
MapReduce初級經典案例實現
1、資料去重
"資料去重"主要是為了掌握和利用並行化思想來對資料進行有意義的篩選。統計大資料集上的資料種類個數、從網站日誌中計算訪問地等這些看似龐雜的任務都會涉及資料去重。下面就進入這個例項的MapReduce程式設計。
1.1 例項描述
對資料檔案中的資料進行去重。資料檔案中的每行都是一個數據。
樣例輸入如下所示:
1)file1:
2012-3-1 a
2012-3-2 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-7 c
2012-3-3 c
2)file2:
2012-3-1 b
2012-3-2 a
2012-3-3 b
2012-3-4 d
2012-3-5 a
2012-3-6 c
2012-3-7 d
2012-3-3 c
樣例輸出如下所示:
2012-3-1 a
2012-3-1 b
2012-3-2 a
2012-3-2 b
2012-3-3 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-6 c
2012-3-7 c
2012-3-7 d
1.2 設計思路
資料去重的最終目標是讓原始資料中出現次數超過一次的資料在輸出檔案
在MapReduce流程中,map的輸出<key,value>經過shuffle過程聚整合<key,value-list>後會交給reduce。所以從設計好的reduce輸入可以反推出map的輸出key應為資料,value任意。繼續反推,map輸出資料的key為資料,而在這個例項中每個資料代表輸入檔案中的一行內容,所以map階段要完成的任務就是在採用Hadoop預設的作業輸入方式之後,將value設定為key,並直接輸出(輸出中的value任意)。map中的結果經過shuffle過程之後交給reduce。reduce階段不會管每個key有多少個value,它直接將輸入的key複製為輸出的key,並輸出就可以了(輸出中的value被設定成空了)。
1.3 程式程式碼
程式程式碼如下所示:
package com.hebut.mr;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Dedup {
//map將輸入中的value複製到輸出資料的key上,並直接輸出
public static class Map extends Mapper<Object,Text,Text,Text>{
private static Text line=new Text();//每行資料
//實現map函式
public void map(Object key,Text value,Context context)
throws IOException,InterruptedException{
line=value;
context.write(line, new Text(""));
}
}
//reduce將輸入中的key複製到輸出資料的key上,並直接輸出
public static class Reduce extends Reducer<Text,Text,Text,Text>{
//實現reduce函式
public void reduce(Text key,Iterable<Text> values,Context context)
throws IOException,InterruptedException{
context.write(key, new Text(""));
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
//這句話很關鍵
conf.set("mapred.job.tracker", "192.168.1.2:9001");
String[] ioArgs=new String[]{"dedup_in","dedup_out"};
String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: Data Deduplication <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "Data Deduplication");
job.setJarByClass(Dedup.class);
//設定Map、Combine和Reduce處理類
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
//設定輸出型別
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//設定輸入和輸出目錄
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
1.4 程式碼結果
1)準備測試資料
通過Eclipse下面的"DFS Locations"在"/user/hadoop"目錄下建立輸入檔案"dedup_in"資料夾(備註:"dedup_out"不需要建立。)如圖1.4-1所示,已經成功建立。
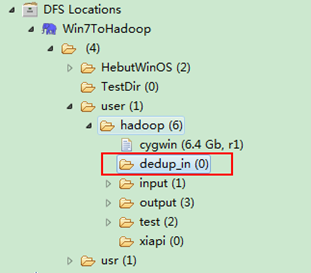
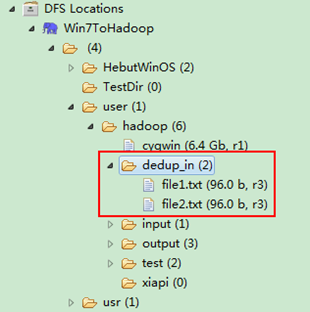
圖1.4-1 建立"dedup_in" 圖1.4.2 上傳"file*.txt"
然後在本地建立兩個txt檔案,通過Eclipse上傳到"/user/hadoop/dedup_in"資料夾中,兩個txt檔案的內容如"例項描述"那兩個檔案一樣。如圖1.4-2所示,成功上傳之後。
從SecureCRT遠處檢視"Master.Hadoop"的也能證實我們上傳的兩個檔案。

檢視兩個檔案的內容如圖1.4-3所示:
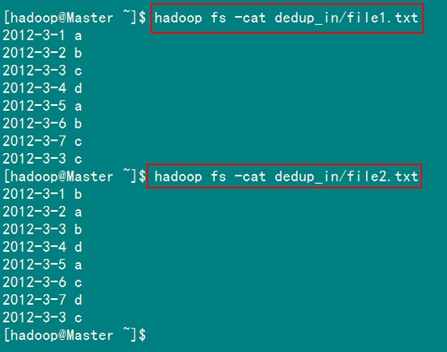
圖1.4-3 檔案"file*.txt"內容
2)檢視執行結果
這時我們右擊Eclipse的"DFS Locations"中"/user/hadoop"資料夾進行重新整理,這時會發現多出一個"dedup_out"資料夾,且裡面有3個檔案,然後開啟雙其"part-r-00000"檔案,會在Eclipse中間把內容顯示出來。如圖1.4-4所示。
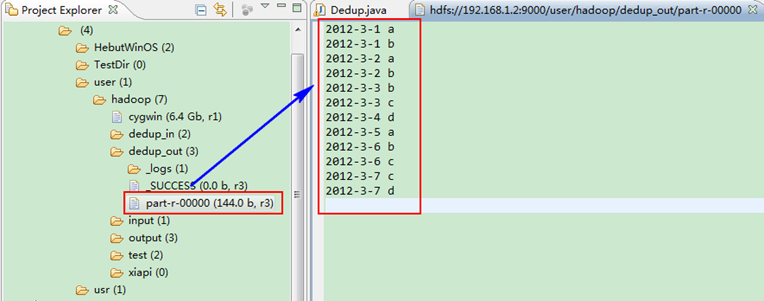
圖1.4-4 執行結果
此時,你可以對比一下和我們之前預期的結果是否一致。
2、資料排序
"資料排序"是許多實際任務執行時要完成的第一項工作,比如學生成績評比、資料建立索引等。這個例項和資料去重類似,都是先對原始資料進行初步處理,為進一步的資料操作打好基礎。下面進入這個示例。
2.1 例項描述
對輸入檔案中資料進行排序。輸入檔案中的每行內容均為一個數字,即一個數據。要求在輸出中每行有兩個間隔的數字,其中,第一個代表原始資料在原始資料集中的位次,第二個代表原始資料。
樣例輸入:
1)file1:
2
32
654
32
15
756
65223
2)file2:
5956
22
650
92
3)file3:
26
54
6
樣例輸出:
1 2
2 6
3 15
4 22
5 26
6 32
7 32
8 54
9 92
10 650
11 654
12 756
13 5956
14 65223
2.2 設計思路
這個例項僅僅要求對輸入資料進行排序,熟悉MapReduce過程的讀者會很快想到在MapReduce過程中就有排序,是否可以利用這個預設的排序,而不需要自己再實現具體的排序呢?答案是肯定的。
但是在使用之前首先需要瞭解它的預設排序規則。它是按照key值進行排序的,如果key為封裝int的IntWritable型別,那麼MapReduce按照數字大小對key排序,如果key為封裝為String的Text型別,那麼MapReduce按照字典順序對字串排序。
瞭解了這個細節,我們就知道應該使用封裝int的IntWritable型資料結構了。也就是在map中將讀入的資料轉化成IntWritable型,然後作為key值輸出(value任意)。reduce拿到<key,value-list>之後,將輸入的key作為value輸出,並根據value-list中元素的個數決定輸出的次數。輸出的key(即程式碼中的linenum)是一個全域性變數,它統計當前key的位次。需要注意的是這個程式中沒有配置Combiner,也就是在MapReduce過程中不使用Combiner。這主要是因為使用map和reduce就已經能夠完成任務了。
2.3 程式程式碼
程式程式碼如下所示:
package com.hebut.mr;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Sort {
//map將輸入中的value化成IntWritable型別,作為輸出的key
public static class Map extends
Mapper<Object,Text,IntWritable,IntWritable>{
private