
資料結構與演算法分析 - 1 - 連結串列ADT
阿新 • • 發佈:2018-12-29
1.描述:不連續儲存的表,可以把連結串列看成一個數組,陣列元素是一個個結構體,這些結構體之間通過指標連線

2.優點:
利用不連續的儲存空間,提高記憶體使用效率
避免刪除和插入的線性開銷
對比陣列,大小不固定,可以擴充套件
3. 缺點:查詢效率低
4. 定義一個單向連結串列
1 struct Node 2 { 3 ElementType value; 4 Node *next; //next指標,指向下一個節點 5 };
5.檢測連結串列是否為空
對於一個單向連結串列,連結串列為空即頭節點為空
1 int IsEmpty(Node *head) //將連結串列傳入函式,傳入頭指標即可 2 { 3 return head->next == NULL; //若為空編譯器將提示異常 4 }
6.測試當前位置是否為連結串列末尾
1 int IsLast(Node *Pos) 2 { 3 return Pos->next == NULL; 4 }
7.遍歷並列印連結串列
1 void Print(Node *head) 2 { 3 Node *p = head; //類似範圍for迴圈4 while (p != NULL) 5 { 6 cout << p->value << " "; 7 p = p->next; 8 } 9 cout << endl; 10 }
8.檢索連結串列,找出匹配的節點
1 Node* Find(ElementType x, Node *head) 2 { 3 Node *Pos; 4 Pos = head->next; 5 while (Pos != NULL && Pos->value != x)6 Pos = Pos->next; 7 8 return Pos; 9 }
9.檢索匹配節點的前驅元
1 Node* FindPrevious(ElementType x, Node *head) 2 { 3 Node *Pos; 4 Pos = head; 5 while (Pos->next != NULL && Pos->next->value != x) 6 Pos = Pos->next; 7 8 return Pos; 9 }
10.刪除節點
1 void Delete(ElementType x, Node *head) 2 { 3 Node *Pos, *temp; 4 Pos = FindPrevious(x, head); //對於單向連結串列來說,獲取前驅元需要額外遍歷一次,這裡使用上面編寫的(9)FindPrevious函式 5 if (!IsLast(Pos)) //(6)測試是否為連結串列末尾 6 { 7 temp = Pos->next; 8 Pos->next = temp->next; 9 //free(temp); //C語言釋放記憶體 10 delete temp; 11 } 12 }
11.在連結串列任意位置插入節點
注意,如果當前連結串列為空,則需要先手動新建頭節點
1 void Insert(ElementType x, Node *head, Node *Pos) 2 { 3 Node *temp = new Node; 4 temp->value = x; 5 temp->next = Pos->next; 6 Pos->next = temp; 7 }
12.刪除連結串列
1 void DeleteNode(Node *head) 2 { 3 Node *Pos, *temp; //用臨時變數temp儲存被刪除前的Pos 4 Pos = head->next; 5 head->next = NULL; 6 while (Pos != NULL) 7 { 8 temp = Pos->next; 9 delete Pos; 10 Pos = temp; 11 } 12 }
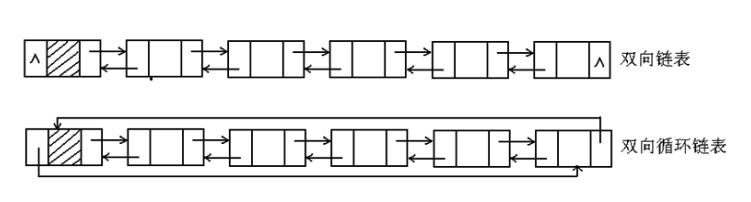
13.雙向連結串列
1 struct Node 2 { 3 int value; 4 Node *next; 5 Node *pre; //新增一個pre指標指向上一個節點 6 };
14.迴圈連結串列
可以有表頭,也可以沒有表頭
若有表頭,則最後一個節點的next指向表頭
迴圈連結串列可以與雙向連結串列結合使用
15.連結串列的遊標實現(freelist)
全域性的結構體陣列,用陣列下標來代表地址
挖坑待填
參考資料:《資料結構與演算法分析——C語言描述》 Mark Allen Weiss