
How We Use Data to Suggest Tags for Your Story


How We Use Data to Suggest Tags for Your Story
Here on Medium, we envision tags to be central in organizing and connecting ideas. Follow the tags you’re interested in and Medium will help deliver the right content to you. To do that we’d like as many writers as possible to tag their posts. For writers, we’d love to help you find your audience.
So how can we use data to improve how tags are used?
Our solution: suggest tags.
What Are Tag Suggestions?
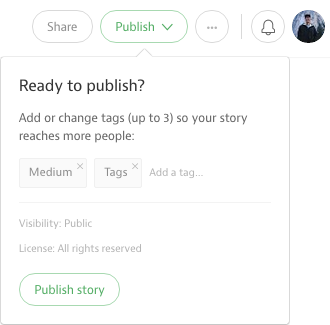
Just as you’re about to publish your draft, we’ll suggest a couple tags for you to use based on what you’ve written. Our goal is not only to increase the number of tagged posts on Medium, but also to help users discover the right tags to use.
Let’s look at the suggested tags for a few excerpts from NY Times articles.
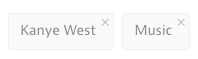
Kanye West declared himself “the greatest living rock star on the planet” at Britain’s Glastonbury festival. But that didn’t prevent a prankster from invading the rapper’s performance and upstaging him.
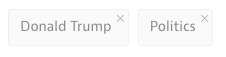
That is because Mr. Trump’s popularity — his support in some polls is now double that of his closest competitors — is built on his unfettered style, rather than on his positions, which have proved highly fungible.
Reddit, the popular community news site, formalized a new set of guidelines that aim to restrict some of the risqué and potentially offensive content posted to the site.
How It Works
Overview
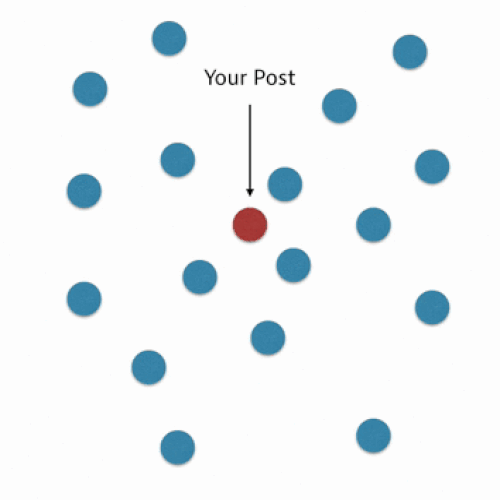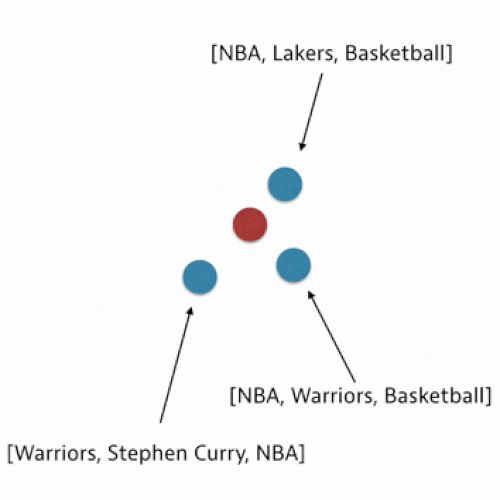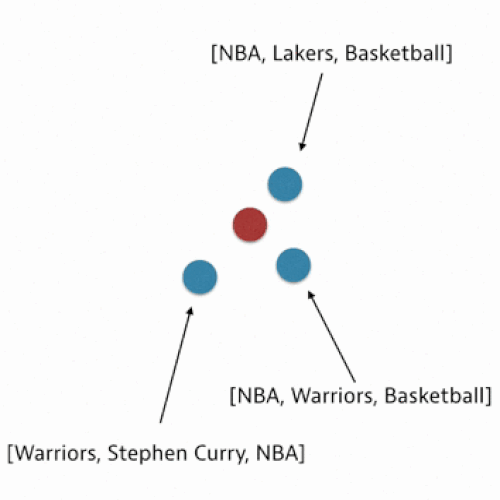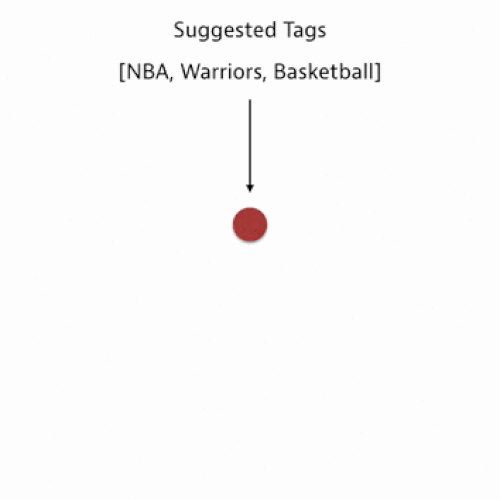
In our algorithm, we use what is called a nearest neighbors approach. This means that for your post we consider the tags of the posts that are most similar to what you’ve drafted. We then aggregate these tags and rank them by a tag score calculated based on similarity.
Here is a simplified visualization:
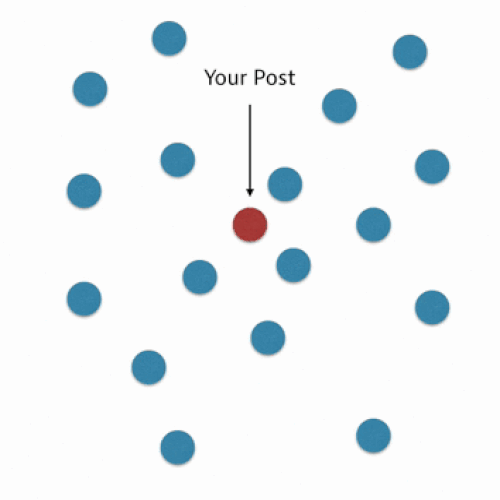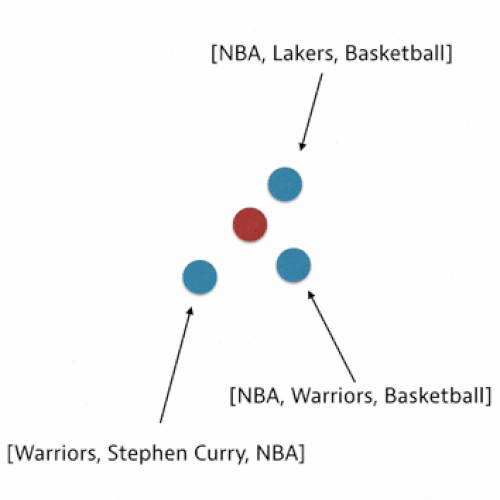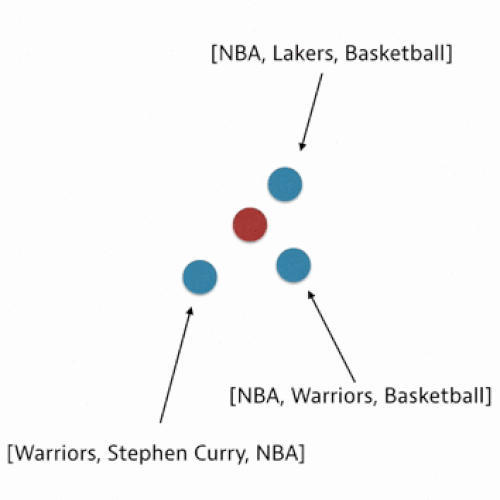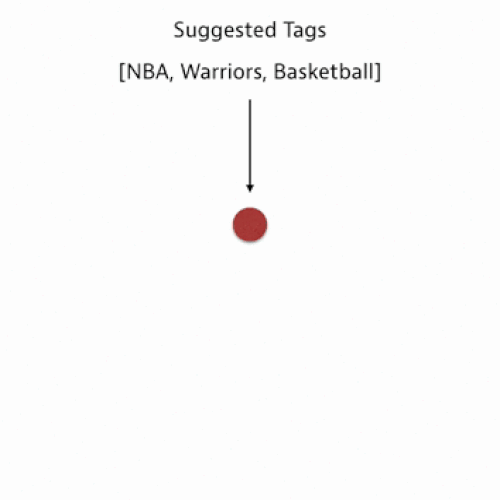
In order to use this nearest neighbors method, we need to find a way to compare posts. We can do this by representing posts as vectors in a high-dimensional space and then quantifying how similar two posts are by calculating a distance metric.
Vectorizing Posts
In vectorizing posts, we use something called tf-idf. tf is short for term frequency and it measures how frequently a certain word occurs in a document. idf, or inverse document frequency, measures how special a certain word is in a collection of documents.
Thus, tf-idf is a product of these two statistics.
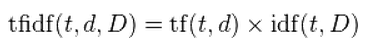
It reflects how important a word is to a given post in a collection of posts. For example, let’s consider a post written about basketball. The word “layup” will have a high tf-idf value because not only does it occur frequently, but it also is a term that is very specific to basketball. On the other hand, “pass” has multiple meanings and can be used in different contexts, so it may not have a high tf-idf value.
In our tag suggestions algorithm, we use tf-idf vectors to represent the content of a post.
Defining A Distance Metric
With our tf-idf post vectors, we can measure the distance between two posts by using cosine similarity. Cosine similarity is the cosine of the angle between two vectors. A pair of post vectors pointing in the same direction will have a cosine similarity of 1, while vectors pointing in opposite directions will have a cosine similiarty of 0. Now we have a way of calculating post similarity!
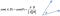
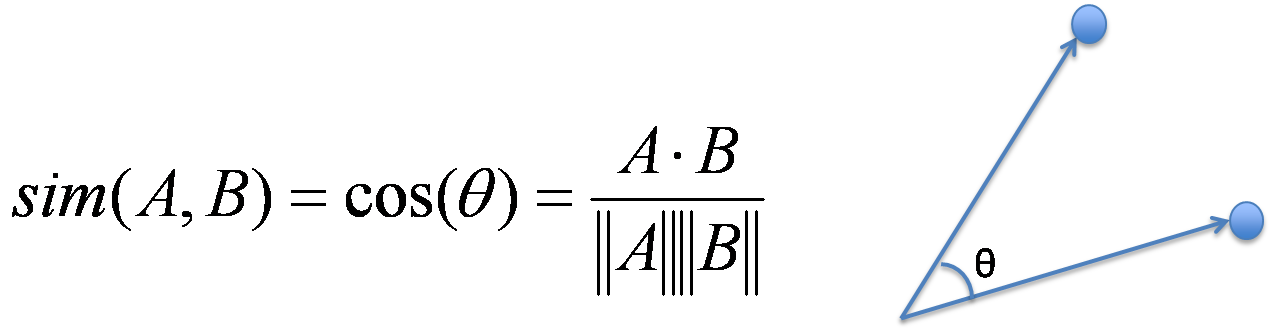
Finding The Nearest Neighbors
Once a writer drafts a new post, we are given a new post vector. A cool thing about using tf-idf vectors is that they are unit vectors. This allows us to easily calculate cosine similiarities by doing a simple dot product. By representing the entire collection of posts as a matrix with n rows (each row representing a post vector), we can do a dot product with the new post vector and we’ll get a n-dimensional vector of cosine similarities.

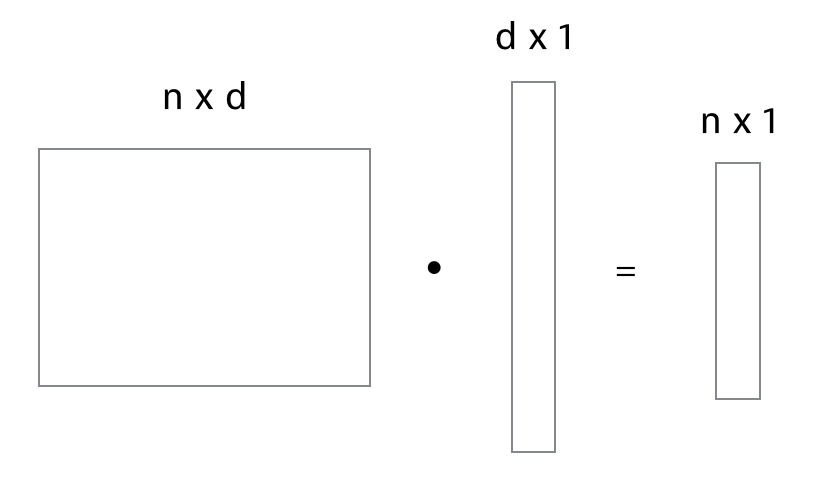
Now we can look for the largest values in this cosine similarity vector to find our nearest neighbors! Finally, we’ll aggregate the tags of these nearest neighbors to determine which ones to suggest.