
mahout之旅---分散式推薦演算法ALS-MR
Mahout分散式推薦系統——基於矩陣分解的協同過濾系統
1.例項環境
Mahout版本:mahout-0.9;
Hadoop版本:hadoop-1.2.1;
Jdk版本:java1.7.0_13
分散式系統:centos;
叢集規模:master 、slavex、slavey、slavez
2.例項指令碼
目前技術博文對mahout0.9版本的簡介的也是不忍直視。這裡系列部落格對mahout0.9版本自帶的基於矩陣分解的協同過濾系統演算法的講解。一個首先不管怎麼樣,先把程式跑起來,mahout自帶了本例執行的指令碼(factorize-movielens-1M.sh)核心內容分為五個部分操作。如下:
|
#1.把原始資料轉換成所需格式,注意在此之前還有一步就是上傳原始資料到/user/yxb/mhadoop/data資料夾下。 原始資料格式如下,其結構為UserID::MovieID::Rating::Timestamp 1::1193::5::978300760 1::661::3::978302109 1::914::3::978301968 1::3408::4::978300275 1::2355::5::978824291 1::1197::3::978302268 1::1287::5::978302039 1::2804::5::978300719 1::594::4::978302268 1::919::4::978301368 cat /user/yxb/mhadoop/data/ratings.dat |sed -e s/::/,/g| cut -d, -f1,2,3 > /user/yxb/mhadoop/data/ratings.csv 經轉換後的資料格式如下。其結構為UserID,MovieID,Rating。 1,1193,5 1,661,3 1,914,3 1,3408,4 1,2355,5 1,1197,3 1,1287,5 1,2804,5 1,594,4 1,919,4 #2.將資料集分成訓練資料和測試資料:基本原理就是mapper函式產生合適的key值進行資料分裂。測試集(10%)和訓練集(90%) mahout splitDataset -i /user/yxb/mhadoop/input/ratings.csv -o /user/yxb/mhadoop/dataset –t 0.9 –p 0.1 #3.並行ALS,進行矩陣分解 # run distributed ALS-WR to factorize the rating matrix defined by the training set mahout parallelALS -i /user/yxb/mhadoop/dataset/trainingSet/ -o /user/yxb/mhadoop/out --numFeatures 20 --numIterations 10 --lambda 0.065 #4.評價演算法模型:使用的mahout命令是evaluateFactorization。可以在HDFS的output/rmse/rmse.txt檔案中檢視到均方根誤差為:0.8548619405669956 # compute predictions against the probe set, measure the error mahout evaluateFactorization -i /user/yxb/mhadoop/dataset/probeSet/ -o /user/yxb/mhadoop/out/rmse/ --userFeatures /user/yxb/mhadoop/out/U/ --itemFeatures /user/yxb/mhadoop/out/M/ #5.推薦。為目標使用者最多推薦6部電影 # compute recommendations mahout recommendfactorized -i /user/yxb/mhadoop/out/userRatings/ -o /user/yxb/mhadoop/recommendations/ --userFeatures /user/yxb/mhadoop/out/U/ --itemFeatures /user/yxb/mhadoop/out/M/ --numRecommendations 6 --maxRating 5 |
最終的推薦結果在/user/yxb/mhadoop/recommendations下:

原始碼分析
SplitDataset
其中splitDataset對應的mahout中的源java檔案是:org.apache.mahout.cf.taste.
hadoop.als.DatasetSplitter.java 檔案,開啟這個檔案,可以看到這個類是繼承了AbstractJob的,所以需要覆寫其run方法。run方法中含有所有的操作。Run方法裡面有3個job。
|
//資料集隨機分裂(90%的訓練集,10%的測試集) Job markPreferences = prepareJob(getInputPath(), markedPrefs, TextInputFormat.class,MarkPreferencesMapper.class,Text.class, Text.class, SequenceFileOutputFormat.class); //建立訓練集 Job createTrainingSet = prepareJob(markedPrefs, trainingSetPath, SequenceFileInputFo rmat.class,WritePrefsMapper.class, NullWritable.class, Text.class, TextOutputFormat.class); //建立測試集 Job createProbeSet = prepareJob(markedPrefs, probeSetPath, SequenceFileInputFormat.class,WritePrefsMapper.class, NullWritable.class, Text.class, TextOutputFormat.class); |
Ø 第一個job
分裂資料集,job任務沒有reducer,只有一個mapper,跟蹤mapper就知道隨機分裂的過程。其一是setup,其二是map。Setup通過random產生集合分佈的[0,1]的隨機數,因此通過控制閾值就可以將資料分成9:1,訓練集邊界trainingBound=0.9,randomValue<0.9時,打上T的標籤作為key值,如此產生的90%的資料集就是訓練集,剩下的打上P的標籤作為測試資料集。
|
private Random random; private double trainingBound; private doubleprobeBound; protected void setup(Context ctx) throws IOException, InterruptedException { random = RandomUtils.getRandom(); trainingBound = Double.parseDouble(ctx.getConfiguration().get( TRAINING_PERCENTAGE)); probeBound = trainingBound + Double.parseDouble(ctx.getConfiguration().get( PROBE_PERCENTAGE)); } @Override protected void map(LongWritable key, Text text, Context ctx) throws IOException, InterruptedException { double randomValue = random.nextDouble(); // trainingBound=0.9 probeBound=1.0 if (randomValue <= trainingBound) { ctx.write(INTO_TRAINING_SET, text); // T } else { ctx.write(INTO_PROBE_SET, text); // P } } |
Ø 第二個job
第二、三個任務,比較這兩個任務,可以看到它們的不同之處只是在輸入路徑和輸出路徑,以及一些引數不同而已。而且也只是使用mapper,並沒有使用reducer,那麼開啟WritePrefsMapper來看,這個mapper同樣含有setup和map函式,setup函式則主要是獲取是對T還是對P來進行處理。(任務2是建立訓練集,因此標籤是T)。
|
private String partToUse; @Override protected void setup(Context ctx) throws IOException, InterruptedException { partToUse = ctx.getConfiguration().get(PART_TO_USE); // partToUse=T } @Override protected void map(Text key, Text text,Context ctx) throws IOException, InterruptedException { if (partToUse.equals(key.toString())) { ctx.write(NullWritable.get(), text); } } |
Ø 第三個job(同上)
parallelALS
parallelALS對應的原始檔是:org.apache.mahout.cf.taste.hadoop.als.ParallelA
LSFactorizationJob.java檔案。Run方法裡面的準備工作主要包括三個job,分別是itemRatings Job、userRatings Job和averageRatings Job。
首先來分析itemRatings Job,呼叫的語句分別是:
|
Job itemRatings = prepareJob(getInputPath(), pathToItemRatings(), TextInputFormat.class, ItemRatingVectorsMapper.class, IntWritable.class, VectorWritable.class, VectorSumReducer.class,IntWritable.class, VectorWritable.class, SequenceFileOutputFormat.class); itemRatings.setCombinerClass(VectorSumCombiner.class); itemRatings.getConfiguration().set(USES_LONG_IDS, String.valueOf(usesLongIDs)); boolean succeeded = itemRatings.waitForCompletion(true); if (!succeeded) { return -1; } |
可以看出該job主要有一個mapper(ItemRatingVectorsMapper.class)和一個reducer(VectorSumReducer.class)構成。先來看看mapper類吧。
Mapper類的裡面的map函式:提取使用者ID和物品ID以及相應打分。
|
protected void map(LongWritable offset, Text line, Context ctx) throws IOException, InterruptedException { String[] tokens = TasteHadoopUtils.splitPrefTokens(line.toString()); int userID = TasteHadoopUtils.readID(tokens[TasteHadoopUtils.USER_ID_POS], usesLongIDs); // userID int itemID = TasteHadoopUtils.readID(tokens[TasteHadoopUtils.ITEM_ID_POS], usesLongIDs); // itemID float rating = Float.parseFloat(tokens[2]); // rating ratings.setQuick(userID, rating); itemIDWritable.set(itemID); ratingsWritable.set(ratings); // String key=String.valueOf(itemID); // String sum = String.valueOf(ratings); // sysoutt(logpath+"log.txt", key,sum); ctx.write(itemIDWritable, ratingsWritable); // prepare instance for reuse ratings.setQuick(userID, 0.0d); } |
最後操作輸出<key,value>對應為 itemID, [userID:rating]這樣的輸出,然後到reducer,即VectorSumReducer,這個reducer中也只有一個reduce函式:
|
protected void reduce(WritableComparable<?> key, Iterable<VectorWritable> values, Context ctx) throws IOException, InterruptedException { Vector sum = Vectors.sum(values.iterator()); result.set(new SequentialAccessSparseVector(sum)); ctx.write(key, result); } |
以《mahout實戰》示例來說,這個job完成的就是如下所示:

接下來就是userRatings Job
|
Job userRatings = prepareJob(pathToItemRatings(), pathToUserRatings(), TransposeMapper.class, IntWritable.class, VectorWritable.class, MergeUserVectorsReducer.class, IntWritable.class, VectorWritable.class); userRatings.setCombinerClass(MergeVectorsCombiner.class); succeeded = userRatings.waitForCompletion(true); if (!succeeded) { return -1; } |
他和itemRatings job工作方式差不多,經過mapreduce之後得到的示例效果就是:

準備工作的最後一個job,這個很重要,因為要用這個結果去構成一次迭代的M矩陣。這個就是averageItemRatingsjob,他是對itemRatings的每一個key對應的value值求平均值。
|
Job averageItemRatings = prepareJob(pathToItemRatings(), getTempPath("averageRatings"), AverageRatingMapper.class, IntWritable.class, VectorWritable.class, MergeVectorsReducer.class, IntWritable.class, VectorWritable.class); averageItemRatings.setCombinerClass(MergeVectorsCombiner.class); succeeded = averageItemRatings.waitForCompletion(true); if (!succeeded) { return -1; } |
具體的mapreduce程式碼自行去檢視吧,最後的效果如下:
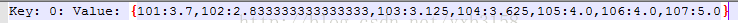
接下里才是演算法的開始。初始化M和for迴圈的交替迭代。M代表物品特徵矩陣,U代表使用者特徵矩陣。For迴圈裡面包含連個job,其功能就是通過固定的M求逼近的U,然後又通過這個U去求M,如此迴圈下去。最後滿足for條件就退出。
接下來具體談談演算法的實現過程:
初始化的M的核心程式碼就下面一點,如果你的java程式碼閱讀功底還好的話應該就能看懂下面一段程式碼。初次形成的檔案是M—1的檔案。
|
Vector row = new DenseVector(numFeatures); row.setQuick(0, e.get()); for (int m = 1; m < numFeatures; m++) { row.setQuick(m, random.nextDouble()); } index.set(e.index()); featureVector.set(row); writer.append(index, featureVector); |
看不懂也沒關係,先貼出M—1的內容,估計就明白了。

是的,就是把averageRatings的內容作為第一列,然後用random函式生成(numFeatures-1)列的[0,1]隨機數。簡單吧!
接下來就是通過初始化的M求出U了,於是就進入了for迴圈,程式碼我看的吐了好幾天了,再貼程式碼我又要吐了。這個演算法不像網上說的那樣什麼QR分解。SVD演算法是基於奇異值分解的演算法。參考文獻3裡面就指出ASL演算法比SVD演算法更適合稀疏矩陣。
下面先通過一個示例來領略一下ALS的魅力所在吧。如下圖,先隨機初始化一個V,然後通過V求U,為了方便理解U也先給了一個初始化的值。這樣不靠譜的做法,你會發現與真實的稀疏矩陣之間還是存在很大的差距。
當然會存在很大的差距,如果也能得到很小的rmse的話,那你可以去買彩票了。好了閒話不扯了,所以還是得求出U比較靠譜。演算法的核心就是求出UV使得最大限度的逼近R,那麼就好說了,就是求最小二乘解(做資料分析,矩陣論一定要學好,不然像我這樣的學渣就痛苦了)。不好意思字差了一點,本人喜歡在紙上打草稿的形式推導公式。
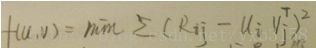
通過一些推導就得到如下式:

如果不嫌字醜的話,這個推導式在後面還有。反正不管怎樣通過上面一個這樣的式子能夠使預測矩陣與真實稀疏矩陣更接近,如下圖求出V。
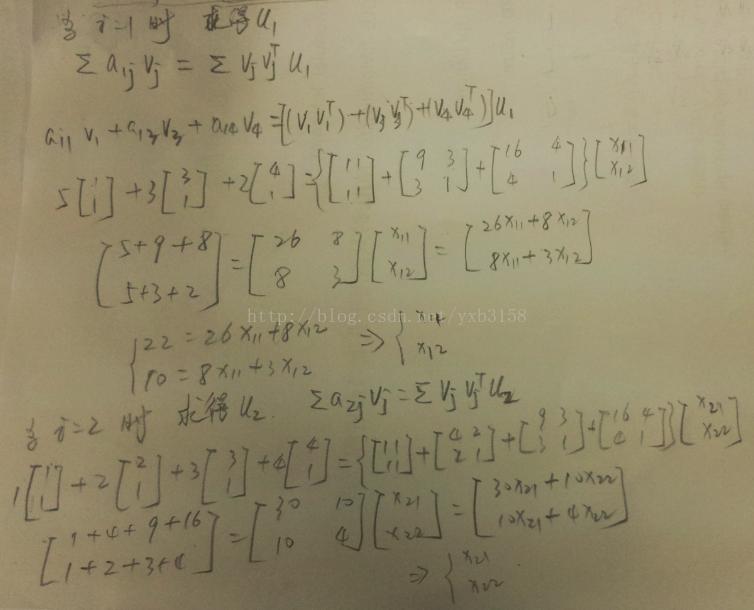
如果上圖看懂了的話,那麼這個演算法你也基本上入門了。下面是一些原理性的數學公式。

這樣求得的U是不是比隨機取的要合理一點,但是追求完美的我們還是對結果不滿意。那我們再固定U用同樣的方法求M吧。現在問題來了,你會發現求出的M值沒變。
接下來是演算法昇華的地方,ALS-WR演算法全稱是基於正則化的交替最小二乘法協同過濾演算法。是不是一下豁達了,我們還有正則化沒有考慮。上面的問題就是擬合不足造成的誤差。如下圖就是新增正則化後的修正函式。這裡不再推導了,因為文獻3已經做了這一步工作(字也比這個好看)。

如果你已經頭大了的話,那就通過上面的示例來理解這個結論吧。
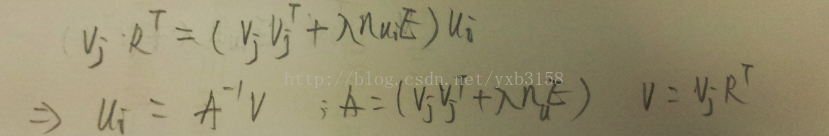
到這裡paralleALS也基本上結束了。For迴圈裡面有兩個結構相同的job,那就是通過固定的M求U,然後又通過U來求更逼近的M。如果這裡理解了是不是可以自己把程式碼寫出來呢?
說實在的我對這個高大上的演算法也是醉了,很好理解。但是很難實現,查看了很多技術部落格基本上都是fansy1990的博文轉載,並且裡面對演算法的講解也是有迷惑性的,不過還是要特別感謝fansy1990,他的總體框架相當好,有大局觀,給了我相當大的啟發。基於此,痛苦了幾天終於把它搞明白了。並且借鑑《網際網路大規模資料探勘與分散式處理》書裡的方法寫了一個示例來加深對演算法的理解。
evaluator
好了,你說你已經得到了一對最逼近的使用者特徵矩陣U和物品特徵矩陣M,那麼到底有多接近呢?這個需要對演算法進行評價。評估結果當然還是rmse(均方根誤差)。在mahout中評價的檔案是org.apache.mahout.cf.taste.hadoop.als.FactorizationEvaluator,檔案中run方法只有一個predictRatings函式。
|
Job predictRatings = prepareJob(getInputPath(), errors,TextInputFormat.class, PredictRatingsMapper.class,DoubleWritable.class, NullWritable.class, SequenceFileOutputFormat.class); |
Job裡面只有一個map類,PredictRatingsMapper.class。PredictRatingsMapper可以看到它有setup和map函式,setup函式主要是把路徑U和M中的資料load到一個變數裡面,map的核心原始碼如下(矩陣的乘積):
|
if (U.containsKey(userID) && M.containsKey(itemID)) { double estimate = U.get(userID).dot(M.get(itemID)); error.set(rating - estimate); ctx.write(error, NullWritable.get()); } |
Recommender
最後來到推薦部分,推薦使用的原始碼是在:org.apache.mahout.cf.taste.hadoop.als.RecommenderJob
run方法下只有一個prepareJob的job,裡面包含mapper(MultithreadedSharingMapper.class)類。核心程式碼如下。
|
public class PredictionMapper extends SharingMapper<IntWritable,VectorWritable,LongWritable,RecommendedItemsWritable, Pair<OpenIntObjectHashMap<Vector>,OpenIntObjectHashMap<Vector>>> { private int recommendationsPerUser; private float maxRating; private boolean usesLongIDs; private OpenIntLongHashMap userIDIndex; private OpenIntLongHashMap itemIDIndex; private final LongWritable userIDWritable = new LongWritable(); private final RecommendedItemsWritable recommendations = new RecommendedItemsWritable(); @Override Pair<OpenIntObjectHashMap<Vector>,OpenIntObjectHashMap<Vector>> createSharedInstance(Context ctx) { Configuration conf = ctx.getConfiguration(); Path pathToU = new Path(conf.get(RecommenderJob.USER_FEATURES_PATH)); Path pathToM = new Path(conf.get(RecommenderJob.ITEM_FEATURES_PATH)); OpenIntObjectHashMap<Vector> U = ALS.readMatrixByRows(pathToU, conf); OpenIntObjectHashMap<Vector> M = ALS.readMatrixByRows(pathToM, conf); return new Pair<OpenIntObjectHashMap<Vector>,OpenIntObjectHashMap<Vector>>(U, M); } @Override protected void setup(Context ctx) throws IOException, InterruptedException { Configuration conf = ctx.getConfiguration(); recommendationsPerUser = conf.getInt(RecommenderJob.NUM_RECOMMENDATIONS, RecommenderJob.DEFAULT_NUM_RECOMMENDATIONS); maxRating = Float.parseFloat(conf.get(RecommenderJob.MAX_RATING)); usesLongIDs = conf.getBoolean(ParallelALSFactorizationJob.USES_LONG_IDS, false); if (usesLongIDs) { userIDIndex = TasteHadoopUtils.readIDIndexMap(conf.get(RecommenderJob.USER_INDEX_PATH), conf); itemIDIndex = TasteHadoopUtils.readIDIndexMap(conf.get(RecommenderJob.ITEM_INDEX_PATH), conf); } } @Override protected void map(IntWritable userIndexWritable, VectorWritable ratingsWritable, Context ctx) throws IOException, InterruptedException { Pair<OpenIntObjectHashMap<Vector>,OpenIntObjectHashMap<Vector>> uAndM = getSharedInstance(); OpenIntObjectHashMap<Vector> U = uAndM.getFirst(); OpenIntObjectHashMap<Vector> M = uAndM.getSecond(); Vector ratings = ratingsWritable.get(); int userIndex = userIndexWritable.get(); final OpenIntHashSet alreadyRatedItems = new OpenIntHashSet(ratings.getNumNondefaultElements()); for (Vector.Element e : ratings.nonZeroes()) { alreadyRatedItems.add(e.index()); } final TopItemsQueue topItemsQueue = new TopItemsQueue(recommendationsPerUser); final Vector userFeatures = U.get(userIndex); M.forEachPair(new IntObjectProcedure<Vector>() { @Override public boolean apply(int itemID, Vector itemFeatures) { if (!alreadyRatedItems.contains(itemID)) { double predictedRating = userFeatures.dot(itemFeatures); MutableRecommendedItem top = topItemsQueue.top(); if (predictedRating > top.getValue()) { top.set(itemID, (float) predictedRating); topItemsQueue.updateTop(); } } return true; } }); List<RecommendedItem> recommendedItems = topItemsQueue.getTopItems(); if (!recommendedItems.isEmpty()) { // cap predictions to maxRating for (RecommendedItem topItem : recommendedItems) { ((MutableRecommendedItem) topItem).capToMaxValue(maxRating); } if (usesLongIDs) { long userID = userIDIndex.get(userIndex); userIDWritable.set(userID); for (RecommendedItem topItem : recommendedItems) { // remap item IDs long itemID = itemIDIndex.get((int) topItem.getItemID()); ((MutableRecommendedItem) topItem).setItemID(itemID); } } else { userIDWritable.set(userIndex); } recommendations.set(recommendedItems); ctx.write(userIDWritable, recommendations); } } |
你不是很吝嗇的貼程式碼嗎?為什麼現在貼這多,對,因為我也不想去分析了,頭大了。。
參考文獻
3.http://m.blog.csdn.net/blog/ddjj131313/12586209