進行插入的,異常插入聚族索引一般也順序的,非隨機IO。
- 寫唯一索引要檢查記錄是不是存在,所以在修改唯一索引之前,必須把修改的記錄相關的索引頁讀出來才知道是不是唯一、這樣Insert buffer就沒意義了,要讀出來(隨機IO),所以只對非唯一索引有效。
3.1.3. insert buffer的原理
對於為非唯一索引,輔助索引的修改操作並非實時更新索引的葉子頁,而是把若干對同一頁面的更新快取起來做,合併為一次性更新操 作,減少IO,轉隨機IO為順序IO,這樣可以避免隨機IO帶來效能損耗,提高資料庫的寫效能,具體流程:
1) 先判斷要更新的這一頁在不在緩衝池中
a、若在,則直接插入;
b、若不在,則將index page 存入Insert Buffer,按照Master Thread的排程規則來合併非唯一索引和索引頁中的葉子結點
2) Master Thread的排程規則
a、主動merger: innodb主執行緒定期完成,使用者執行緒無感知
主動merge通過innodb主執行緒(svr_master_thread)判斷:若過去1s之內發生的I/O小於系統I/O能力的5%,則主動進行一次insert buffer的merge操作。merge的頁面數為系統I/O能力的5%,讀取採用async io模式。每10s,必定觸發一次insert buffer meger操作。meger的頁面數仍舊為系統 I/O能力的5%。
- 主執行緒發出async io請求,async讀取需要被merge的索引頁面
- I/O handler 執行緒,在接受到完成的async I/O之後,進行merge
b 、被動merge: 使用者執行緒完成,使用者能感受到meger操作帶來的效能影響
- insert操作,導致頁面空間不足,需要分裂(split)。由於insert buffer只針對單個頁面,不能buffer page split[頁已經在記憶體裡],因此引起頁面的被動meger。同理,update操作導致頁面空間不 足;purge導致頁面為空等。總之,若當前操作引起頁面split or merge,那麼就會導致被動merge;
- insert操作,由於其它各種原因,insert buffer優化返回false,需要真正讀取page時,要進行被動merge。與一不同的是,頁在disk上,需要讀取到記憶體裡;
- 在進行insert buffer操作,發現insert buffer太大,需要壓縮insert buffer,這時需要強制被動merge,不允許 insert 操作進行。
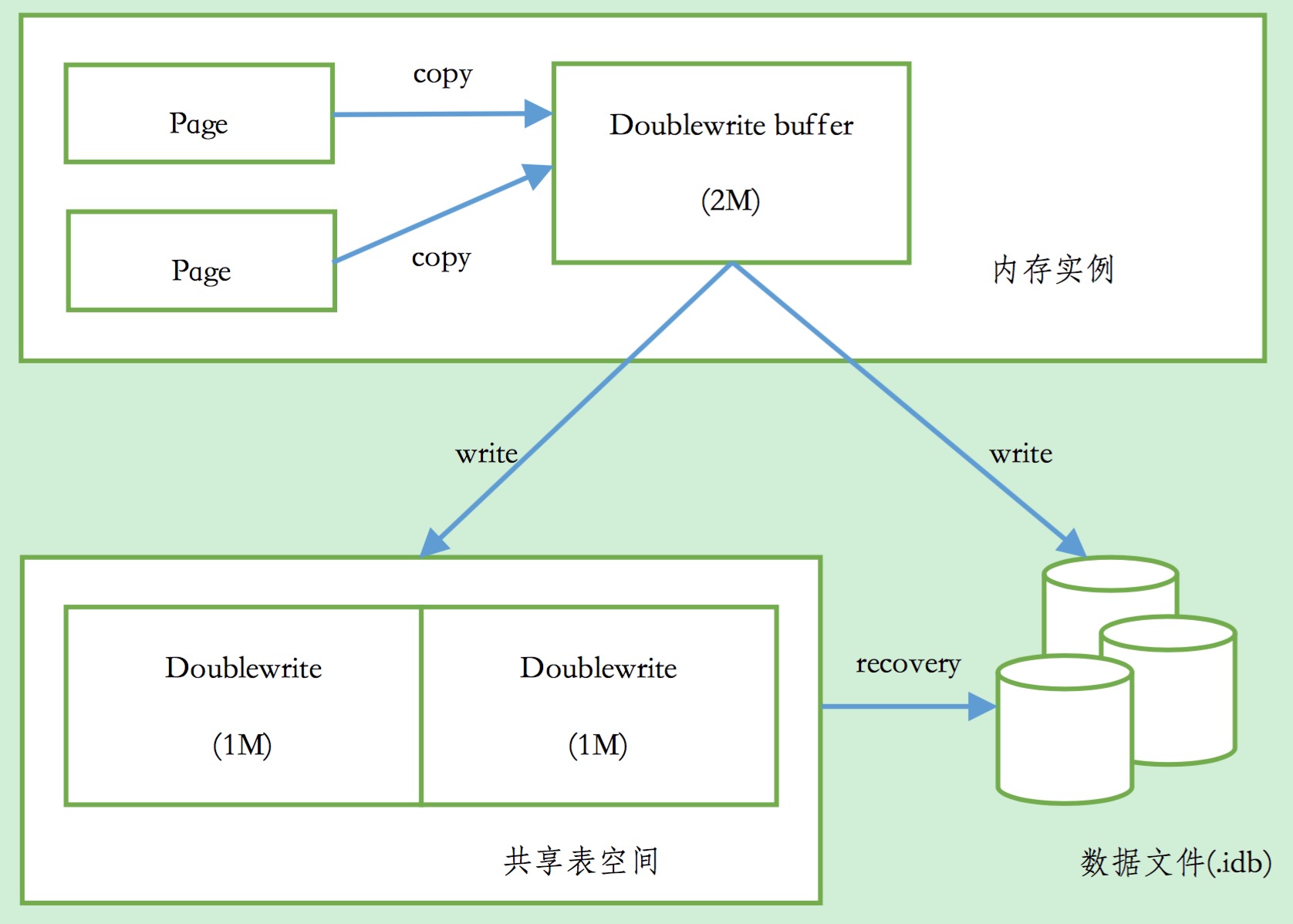
3.2 兩次寫
Insert Buffer帶給InnoDB儲存引擎的是效能上的提升,doublewrite(兩次寫)帶給InnoDB儲存引擎的是資料頁的可靠性。
當發生資料庫宕機時,可能InnoDB儲存引擎正在寫入某個頁到表中,而這個頁只寫了一部分,比如16KB的頁,只寫了前4KB,之後就發生了宕機,這種情況被稱為部分寫失效(partial page write)。在InnoDB儲存引擎未使用doublewrite技術前,曾經出現過因為部分寫失效而導致資料丟失的情況。
有經驗的DBA也許會想,如果發生寫失效,可以通過重做日誌進行恢復。這是一個辦法。但是必須清楚地認識到,重做日誌中記錄的是對頁的物理操作,如偏移量800,寫‘aaaa’記錄。如果這個頁本身已經發生了損壞,再對其進行重做是沒有意義的。這就是說,在應用重做日誌前,使用者需要一個頁的副本,當寫入失效發生時,先通過頁的副本來還原該頁,再進行重做,這就是doublewrite。在InnoDB儲存引擎中doublewrite的體系架構如圖所示:
3.3 自適應雜湊索引
雜湊(hash)是一種非常快的查詢方法,在一般情況下這種查詢的時間複雜度為O(1),即一般僅需要一次查詢就能定位資料。 而B+樹的查詢次數,取決於B+樹的高度,在生產環境中,B+樹的高度一般為3~4層,所以需要3~4次的查詢。
InnoDB儲存引擎會監控對錶上各索引頁的查詢。如果觀察到建立雜湊索引可以帶來速度提升,則建立雜湊索引,稱之為自適應雜湊索引(Adaptive Hash Index, AHI)。AHI是通過緩衝池的B+樹頁構造而來,因此建立的速度很快,而且不需要對整張表構建雜湊索引。InnoDB儲存引擎會自動根據訪問的頻率和模式來自動地為某些熱點頁建立雜湊索引。
AHI有一個要求,對這個頁的連續訪問模式必須是一樣的。例如對於(a,b)這樣的聯合索引頁,其訪問模式可以是下面情況:
- where a=xxx
- where a =xxx and b=xxx
訪問模式一樣是指查詢的條件是一樣的,若交替進行上述兩種查詢,那麼InnoDB儲存引擎不會對該頁構造AHI。
AHI還有下面幾個要求:
- 以該模式訪問了100次
- 頁通過該模式訪問了N次,其中N=頁中記錄*1/16
InnoDB儲存引擎官方文件顯示,啟用AHI後,讀取和寫入速度可以提高2倍,輔助索引的連線操作效能可以提高5倍。AHI的設計思想是資料庫自優化,不需要DBA對資料庫進行手動調整。
3.4 非同步IO
- sync IO :同步IO 即每進行一次IO操作,此次操作結束才能繼續接下來的操作。 但是如果使用者發需要等待出一條索引掃描的查詢,那麼這條SQL查詢語句可能需要掃描多個索引頁,也就是需要進行多次的IO操作。在每掃描一個頁並等待期完成再進行下一次的掃描是沒有必要的。
- 非同步IO: 使用者可以在發出一個IO請求後立即再發出另一個IO請求,當全部IO請求傳送完畢後,等待所有IO操作的完成,這就是AIO。
AIO另一個優勢可以將多個IO,合併為1個IO,以提高IO效率。例如:使用者需要訪問3頁內容,但這3頁時連續的。同步IO需要進行3次IO,而AIO只需要一次 就可以了。
3.5 重新整理領接頁
當重新整理一個髒頁時,innodb會檢測該頁所在區(extent)的所有頁,如果是髒頁,那麼一起進行重新整理。這樣做,通過AIO將多個IO寫入操作合併為一個IO操作。在傳統機械磁碟下有著顯著優勢。