Hierarchical Clustering(層次聚類)
層次聚類原理:
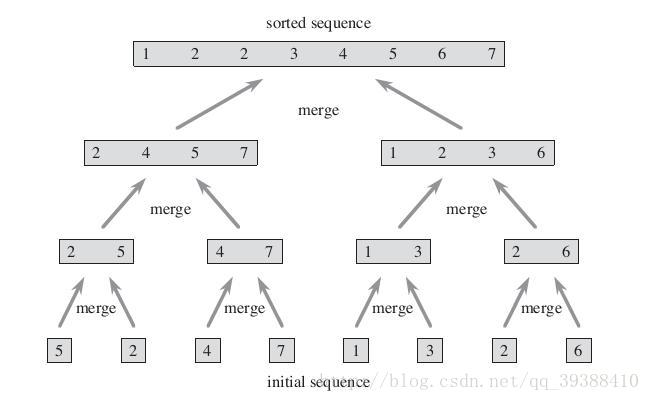
唔?排序的圖?分治?沒錯,與原型聚類和密度聚類不同,層次聚類試圖在不同的“層次”上對樣本資料集進行劃分,一層一層地進行聚類。就劃分策略可分為自底向上的凝聚方法(agglomerative hierarchical clustering),比如AGNES。自上向下的分裂方法(divisive hierarchical clustering),比如DIANA。
AGNES先將所有樣本的每個點都看成一個簇,然後找出距離最小的兩個簇進行合併,不斷重複到預期簇或者其他終止條件。
DIANA先將所有樣本當作一整個簇,然後找出簇中距離最遠的兩個簇進行分裂,不斷重複到預期簇或者其他終止條件。
如何判斷兩個cluster之間的距離呢?
1.最小距離,單鏈接Single Linkage
兩個簇的最近樣本決定。
2.最大距離,全連結Complete Linkage
兩個簇的最遠樣本決定。
3.平均距離,均連結Average Linkage
兩個簇所有樣本共同決定。
1和2都容易受極端值的影響,而3這種方法計算量比較大,不過這種度量方法更合理。
和決策樹相似,層次聚類的優點在於能一次性得到整棵樹,同控制某些條件不管是深度還是寬度都是可控的,但是它存在不少的問題:
計算量
劃分確定不可再作更改
凝聚和劃分相互組合!!
每次選擇“最優”
貪心演算法,容易區域性最優化,可以通過適當的隨機操作。
或者是採用平衡迭代規約和聚類(Balanced Iterative Reducing and Clustering Using Hierarchies,BIRCH
HC應用:
AgglomerativeClustering引數說明:
AgglomerativeClustering(affinity=’euclidean’, compute_full_tree=’auto’,connectivity=None, linkage=’ward’,memory=Memory(cachedir=None), n_clusters=6,pooling_func=)
affinity='euclidean':距離度量方式 connectivity:是否有連通性約束 linkage='ward':連結方式 memory:儲存方式 n_clusters=6:簇類數
import numpy as np
import matplotlib.pyplot as plt
import mpl_toolkits.mplot3d.axes3d as p3
from sklearn.cluster import AgglomerativeClustering
from sklearn.datasets.samples_generator import make_swiss_roll
n_samples = 1500
noise = 0.05
X, _ = make_swiss_roll(n_samples, noise)#卷型資料集
#進行放縮
X[:, 1] *= .5
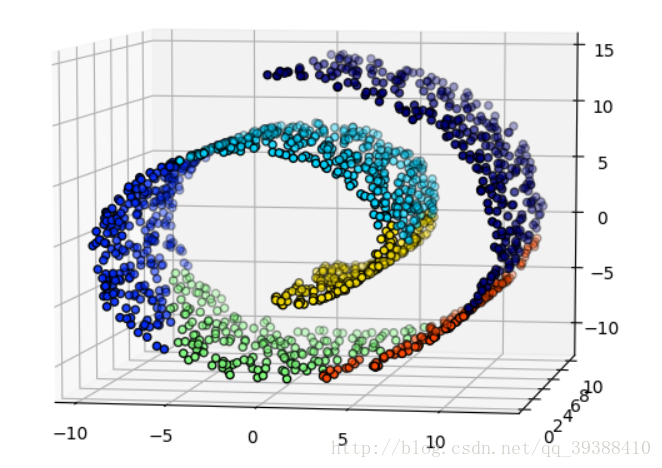
ward = AgglomerativeClustering(n_clusters=6, linkage='ward').fit(X)
label = ward.labels_#得到lable值
fig = plt.figure()
ax = p3.Axes3D(fig)
ax.view_init(7, -80)
for l in np.unique(label):
ax.scatter(X[label == l, 0], X[label == l, 1], X[label == l, 2],
color=plt.cm.jet(np.float(l) / np.max(label + 1)),
s=20, edgecolor='k')
plt.show()
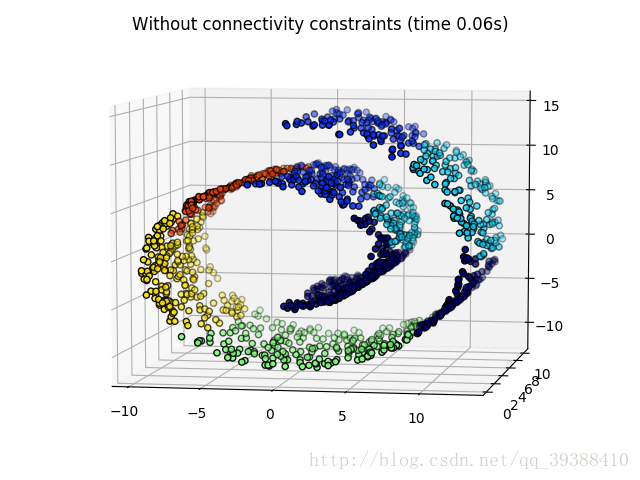
可見沒有連線性約束的忽視其資料本身的結構,於是形成了跨越流形的不同褶皺。
from sklearn.neighbors import kneighbors_graph
connectivity = kneighbors_graph(X, n_neighbors=10, include_self=False)
ward = AgglomerativeClustering(n_clusters=6, connectivity=connectivity,
linkage='ward').fit(X)修改部分程式碼後,新增connectivity便可以得到很好的結果。