
BOW詞袋模型
BoW模型
Bag-of-words model (BoW model) 最早出現在自然語言處理(Natural Language Processing)和資訊檢索(Information Retrieval)領域.。該模型忽略掉文字的語法和語序等要素,將其僅僅看作是若干個詞彙的集合,文件中每個單詞的出現都是獨立的。BoW使用一組無序的單詞(words)來表達一段文字或一個文件.。近年來,BoW模型被廣泛應用於計算機視覺中。
基於文字的BoW模型的一個簡單例子如下:
首先給出兩個簡單的文字文件如下:
John likes to watch movies. Mary likes too.
John also likes to watch football games.
基於上述兩個文件中出現的單詞,構建如下一個詞典 (dictionary):
{"John": 1, "likes": 2,"to": 3, "watch": 4, "movies": 5,"also": 6, "football": 7, "games": 8,"Mary": 9, "too": 10}
上面的詞典中包含10個單詞, 每個單詞有唯一的索引, 那麼每個文字我們可以使用一個10維的向量來表示。如下:
[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
[1, 1,1, 1, 0, 1, 1, 1, 0, 0]
該向量與原來文字中單詞出現的順序沒有關係,而是詞典中每個單詞在文字中出現的頻率。
BoW模型用於影象分類
2004年Gabriella Csurka、Christopher R. Dance等人基於詞袋模型提出了一種影象的分類方法--Bag of Keypoints。影象中的單詞(words)被定義為一個影象塊(image patch)的特徵向量(feature vector),影象的BoW模型即 “影象中所有影象塊的特徵向量得到的直方圖”。
關於BoW模型用於影象分類提取特徵直方圖包含以下幾個步驟:
1 特徵提取
提取訓練樣本影象塊中的特徵向量,提取特徵向量的方法可以使SIFT、SUFR等。該步驟生成的影象特徵的描述子應該具有不變性對於光照的的變化、變形、碰撞等。
圖1表示一幅通過SURF方法提取的特徵點影象。

圖1 SURF方法檢測特徵點
2 構建詞典(Vocabulary)
通過上步的特徵提取,我們得到了所有訓練樣本影象中的特徵。比如有N張訓練圖片,使用SIFT方法提取影象特徵,我們最終將得到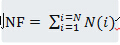
圖2為K均值聚類示意圖。其中菱形、圓形、長方形、五邊形代表四個類(由黃色圓框分別包圍),通過K均值聚類演算法後,將形成4個新的聚類中心,如圖2中4個藍色實心原點表示。
圖2 K均值聚類示意圖
n個聚類中心即我們構建的詞典,以後每來一個新的特徵點,都將該新特徵點對映到n個聚類中心中的一個。
3 計算影象特徵直方圖
通過K均值聚類演算法後,得到n個新的聚類中心,即得到了特徵直方圖的一個基,如圖3所示。
圖3 特徵直方圖的基
接下來我們將影象的特徵點聚類到n個已經生成的詞典(即n個聚類中心)中,並且統計落入每個詞典中的特徵點的個數。這樣我們可以得到一幅影象的特徵直方圖。
不同類別的特徵直方圖不一樣,圖4表示類1的特徵直方圖,圖5表示類2的特徵直方圖,圖6是一幅真實影象的特徵直方圖。
圖4 類1的特徵直方圖
圖5 類2的特徵直方圖
圖6 真實影象的特徵直方圖
上面是關於Bow用於影象分類提取特徵直方圖的基本方法,關於BOW模型用於影象分類,使用SVM訓練請看下篇博文!
如有不正確希望多多包涵,歡迎指出共同交流學習。
Surf和Sift特徵提取程式碼下載地址http://download.csdn.net/detail/u010213393/8159185