
BoW詞袋模型Bag of Words cpp實現(stable version 0.01)
致謝:基礎框架來源BoW,開發版本在此基礎上進行,已在Ubuntu、OS X上測試通過,Windows需要支援c++11的編譯器(VS2012及其以上)。
使用
程式碼下載地址:bag-of-words-stable-version,這個是穩定版,上層目錄裡的開發版不要下載,那是我新增測試新模組所用的。
編譯
修改Makefile檔案,如果你的系統支援多執行緒技術,將
CFLAGS = -std=c++11
修改為
CFLAGS = -std=c++11 -fopenMP # if openMP accesses, using this
修改完上面後,再修改編譯所需的OpenCV和cppsugar,即
INCPATH = -I/usr/local/include -I/Users/willard/codes/cpp/opencv-computer-vision/cpp/BoVW/cppsugar
LIBPATH = -L/usr/local/lib
/usr/local/include和/usr/local/lib分別是OpenCV所在的包含標頭檔案目錄路徑和庫目錄路徑,修改為你本機所在的目錄即可。後面的cppsugar目錄同樣換成你本機的目錄。 修改。這些修改完成後,執行下面命令進行編譯:
make
編譯後即可在所在目錄生成可執行檔案。
生成相簿列表檔案
對於待檢索的影象庫imagesDataSet,執行下面命令
python imgNamesToTXT.py -t /Users/willard/Pictures/imagesDataSet
上面執行後生成一個imageNamesList.txt的檔案,該檔案中包含的是每幅影象的路徑及其影象檔名。
建立索引
執行下面命令,會完成特徵提取、生成詞典、量化生成bag of word向量:
./index imageNamesList.txt
上面命令執行玩,會生成兩個檔案bows.dat和dict.dat,分別存放的是影象庫每幅影象的bag of word向量以及詞典。
查詢影象
按下面命令進行查詢
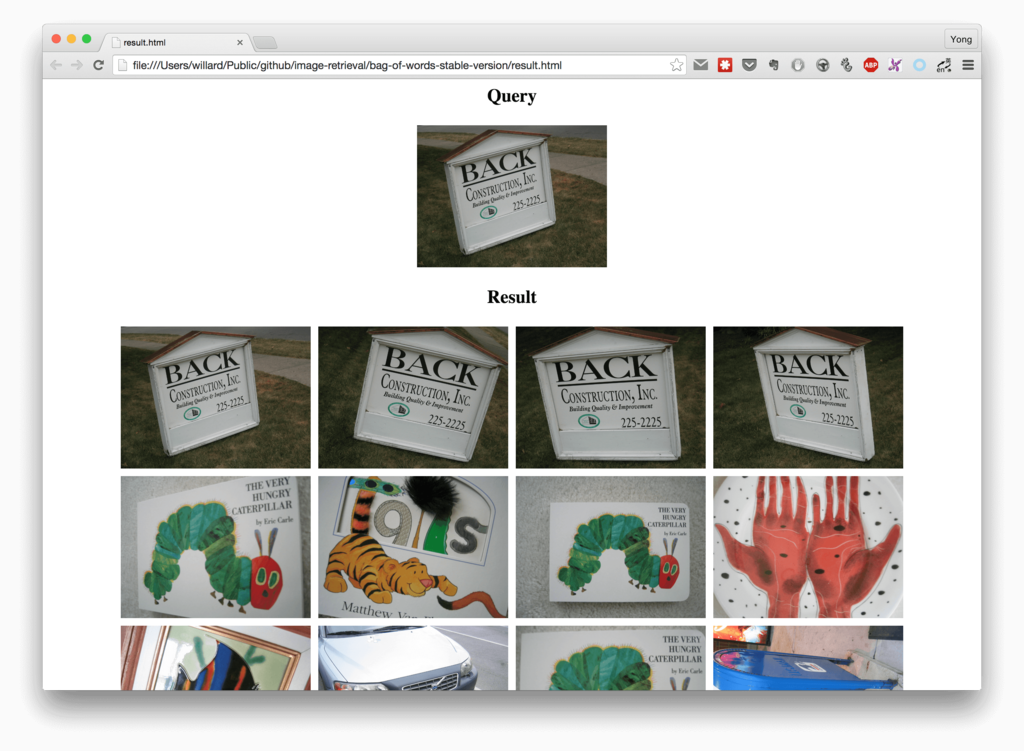
./search /Users/willard/Pictures/first1000/ukbench00499.jpg imageNamesList.txt
其中/Users/willard/Pictures/first1000/ukbench00499.jpg是查詢影象,執行完後,會生成一個result.html的檔案,應為要顯示檢索結果,所以這裡採用的是用html頁面的方式顯示檢索結果的,用瀏覽器開啟即可。
批量測試
為了評價檢索的效果,可以使用ukbenchScores.cpp計算在ukbench影象庫上的NS score(NS分數),下面是在ukbench1000張影象上計算的NS score:
Ukbench first 1000 images, the NS-scores: 3.358, with tf*idf and histogram intersection kernel distance.
Ukbench first 1000 images, the NS-scores: 3.602, with tf and histogram intersection kernel distance.
Bag of words原理
關於bag of words的原理,可以查閱我的博文BoW影象檢索Python實戰和Bag of Words模型。注意,該框架中採用的相似性度量方式是直方圖相交(histogram intersection kernel)的方法,測試發現直方圖相交的方法要比用餘弦距離度量的方式效果更好,但計算速度較慢。
開發版本bag-of-words-dev-version中加入了逆文件詞頻以及RANSAC重排,待效果達到預期後,會新增到穩定版中。
from: http://yongyuan.name/blog/bag-of-words-cpp-implement.html