
GoogleNet系列筆記
GoogLeNet系列筆記包括:
- Inception v1
- Batch Normalization
- Inception v2,Inception v3
- Inception v4,Inception resnet v1,Inception resnet v2
總結
| 網路 | 架構 | 引數 | 特點1 | 特點2 | 特點3 | 特點4 | 特點5 |
|---|---|---|---|---|---|---|---|
| VGG | 架構簡潔高效 | 計算成本高,是v1的數十倍 | |||||
| Inception v1 | 架構複雜,更寬更深 | 引數少,計算成本低 | 1* 1降維減少計算量,在concate前用大卷積核彙總特徵 | 並行pool | 多尺度卷積 | 分支分類器,防止梯度消失 | |
| Inception v2 | 提出三個新的架構 | 圖3:兩個小卷積替換大卷積(3x3代替5x5) ; | 圖5:小卷積再分解(先1x3再3x1代替3x3); | 圖6:並行非對稱卷積(1x3,3x1並行),僅用在最後 | 證明 Relu 比起 linear啟用函式效果好一點 | ||
| Inception v3 | 42層網路,計算量是v1的2.5倍 | inception-v2結構中的分支分類器上加上BN | |||||
| Inception v4 | |||||||
| Inception resnet v1 | |||||||
| Inception resnet v2 |
1.Inception v1
2014年提出Inception 結構 ,這個架構的主要特點是提高了網路內部計算資源的利用率,其中在ILSVRC14提交中應用的一個特例被稱為GoogLeNet,一個22層(加池化層27層)的深度網路。
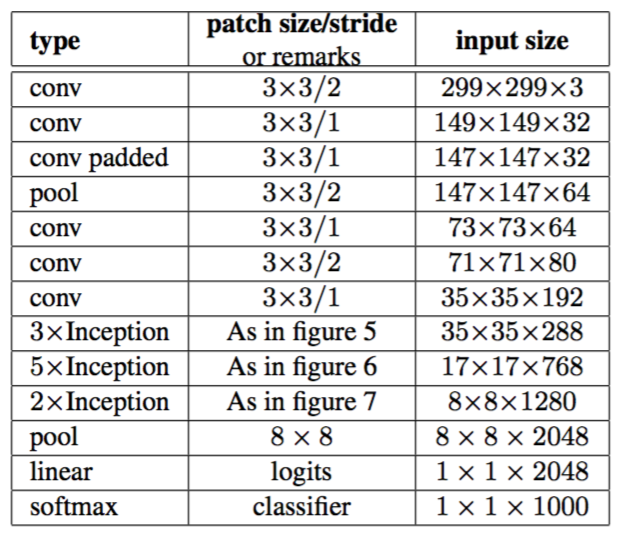
作者採用一系列不同大小的濾波器來處理多尺度,但Inception結構中所有的濾波器是學習到的,且Inception結構重複了很多次,得到了一個22層的深度模型,即GoogLeNet,如表1所示。
作者主要借鑑了以下兩個網路的方法:
- NIN中新增額外的1* 1的卷積層(每個1* 1卷積後都緊跟Relu啟用函式),增加網路深度的方法,目的主要是用它們來作為降維模組來移除 computational bottlenecks(即使前後網路通道數一致)。這不僅允許了深度的增加,而且允許網路的寬度增加但沒有明顯的效能損失。
- 借鑑了R-CNN,分兩階段,第一階段利用分割邊框檢測,第二階段結合邊框利用CNN分類。
表1:

表1中,
- #3x3 reduce和#5x5 reduce分別表示3x3和5x5的卷積前,縮減層中1x1濾波器的個數;
- pool proj表示嵌入的max-pooling之後的投影層中1x1濾波器的個數;
- 縮減層和投影層都要用ReLU;
Inception架構
Inception架構主要是想通過設計一個稀疏的網路結構,利用稀疏矩陣聚類為較為密集的子矩陣來提高計算效能。既有優秀的網路效能,又能節約計算資源。
隨著Inception架構的堆疊,特徵越到後來越集中,所以感受野的尺寸也應增大才能獲得較全面的特徵,所以網路後面會使用3×3和5×5卷積彙總特徵。
在具有大量濾波器的卷積層上,即使加適量的5* 5卷積也可能造成幾個階段內計算量爆炸,所以Inception架構一直使用1×1卷積用來降維,以減少計算量的增加,保持資訊的稀疏,只有在concate之前,才會使用大的卷積壓縮資訊,獲取更完整的影象特徵的資訊。
1* 1的卷積用處:降維,引入非線性(非線性啟用函式ReLu)
圖1:

所有的卷積都使用了ReLu作為啟用函式,
作者發現平均池化比全連線,提高了大約top-1 %0.6的準確率,作者使用平均池化時保留了dropout的使用。
圖2:
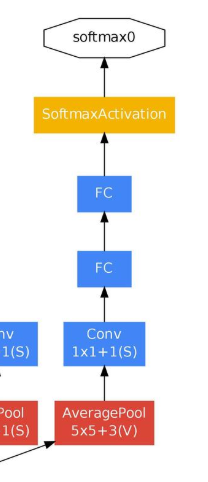
作者添加了輔助分類器(圖2)
目的:提高初始階段分類器的判別能力,同時克服梯度消失的問題。
實驗證實:影響較小,約0.5,只需一個輔助分類器就可以出同樣效果,多了沒用
結構如下:
- 一個濾波器大小5×5,步長為3的平均池化層,具有128個濾波器的1×1卷積。
- 一個全連線層,具有1024個單元和修正線性啟用。
- dropout70%。
- 使用softmax損失的線性層作為分類器。
同時Inception中提出新的影象裁剪方式,雖然效果稍好,但實際應用中不必要使用這個方法。
2. Batch Normalization
李巨集毅課程
batch normalization 的目的是,原先如這個圖所示,網路訓練就如幾個小人傳話筒,只有三個話筒都接起來才能傳聲,起初左邊的小人告訴中間的小人手放低點,右邊的小人告訴中間的手放高些,一次迭代後,小人照做了,還是無法連線。所以batch normalization的目的就是不讓整個資料集一起變化學習,而一個batch一個batch的學習,防止整體學習出錯,無法擬合的情況。



一個batch作為一個整體輸入到網路中去訓練,它的均值和方差會迭代的,是其中某一層的輸出,網路訓練的時候,輸出也會改變,進而改變均值方差,再進而影響Zi的值。Zi與均值方差相關。
batch normalization 的使用前提是這個batch要夠大,如果batch很小的話,它不能代表一個整體的均值和方差,使用這個值做Normalization就會有很大偏差
3. Inception v2-v3
作者將v2的版本的修改的集大成者的模型稱為v3
提出修改Inception 網路的通用設計原則:
- 避免出現特徵bottlenecks,尤其是在網路的早期,即早期卷積核的尺寸不要有太誇張的變化,Pooling也是一種,會導致很多特徵丟失。
- 更多相互獨立的特徵聚集在一起收斂的越快。
- Inception模組在concate之前先利用卷積降維,各分支是高度相關的,所以降維可以在減少計算量的同時保證影象特徵不會有很多損失。
- 平衡網路的寬度和深度。通過平衡每個階段的濾波器數量和網路的深度可以達到網路的最佳效能。網路的寬度和深度並行增加,則可以達到恆定計算量的最佳改進。
後續作者根據上述原則改進網路的到下列網路框架,也證實了上述原則的合理性。
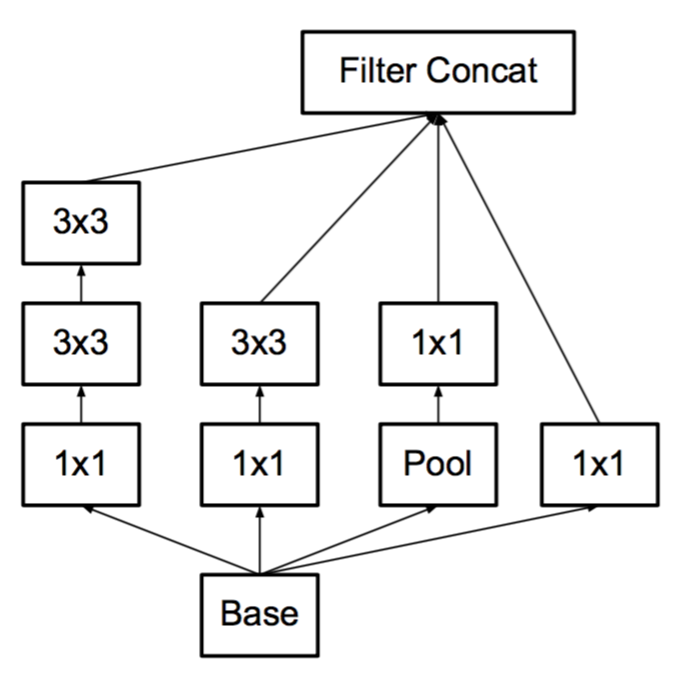
圖3即將 Inception v1 按照原則3,將5* 5卷積用兩個3* 3代替。
圖3:
使用並行結構優化pooling ,解決規則1中提到的特徵瓶頸的問題,解決方法是在pooling前用1x1卷積把特徵數加倍(見圖8右側),這種加倍可以理解加入了冗餘的特徵,然後再作Pooling就只是把冗餘的資訊重新去掉????, 沒有減少資訊量。這種方法有很好的效果但因為加入了1x1卷積會極大的增大計算量。替代的方法是使用兩個並行的支路,一路1x1卷積,由於特徵維度沒有加倍計算量相比之前減少了一倍,一路是Pooling,最後再在特徵維度拼合到一起(見圖9)。這種方法有很好的效果,又沒有增大計算量。
圖8:

圖9:
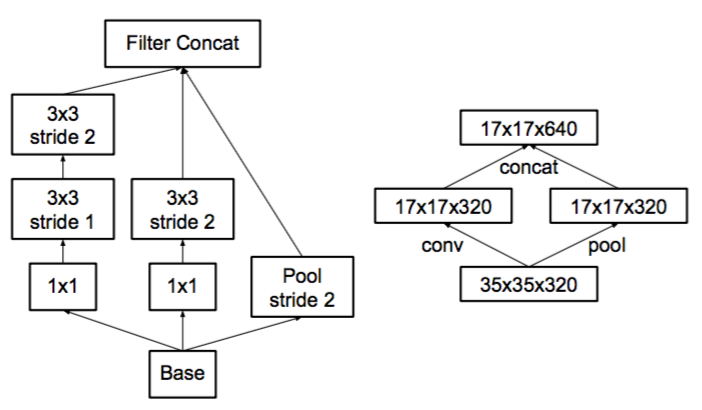
圖4,圖5使用非對稱卷積
通過1×n卷積和後面接一個n×1卷積可以替換任何n×n卷積,並且隨著n增長,節省更多計算成本,作者通過測試發現非對稱卷積用在網路中靠中間的層級才有較好的效果(特別是feature map的大小在12x12~20x20之間時)
作者發現將大卷積分解為非對稱卷積比2* 2 卷積效果更好。如圖4所示,使用3×1卷積後接一個1×3卷積,相當於以與3×3卷積相同的感受野滑動兩層網路,但計算量少很多。
圖4:
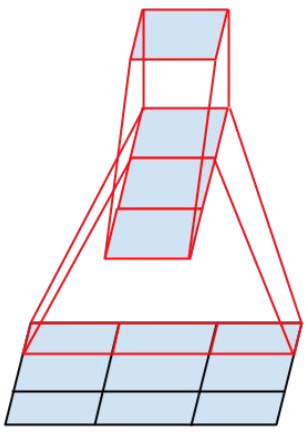
圖5:
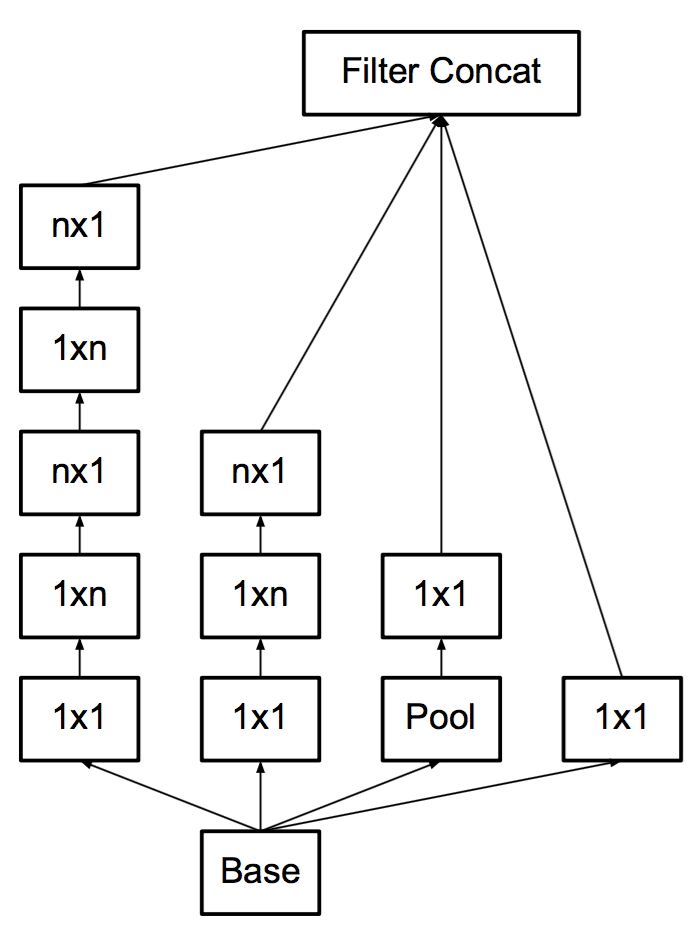
圖6這種架構被用於最粗糙的(8×8)網格,以提升高維表示,如原則2所建議的那樣。我們僅在最粗糙的網格上使用了此解決方案,因為這是產生高維度的地方,稀疏表示是最重要的,因為與空間聚合相比,區域性處理(1×1 卷積)的比率增加。?????
圖6:
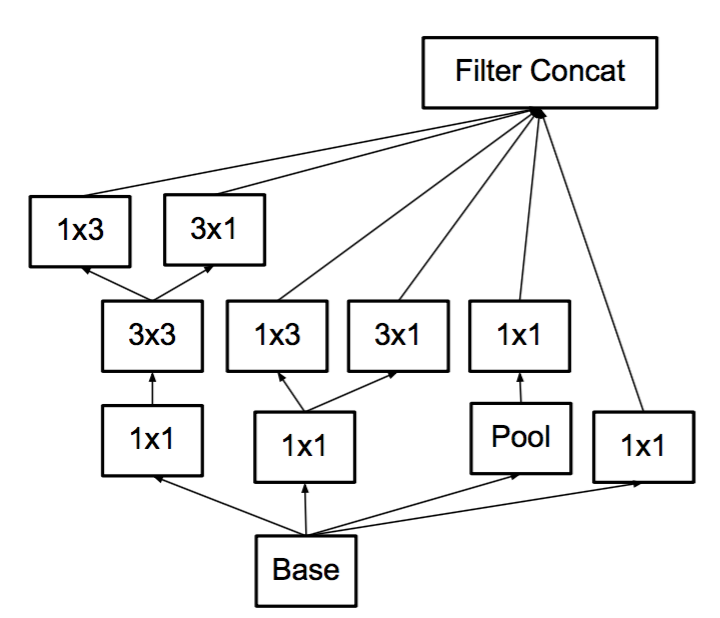
提出Inception v2 架構,證明只要遵照那四個原則修改網路,變化網路的質量就相對穩定。Inception v2 結構(圖7)就是將圖3,圖5,圖6組合在一個網路架構中。inception-v2的結構中如果Auxiliary Classifier上加上BN,就成了inception-v3
圖7:
輔助分類器
輔助分類網路最初的動機是將有用的梯度推向較低層,使其立即有用,並通過抵抗非常深的網路中的消失梯度問題來提高訓練過程中的收斂,事實上它對訓練前期無任何改善,在接近訓練結束的時候開始超越沒有輔助分支的網路,推翻Inception v1中的說法,證明這些輔助分類器對低階特徵的演變可能沒有什麼作用,而是起著正則化的作用,正則化作用的原因沒說。
使用Label Smoothing來對網路輸出進行正則化。
整個訓練過程收斂時Softmax的正確分類的輸入是無窮大,這是一種極其理想的情況,如果讓所有的輸入都產生這種極其理想的輸出,就會造成overfit。為了克服overfit,防止最終出來的正確分類p(k)=1,在輸出p(k)時加了個引數delta,生成新的q’(k),再用它替換原本的q(k)來計算loss。
4. Inception v4-ResNet-v1-ResNet-v2
待補充。。。
5. 說明
bottleneck :瓶頸,表徵瓶頸個人理解為卷積核突然變很大,導致影象資訊損失很多。