
[Erlang 0124] Erlang Unicode 兩三事
最近看了Erlang User Conference 2013上patrik分享的BRING UNICODE TO ERLANG!視訊,這個分享很好的梳理了Erlang Unicode相關的問題,基本上把 Using Unicode in Erlang 講解了一遍.再次學習了一下,整理成文字,補充一些 [Erlang 0062] Erlang Unicode 兩三事 遺漏掉的內容.
演變
Erlang對Unicode的支援受到環境變數和OTP版本的影響,多數時候影響的是Unicode data如何顯示,下面是各個版本的OTP對Unicode支援的演變情況簡介: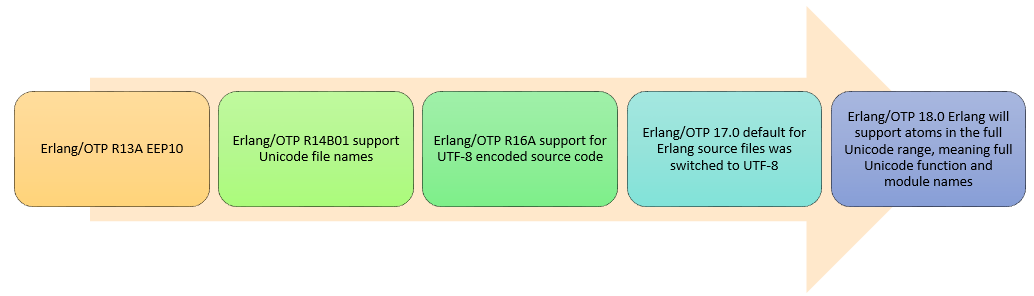
問題域
我們梳理一下,Erlang Unicode的問題域包含哪些具體的細節:
Erlang Shell
Erlang Shell中是否可以輸入中文
Erlang Shell中是否可以顯示中文
Erlang Code
程式碼檔案的編碼方式
Files
檔名如何解析

下面我們逐一擊破:
Erlang Shell中是否可以輸入中文
LANG and LC_CTYPE環境變數影響Erlang Shell,告訴終端程式是否要處理unicode,(此環境變數還會影響檔名的解析,OTP17.0預設會使用+fna,稍後會提到),檢查這個引數可以使用io:getopts().可以輸出一下 echo $LANG 和 echo $LC_CTYPE看一下,比如在我的centos機器上,環境變數是# echo $LANG en_US.UTF-8
LC_CTYPE=en_US.ISO-8859-1 /usr/local/bin/erl嘗試輸入一下中文,看看情況以後多怪異.遇到這種情況怎麼破?io:setopts([{encoding,unicode}]). 即可,下面的測試一開始使用latin引數啟動,嘗試輸入中文"我們"雖然顯示的List是正確的[230,136,145,228,187,172].但是字元顯示是錯的.然後通過setopts設定encoding為unicode解決此問題.
LC_CTYPE=en_US.ISO-8859-1 /usr/local/bin/erl
Erlang R16B02 (erts-5.10.3) [source] [64-bit] [smp:2:2] [async-threads:10] [hipe] [kernel-poll:false]
Eshell V5.10.3 (abort with ^G)
1> io:getopts().
[{expand_fun,#Fun<group.0.56199974>},
{echo,true},
{binary,false},
{encoding,latin1}]
2> "210\221[C.
[230,136,145,228,187,172]
3> io:setopts([{encoding,unicode}]).
ok
4>
4> "我們".
[25105,20204]
5>
Erlang/OTP 17 [erts-6.0] [source] [64-bit] [smp:4:4] [async-threads:10] [hipe] [kernel-poll:false]
Eshell V6.0 (abort with ^G)
1> "我們".
"我們"
2> io:format("~tp",[v(1)]).
"我們"ok
4> io:format("~ts",[v(1)]).
我們ok
5> io:format("~ts",[lists:seq(20204,20220)]).
們仭仮仯仰仱仲仳仴仵件價仸仹仺任仼ok
6> io:format("~ts",[lists:seq(20204,20290)]).
們仭仮仯仰仱仲仳仴仵件價仸仹仺任仼份仾仿伀企伂伃伄伅伆伇伈伉伊伋伌伍伎伏伐休伒伓伔伕伖眾優夥會傴伜伝傘偉傳俥伢俔傷倀倫傖伨伩偽佇伬伭伮伯估伱伲伳伴伵伶伷伸伹伺伻似伽伾伿佀佁佂ok
7> io:getopts().
[{expand_fun,#Fun<group.0.100149429>},
{echo,true},
{binary,false},
{encoding,unicode}]
8> io:setopts([{encoding,latin1}]).
ok
9> io:format("~ts",[lists:seq(20204,20290)]).
\x{4EEC}\x{4EED}\x{4EEE}\x{4EEF}\x{4EF0}\x{4EF1}\x{4EF2}\x{4EF3}\x{4EF4}\x{4EF5}\x{4EF6}\x{4EF7}\x{4EF8}\x{4EF9}\x{4EFA}\x{4EFB}\x{4EFC}\x{4EFD}\x{4EFE}\x{4EFF}\x{4F00}\x{4F01}\x{4F02}\x{4F03}\x{4F04}\x{4F05}\x{4F06}\x{4F07}\x{4F08}\x{4F09}\x{4F0A}\x{4F0B}\x{4F0C}\x{4F0D}\x{4F0E}\x{4F0F}\x{4F10}\x{4F11}\x{4F12}\x{4F13}\x{4F14}\x{4F15}\x{4F16}\x{4F17}\x{4F18}\x{4F19}\x{4F1A}\x{4F1B}\x{4F1C}\x{4F1D}\x{4F1E}\x{4F1F}\x{4F20}\x{4F21}\x{4F22}\x{4F23}\x{4F24}\x{4F25}\x{4F26}\x{4F27}\x{4F28}\x{4F29}\x{4F2A}\x{4F2B}\x{4F2C}\x{4F2D}\x{4F2E}\x{4F2F}\x{4F30}\x{4F31}\x{4F32}\x{4F33}\x{4F34}\x{4F35}\x{4F36}\x{4F37}\x{4F38}\x{4F39}\x{4F3A}\x{4F3B}\x{4F3C}\x{4F3D}\x{4F3E}\x{4F3F}\x{4F40}\x{4F41}\x{4F42}ok
10> io:format("~ts",[v(1)]).
\x{6211}\x{4EEC}ok
11> io:setopts([{encoding,unicode}]).
ok
12> io:format("~ts",[v(1)]).
我們ok
13> io:format("~ts",[lists:seq(20204,20290)]).
們仭仮仯仰仱仲仳仴仵件價仸仹仺任仼份仾仿伀企伂伃伄伅伆伇伈伉伊伋伌伍伎伏伐休伒伓伔伕伖眾優夥會傴伜伝傘偉傳俥伢俔傷倀倫傖伨伩偽佇伬伭伮伯估伱伲伳伴伵伶伷伸伹伺伻似伽伾伿佀佁佂ok
14>
Erlang Shell中是否可以顯示中文
之前提到過的Erlang Shell 中顯示文字常量的各種奇怪,其實源於字串啟發式檢測機制("Heuristic String Detection"),簡單講就是Erlang Shell會檢測List,Binary裡面的資料是否可以有可列印的字元,比如下面的二進位制串<<230,136,145,228,187,172,229,173,166,228,185,160>>.就被認為檢測到可列印的,就輸出了<<"我們學習"/utf8>>.
還記得那個輸出資料的技巧嗎?輸出的資料內容被Shell自作聰明的列印成了字元,怎麼解決的呢?在資料尾部追加一個0,比如[25105].會打印出來"我",[25105,0]就原樣輸出了.這個技巧實際上是通過加0避開了"Heuristic String Detection"機制.做下面的實驗需要注意的一點是啟動erl的引數:
erl +pc unicode
+pc 這個選項的作用就是選擇Shell可列印字元的範圍,可以是erl +pc latin1 或者 erl +pc unicode,在緊接著的實驗裡面,[25105]被如實顯示並沒有被解析顯示成"我".
預設情況下,erl啟動引數是latin
# erl +pc unicode Erlang/OTP 17 [erts-6.0] [source] [64-bit] [smp:2:2] [async-threads:10] [hipe] [kernel-poll:false] Eshell V6.0 (abort with ^G) 1> <<230,136,145,228,187,172,229,173,166,228,185,160>>. <<"我們學習"/utf8>> 2> <<230,136,145,228,187,172,229,173,166,228,185,160,69,114,108,97,110,103>>. <<"我們學習Erlang"/utf8>> 3> $我. 25105 4> <<230,136,145,228,187,172,229,173,166,228,185,160,69,114,108,97,110,103,0>>. <<230,136,145,228,187,172,229,173,166,228,185,160,69,114, 108,97,110,103,0>> 5> [25105]. "我" 6> [25105,0]. [25105,0]
# erl Erlang/OTP 17 [erts-6.0] [source] [64-bit] [smp:2:2] [async-threads:10] [hipe] [kernel-poll:false] Eshell V6.0 (abort with ^G) 1> $我. 25105 2> [25105]. [25105] 3>
io:printable_range/0 和 io_lib:printable_list/1這兩個函式可以幫助我們檢查當前shell的可列印字元的範圍,判斷一個List是否屬於可列印的.看下面的例子:
erl +pc unicode Erlang/OTP 17 [erts-6.0] [source] [64-bit] [smp:2:2] [async-threads:10] [hipe] [kernel-poll:false] Eshell V6.0 (abort with ^G) 1> io_lib:printable_list([25105,20204]). true 2> [25105,20204]. "我們" 3> io:printable_range(). unicode 4>
erl Erlang/OTP 17 [erts-6.0] [source] [64-bit] [smp:2:2] [async-threads:10] [hipe] [kernel-poll:false] Eshell V6.0 (abort with ^G) 1> io_lib:printable_list([25105,20204]). false 2> [25105,20204]. [25105,20204] 3> io:printable_range(). latin1 4>
這個啟發機制(heuristics)同樣被io(_lib):format/2使用,~tp會受到+pc引數的影響,~ts不會.
# erl +pc unicode
7> io:format("~ts",[[25105]]).
我ok
8> io:format("~tp",[[25105]]).
"我"ok
9>
# erl +pc latin1
3> io:format("~ts",[[25105]]).
我ok
4> io:format("~tp",[[25105]]).
[25105]ok
5>
程式碼檔案的編碼方式
Erlang原始碼進行編譯的時候,如果檔案添加了註釋頭自然好辦,如果沒有就會按照預設的編碼方式解析檔案,epp:default_encoding/0返回的就是當前OTP版本使用的預設編碼方式.R16B是 latin1, 17.0是utf8.-module(coding). -compile(export_all). a()-> "我們學習Erlang".
Erlang/OTP 17 [erts-6.0] [source] [64-bit] [smp:2:2] [async-threads:10] [hipe] [kernel-poll:false]
Eshell V6.0 (abort with ^G)
1> coding:a().
[25105,20204,23398,20064,69,114,108,97,110,103]
2> io:format("~ts",[v(1)]).
我們學習Erlangok
3> q().
ok
4>
在R16B程式碼檔案的預設編碼還是latin,所以下面的程式碼在R16B中輸出是這樣的:
Erlang R16B02 (erts-5.10.3) [source] [64-bit] [smp:2:2] [async-threads:10] [hipe] [kernel-poll:false]
Eshell V5.10.3 (abort with ^G)
1> coding:a().
[230,136,145,228,187,172,229,173,166,228,185,160,69,114,108,
97,110,103]
2> io:format("~ts",[v(1)]).
æ们å¦ä¹ Erlangok
3>
還是在R16所在的機器上,我們修改一下程式碼,新增宣告檔案編碼的註釋頭
%% -*- coding: utf-8 -*- -module(coding). -compile(export_all). a()-> "我們學習Erlang".如果要顯示指定檔案是latin編碼,可以添加註釋頭 %% -*- coding: latin-1 -*- ,參考這裡[連結].
下面我們在之前的測試程式碼檔案中新增一個方法,返回一個二進位制序列:
b()-> <<"我們學習Erlang">>.
# /usr/local/bin/erl
Erlang R16B02 (erts-5.10.3) [source] [64-bit] [smp:2:2] [async-threads:10] [hipe] [kernel-poll:false]
Eshell V5.10.3 (abort with ^G)
1> coding:b().
<<17,236,102,96,69,114,108,97,110,103>>
2> io:format("~ts",[v(1)]).
^Qìf`Erlangok
3> q().
ok
你可能會猜測是+pc unicode的原因嗎?好吧,明知不是我們還是試一下:
# /usr/local/bin/erl +pc unicode
Erlang R16B02 (erts-5.10.3) [source] [64-bit] [smp:2:2] [async-threads:10] [hipe] [kernel-poll:false]
Eshell V5.10.3 (abort with ^G)
1> coding:b().
<<17,236,102,96,69,114,108,97,110,103>>
2> io:format("~ts",[v(1)]).
^Qìf`Erlangok
3> q().
ok
問題在什麼地方?對utf8描述符
b()-> <<"我們學習Erlang"/utf8>>.
# /usr/local/bin/erl
Erlang R16B02 (erts-5.10.3) [source] [64-bit] [smp:2:2] [async-threads:10] [hipe] [kernel-poll:false]
Eshell V5.10.3 (abort with ^G)
1> coding:b().
<<230,136,145,228,187,172,229,173,166,228,185,160,69,114,
108,97,110,103>>
2> io:format("~ts",[v(1)]).
我們學習Erlangok
3>
做下簡單的實驗看看這兩者的區別:
erl Erlang/OTP 17 [erts-6.0] [source] [64-bit] [smp:2:2] [async-threads:10] [hipe] [kernel-poll:false] Eshell V6.0 (abort with ^G) 1> "αβ" . [945,946] 2> 2> <<"αβ">> . <<"±²">> 3> 3> <<"αβ"/utf8>> . <<206,177,206,178>> 5> <<177,178>>. <<"±²">>
上面的第2行測試程式碼是怎麼回事呢?輸出的是個什麼東西呢?看一下第5行程式碼就可以了,輸出的是<<177,178>>,換句話說資料被截斷了.
檔名如何解析
至於檔名是否包含unicode,除非是檔名是不可控的外部資源,否則這個問題是可以通過專案規約規避掉的,沒有必要通過程式碼/技術手段解決這個問題.
erl啟動的時候新增不同的flag可以控制解析檔名的方式: +fnl 按照latin去解析檔名 +fnu 按照unicode解析檔名 +fna 是根據環境變數自動選擇,這也是目前的系統預設值.可以使用file:native_name_encoding檢查此引數.
Eshell V5.10.3 (abort with ^G) 1> file:native_name_encoding(). latin1 2> Eshell V6.0 (abort with ^G) 1> file:native_name_encoding(). utf8 2>
最後
unicode,io,file,group,user,re,wx,string這些模組在遇到unicode的時候要特別注意下.應該有不少人在正則這裡栽跟頭了吧, Using Unicode in Erlang 文件資訊量很大,最後還有一些常見問題的解決以及程式碼,有興趣的可以動手實踐一下,今天就到這裡.
2014-9-5 17:39:33 知乎上有一個問題 "使用 Erlang 時應如何處理 Unicode?" http://www.zhihu.com/question/25112531
問題聚焦的點其實就是文件裡面的這幾句:
http://www.erlang.org/doc/apps/stdlib/unicode_usage.html
The languageHaving the source code in UTF-8 also allows you to write string literals containing Unicode characters with code points > 255, although atoms, module names and function names will be restricted to the ISO-Latin-1 range until the Erlang/OTP 18.0 release. Binary literals where you use the /utf8 type, can also be expressed using Unicode characters > 255. Having module names using characters other than 7-bit ASCII can cause trouble on operating systems with inconsistent file naming schemes, and might also hurt portability, so it's not really recommended. It is suggested in EEP 40 that the language should also allow for Unicode characters > 255 in variable names. Whether to implement that EEP or not is yet to be decided.
為什麼不在知乎回答問題?見下圖,我買房選的都是2002,會為了一個網站做出讓步?
