
sklearn-1.1.10貝葉斯迴歸
1.1.10.貝葉斯迴歸
貝葉斯迴歸技術可以用在估計過程中包含正則引數:正則化引數並不是嚴格意義上的定義,而是根據當前的資料進行調整。
這些可以通過模型的超引數中引入無資訊的先驗完成。嶺迴歸中使用的

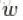
為了等到完整的全概率模型,假設

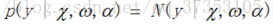
alpha再一次的被視為一個隨機變數,從資料中進行估計。
貝葉斯迴歸的優點:
*適用於當前的資料
*它可以被用來估計過程中包含的正則化引數
貝葉斯迴歸的缺點:
*模型的推測會消耗時間
參考
- A good introduction to Bayesian methods is given in C. Bishop: Pattern Recognition and Machine learning
- Original Algorithm is detailed in the book Bayesian learning for neural networks by Radford M. Nea
1.1.10.1貝葉斯的嶺迴歸
如上所述,貝葉斯的嶺迴歸估計概率模型,引數的先驗值是球面高斯給出的:

先驗
最終的模型被叫成貝葉斯嶺迴歸,它和嶺迴歸很像。它的引數
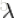

通過預設的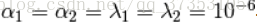
貝葉斯嶺迴歸用於迴歸:
from sklearn import linear_model X=[[0,0],[1,1],[2,2],[3,3]] Y=[0,1,2,3] reg=linear_model.BayesianRidge() print(reg.fit(X,Y))#BayesianRidge(alpha_1=1e-06, alpha_2=1e-06, compute_score=False, copy_X=True,fit_intercept=True, lambda_1=1e-06, lambda_2=1e-06, n_iter=300,normalize=False, tol=0.001, verbose=False)
擬合之後,該模型可以用來預測新值:
print(reg.predict([[1,0]]))#[0.50000013]這裡的權重
print(reg.coef_)#[0.49999993 0.49999993]由於貝葉斯框架,發現的權重與普通的最小二乘法找到的權重稍有不用,然而,貝葉斯嶺迴歸對於異常值問題更加的有效。
例子
貝葉斯迴歸模型計算合成數據集上的貝葉斯嶺迴歸
與最小二乘法相對,係數權重向零移動,從而是它們更加的穩定。
由於權重是高斯先驗,估計權重的直方圖也是高斯的。
通過迭代地最大化觀測的對數似然來完成模型的估計。
我們通常畫出預測使用多項特徵拓展進行一維迴歸的貝葉斯嶺迴歸的預測和不穩定性。請注意,右側會出現不確定性。這時因為這些測試樣本超出了訓練樣本的範圍。(上面的標題就是程式碼的連結)
參考
更多的細節可以在MacKay的文章中找到
1.1.1.10.2自動相關性確定-ARD
AED迴歸與貝葉斯嶺迴歸非常相似,但是會導致更稀疏的權重
相反,假設分佈是一個軸平行的橢圓高斯分佈。
這意味著每一個權重都是從高斯分佈中繪製的,以零為中心並具有精度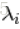
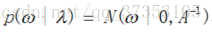
以及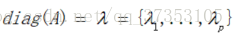
與貝葉斯零迴歸相比,每一個座標

ARD在文獻中也被稱為貝葉斯學習和相關向量。
例子
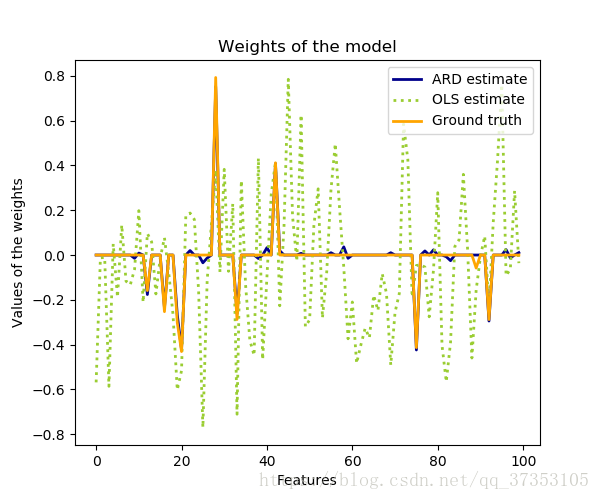
自動相關性確定迴歸(和之前的嶺迴歸幾乎是一樣的,只是在建立模型的時候選擇的是ARD)
用貝葉斯零迴歸擬合迴歸模型
與最小二乘比奧,係數權重向零移動,從而使它們更加的穩定。
估計權重直方圖非常的尖銳,暗示 權重先驗的稀疏性。
通過迭代地最大似然對數來完成模型的估計
我們還是繪製使用多項式特徵拓展進行一維迴歸的ARD預測和不穩定性。請注意,右側會出現不確定性,這時因為這些測試樣本超出了訓練樣本的範圍。(標題就是程式碼的連結)
參考
| [1] | Christopher M. Bishop: Pattern Recognition and Machine Learning, Chapter 7.2.1 |