
Java系列筆記(5)
阿新 • • 發佈:2019-01-14
我想關注這個系列部落格的粉絲們都應該已經發現了,我一定是個懶蟲,在這裡向大家道歉了。這個系列的部落格是在我工作之餘寫的,經常幾天才寫一小節,不過本著寧缺毋濫的精神,所有寫的東西都是比較精煉的。這篇文章是本系列的第五篇,主要講Java執行緒相關的內容,基本上包含了執行緒要了解的比較深入的東西。技術在於積累,在於總結,在於表達,在於分享,這4點都做到了,一個技術才是我們自己的。
另外說一下,本Java系列筆記,目前一共計劃寫12篇,在這個系列中,側重於Java技術的原理和深入理解,相對之下,程式碼和例項較少,不過需要例項的地方,都給出了網上相關的例項。本系列文章的主要來源是我自己的積累、自己的理解、看的書、以及網上的資料,在文中我儘可能註明了引用出處,如果有發現引用了您的資料而沒有註明的,請儘快聯絡我:[email protected]。
這是第5篇,接下是第6篇《併發》,我一定儘快寫,儘快寫,快寫,寫。。。 目錄 1,執行緒原理和概念 當代作業系統,大多數都支援多工處理。對於多工的處理,有兩個常見的概念:程序和執行緒。 程序是作業系統分配資源的單位,這裡的資源包括CPU、記憶體、IO、磁碟等等裝置,程序之間切換時,作業系統需要分配和回收這些資源,所以其開銷相對較大(遠大於執行緒切換); 執行緒 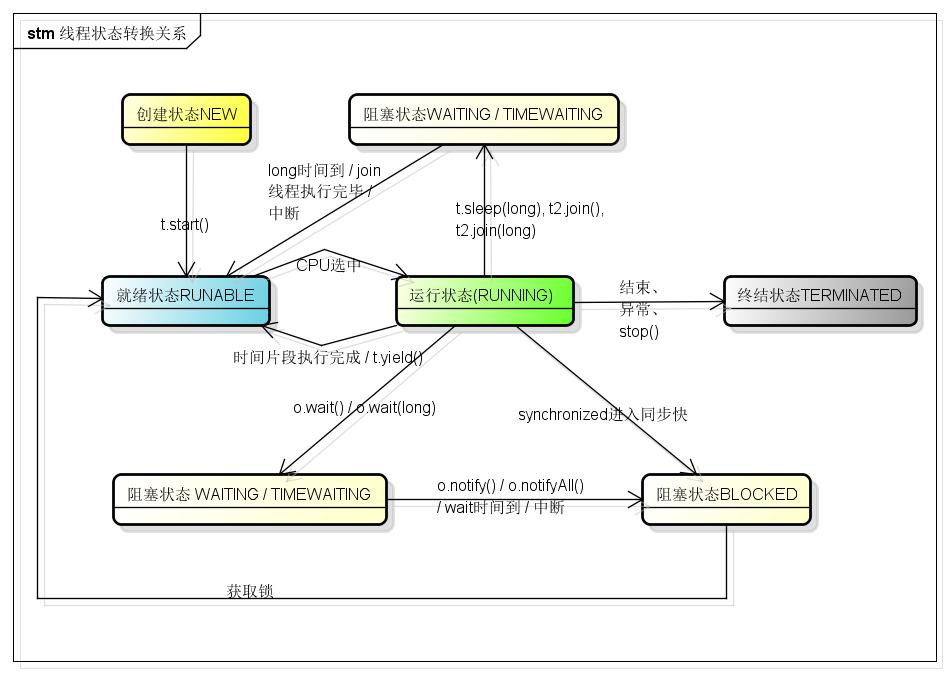 3,執行緒的區域性變量表
本節請結合《Java系列筆記(3) - Java記憶體區域和GC機制》來閱讀。在本節,我們需要將Thread類和Java中執行緒的概念分開來講了:
3,執行緒的區域性變量表
本節請結合《Java系列筆記(3) - Java記憶體區域和GC機制》來閱讀。在本節,我們需要將Thread類和Java中執行緒的概念分開來講了:
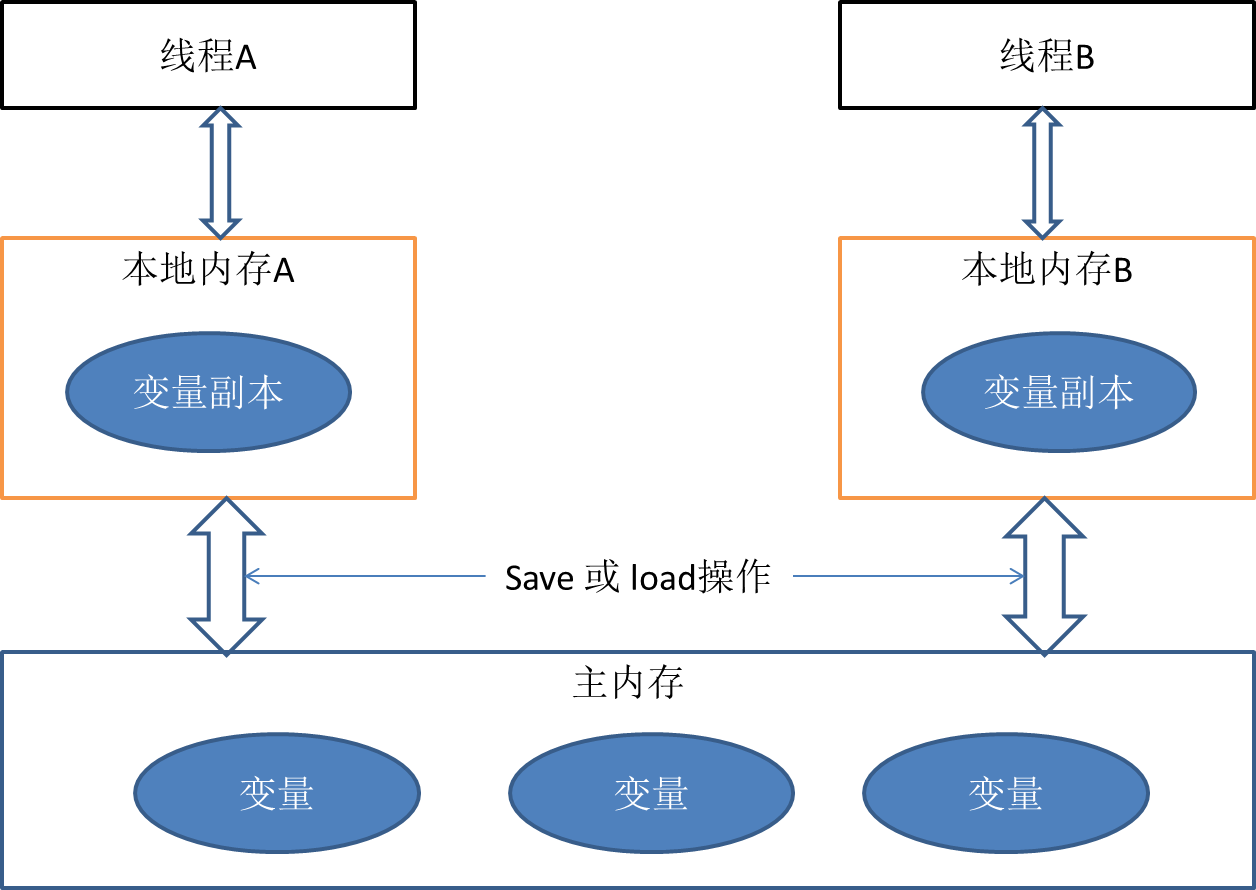 關於主記憶體與工作記憶體之間的具體互動協議,即一個變數如何從主記憶體拷貝到工作記憶體、如何從工作記憶體同步到主記憶體之間的實現細節,Java記憶體模型定義了以下八種操作來完成(參見:Java記憶體模型:http://www.cnblogs.com/nexiyi/p/java_memory_model_and_thread.html):
關於主記憶體與工作記憶體之間的具體互動協議,即一個變數如何從主記憶體拷貝到工作記憶體、如何從工作記憶體同步到主記憶體之間的實現細節,Java記憶體模型定義了以下八種操作來完成(參見:Java記憶體模型:http://www.cnblogs.com/nexiyi/p/java_memory_model_and_thread.html):
 6,重排序和一致性規則
重排序
Java的記憶體模型與硬體系統記憶體模型是相對應的,主記憶體相當於硬體的記憶體,而為了獲取更好的執行速度,虛擬機器及硬體系統可能會讓工作記憶體優先儲存於暫存器和快取記憶體中,而每個執行緒的本地記憶體就相當於是暫存器和告訴快取。
基於快取記憶體的儲存互動很好地解決了處理器與記憶體的速度矛盾,但是引入了一個新的問題:快取一致性(Cache Coherence)。在多處理器系統中,每個處理器都有自己的快取記憶體,而他們又共享同一主存,多個處理器運算任務都涉及同一塊主存,需要 一種協議可以保障資料的一致性,這類協議有MSI、MESI、MOSI及Dragon Protocol等。第4節記憶體模型中介紹的8種操作,就類似於這樣的一個協議。
為了使得處理器內部的運算單元能儘可能被充分利用,處理器可能會對輸入程式碼進行亂起執行(Out-Of-Order Execution)優化,處理器會在計算之後將對亂序執行的程式碼進行結果重組,保證結果準確性。與處理器的亂序執行優化類似,Java虛擬機器的即時編譯 器中也有類似的指令重排序(Instruction Recorder)優化。
6,重排序和一致性規則
重排序
Java的記憶體模型與硬體系統記憶體模型是相對應的,主記憶體相當於硬體的記憶體,而為了獲取更好的執行速度,虛擬機器及硬體系統可能會讓工作記憶體優先儲存於暫存器和快取記憶體中,而每個執行緒的本地記憶體就相當於是暫存器和告訴快取。
基於快取記憶體的儲存互動很好地解決了處理器與記憶體的速度矛盾,但是引入了一個新的問題:快取一致性(Cache Coherence)。在多處理器系統中,每個處理器都有自己的快取記憶體,而他們又共享同一主存,多個處理器運算任務都涉及同一塊主存,需要 一種協議可以保障資料的一致性,這類協議有MSI、MESI、MOSI及Dragon Protocol等。第4節記憶體模型中介紹的8種操作,就類似於這樣的一個協議。
為了使得處理器內部的運算單元能儘可能被充分利用,處理器可能會對輸入程式碼進行亂起執行(Out-Of-Order Execution)優化,處理器會在計算之後將對亂序執行的程式碼進行結果重組,保證結果準確性。與處理器的亂序執行優化類似,Java虛擬機器的即時編譯 器中也有類似的指令重排序(Instruction Recorder)優化。
 JMM屬於語言級的記憶體模型,它確保在不同的編譯器和不同的處理器平臺之上,通過禁止特定型別的編譯器重排序和處理器重排序,為程式設計師提供一致的記憶體可見性保證。
JMM屬於語言級的記憶體模型,它確保在不同的編譯器和不同的處理器平臺之上,通過禁止特定型別的編譯器重排序和處理器重排序,為程式設計師提供一致的記憶體可見性保證。
 從圖中可以看出:
Executor是頂層介面,其中只有一個execute(Runnable)的宣告,返回值是void;
ExecutorService介面集成了Executor介面,同時提供了submit、invokeAll、invokeAny、shutDown等方法;
AbstractExecutorService實現了ExecutorService介面,並基本實現其所有方法;
ThreadPoolExecutor繼承了類AbstractExecutorService;並提供了execute()/submit()/shutdown()/shudownNow()等方法的具體實現(execute是提供了具體實現,其它方法用了超類的實現);
注:execute和submit的區別在於:
execute是定義在Executor中,並在ThreadPoolExecutor中具體實現,沒有返回值的,其作用就是向執行緒池提交一個任務並執行;
submit是定義在ExecutorService中,並在AbstractExecutorService中具體實現,且在ThreadPoolExecutor中沒有對其進行重寫,submit能夠返回結果,其內部實現,其實還是在呼叫execute(),不過,它利用Future&FutureTask來獲取任務結果。
ExecutorService提供了管理終止的方法,以及可為跟蹤一個或多個非同步任務執行狀況而生成 Future 的方法。可以關閉 ExecutorService,這將導致其拒絕新任務。
提供兩個方法來關閉 ExecutorService:
從圖中可以看出:
Executor是頂層介面,其中只有一個execute(Runnable)的宣告,返回值是void;
ExecutorService介面集成了Executor介面,同時提供了submit、invokeAll、invokeAny、shutDown等方法;
AbstractExecutorService實現了ExecutorService介面,並基本實現其所有方法;
ThreadPoolExecutor繼承了類AbstractExecutorService;並提供了execute()/submit()/shutdown()/shudownNow()等方法的具體實現(execute是提供了具體實現,其它方法用了超類的實現);
注:execute和submit的區別在於:
execute是定義在Executor中,並在ThreadPoolExecutor中具體實現,沒有返回值的,其作用就是向執行緒池提交一個任務並執行;
submit是定義在ExecutorService中,並在AbstractExecutorService中具體實現,且在ThreadPoolExecutor中沒有對其進行重寫,submit能夠返回結果,其內部實現,其實還是在呼叫execute(),不過,它利用Future&FutureTask來獲取任務結果。
ExecutorService提供了管理終止的方法,以及可為跟蹤一個或多個非同步任務執行狀況而生成 Future 的方法。可以關閉 ExecutorService,這將導致其拒絕新任務。
提供兩個方法來關閉 ExecutorService:
另外說一下,本Java系列筆記,目前一共計劃寫12篇,在這個系列中,側重於Java技術的原理和深入理解,相對之下,程式碼和例項較少,不過需要例項的地方,都給出了網上相關的例項。本系列文章的主要來源是我自己的積累、自己的理解、看的書、以及網上的資料,在文中我儘可能註明了引用出處,如果有發現引用了您的資料而沒有註明的,請儘快聯絡我:[email protected]。
這是第5篇,接下是第6篇《併發》,我一定儘快寫,儘快寫,快寫,寫。。。 目錄 1,執行緒原理和概念 當代作業系統,大多數都支援多工處理。對於多工的處理,有兩個常見的概念:程序和執行緒。 程序是作業系統分配資源的單位,這裡的資源包括CPU、記憶體、IO、磁碟等等裝置,程序之間切換時,作業系統需要分配和回收這些資源,所以其開銷相對較大(遠大於執行緒切換); 執行緒
3,執行緒的區域性變量表
本節請結合《Java系列筆記(3) - Java記憶體區域和GC機制》來閱讀。在本節,我們需要將Thread類和Java中執行緒的概念分開來講了:
- 一個Thread類例項只是一個物件,像Java中的任何其他物件一樣,具有變數和方法,生死於堆上。
- Java中,每個執行緒都有一個呼叫棧,即使你不在Java程式中建立任何新的執行緒,執行緒也在後臺執行著(如:main執行緒)。一個Java應用總是從main()方法開始執行,mian()方法執行在一個執行緒內,它被稱為主執行緒。一旦建立一個新的執行緒,就產生一個新的呼叫棧。
關於主記憶體與工作記憶體之間的具體互動協議,即一個變數如何從主記憶體拷貝到工作記憶體、如何從工作記憶體同步到主記憶體之間的實現細節,Java記憶體模型定義了以下八種操作來完成(參見:Java記憶體模型:http://www.cnblogs.com/nexiyi/p/java_memory_model_and_thread.html):
- lock(鎖定):作用於主記憶體的變數,把一個變數標識為一條執行緒獨佔狀態。
- unlock(解鎖):作用於主記憶體變數,把一個處於鎖定狀態的變數釋放出來,釋放後的變數才可以被其他執行緒鎖定。
- read(讀取):作用於主記憶體變數,把一個變數值從主記憶體傳輸到執行緒的工作記憶體中,以便隨後的load動作使用
- load(載入):作用於工作記憶體的變數,它把read操作從主記憶體中得到的變數值放入工作記憶體的變數副本中。
- use(使用):作用於工作記憶體的變數,把工作記憶體中的一個變數值傳遞給執行引擎,每當虛擬機器遇到一個需要使用變數的值的位元組碼指令時將會執行這個操作。
- assign(賦值):作用於工作記憶體的變數,它把一個從執行引擎接收到的值賦值給工作記憶體的變數,每當虛擬機器遇到一個給變數賦值的位元組碼指令時執行這個操作。
- store(儲存):作用於工作記憶體的變數,把工作記憶體中的一個變數的值傳送到主記憶體中,以便隨後的write的操作。
- write(寫入):作用於主記憶體的變數,它把store操作從工作記憶體中一個變數的值傳送到主記憶體的變數中。
如果要把一個變數從主記憶體中複製到工作記憶體,就需要按順尋地執行read和load操作,如果把變數從工作記憶體中同步回主記憶體中,就要按順序地執行store和write操作。Java記憶體模型只要求上述操作必須按順序執行,而沒有保證必須是連續執行。也就是read和load之間,store和write之間是可以插入其他指令的,如對主記憶體中的變數a、b進行訪問時,可能的順序是read a,read b,load b, load a。Java記憶體模型還規定了在執行上述八種基本操作時,必須滿足如下規則:
- 不允許read和load、store和write操作之一單獨出現
- 不允許一個執行緒丟棄它的最近assign的操作,即變數在工作記憶體中改變了之後必須同步到主記憶體中。
- 不允許一個執行緒無原因地(沒有發生過任何assign操作)把資料從工作記憶體同步回主記憶體中。
- 一個新的變數只能在主記憶體中誕生,不允許在工作記憶體中直接使用一個未被初始化(load或assign)的變數。即就是對一個變數實施use和store操作之前,不許先執行過了assign和load操作。
- 一個變數在同一時刻只允許一條線成對其進行lock操作,lock和unlock必須成對出現
- 如果對一個變數執行lock操作,將會清空工作記憶體中此變數的值,在執行引擎使用這個變數前需要重新執行load或assign操作初始化變數的值
- 如果一個變數事先沒有被lock操作鎖定,則不允許對它執行unlock操作;也不允許去unlock一個被其他執行緒鎖定的變數。
- 對一個變數執行unlock操作之前,必須先把次變數同步到主記憶體中(執行store和write操作)。
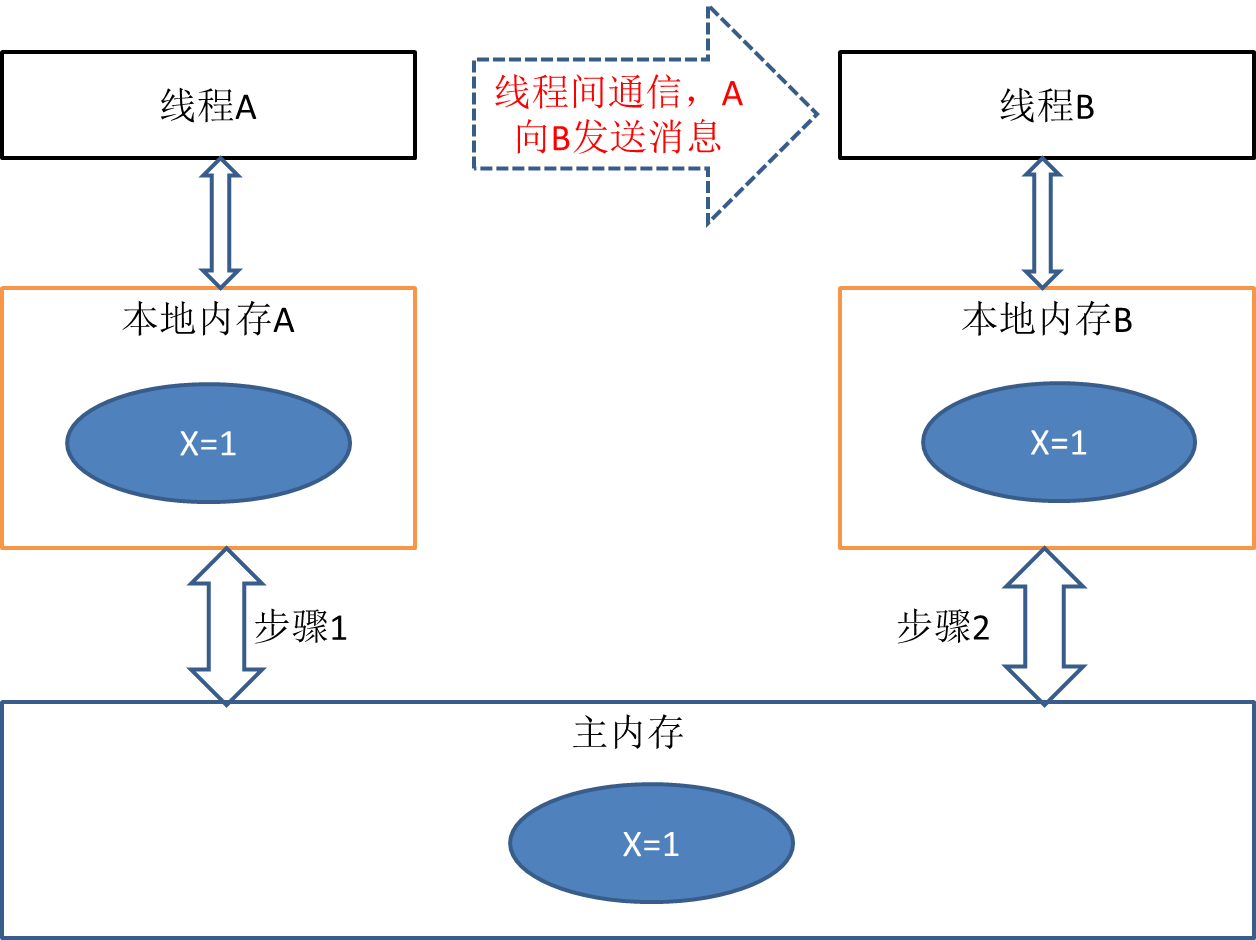
- 執行緒A把本地記憶體A中更新過的共享變數重新整理到主記憶體中去。
- 執行緒B到主記憶體中去讀取執行緒A之前已更新過的共享變數。
6,重排序和一致性規則
重排序
Java的記憶體模型與硬體系統記憶體模型是相對應的,主記憶體相當於硬體的記憶體,而為了獲取更好的執行速度,虛擬機器及硬體系統可能會讓工作記憶體優先儲存於暫存器和快取記憶體中,而每個執行緒的本地記憶體就相當於是暫存器和告訴快取。
基於快取記憶體的儲存互動很好地解決了處理器與記憶體的速度矛盾,但是引入了一個新的問題:快取一致性(Cache Coherence)。在多處理器系統中,每個處理器都有自己的快取記憶體,而他們又共享同一主存,多個處理器運算任務都涉及同一塊主存,需要 一種協議可以保障資料的一致性,這類協議有MSI、MESI、MOSI及Dragon Protocol等。第4節記憶體模型中介紹的8種操作,就類似於這樣的一個協議。
為了使得處理器內部的運算單元能儘可能被充分利用,處理器可能會對輸入程式碼進行亂起執行(Out-Of-Order Execution)優化,處理器會在計算之後將對亂序執行的程式碼進行結果重組,保證結果準確性。與處理器的亂序執行優化類似,Java虛擬機器的即時編譯 器中也有類似的指令重排序(Instruction Recorder)優化。
重排序分成三種類型:
- 編譯器優化的重排序。編譯器在不改變單執行緒程式語義放入前提下,可以重新安排語句的執行順序。
- 指令級並行的重排序。現代處理器採用了指令級並行技術來將多條指令重疊執行。如果不存在資料依賴性,處理器可以改變語句對應機器指令的執行順序。
- 記憶體系統的重排序。由於處理器使用快取和讀寫緩衝區,這使得載入和儲存操作看上去可能是在亂序執行。
JMM屬於語言級的記憶體模型,它確保在不同的編譯器和不同的處理器平臺之上,通過禁止特定型別的編譯器重排序和處理器重排序,為程式設計師提供一致的記憶體可見性保證。
對於編譯器重排序,JMM的編譯器重排序規則會禁止特定型別的編譯器重排序(不是所有的編譯器重排序都要禁止)。
對於處理器重排序,JMM的處理器重排序規則會要求java編譯器在生成指令序列時,插入特定型別的記憶體屏障(memory barriers,intel稱之為memory fence)指令,通過記憶體屏障指令來禁止特定型別的處理器重排序(不是所有的處理器重排序都要禁止)。
為了保證記憶體的可見性,Java編譯器在生成指令序列的適當位置會插入記憶體屏障指令來禁止特定型別的處理器重排序。Java記憶體模型把記憶體屏障分為LoadLoad、LoadStore、StoreLoad和StoreStore四種:
1,boolean cancel(boolean mayInterruptIfRunning);該方法用於取消任務,如果取消成功,返回true,如果取消失敗,返回false。
mayInterruptIfRunning引數表示的是是否允許取消正在執行且沒有完畢的任務,true表示可以取消正在執行的任務;
如果任務已經執行完成,無論引數是什麼,該方法都返回false;
如果任務正在執行:若引數為true,則取消成功的話返回true;若引數為false,則直接返回false;
若任務尚未執行,則無論引數是什麼,都在取消成功後返回true;
2,boolean isCancelled();該方法判斷任務是否被取消成功,如果在任務正常完成前被取消成功,則返回true;
3,boolean isDone(); 該方法判斷任務是否正常完成,如果是,返回true;
4,V get() throws InterruptedException, ExecutionException; 該方法用於獲取執行結果,呼叫該方法後,會產生阻塞,呼叫者會一直阻塞知道任務完畢返回結果才繼續執行;
5,V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;該方法與get相似,只不過,有超時限制,如果到了指定時間還沒有得到結果,則返回null;
Future是一個介面,無法用於直接建立物件,而且Runnable也無法直接用Future,所以就有了FutureTask,FutureTask也位於java.util.concurrent包,FuntureTask的實現如下:
public class FutureTask<V> implements RunnableFuture<V>,就是說,FutureTask實現了RunnableFuture介面,而RunnableFuture介面是怎麼回事呢?public interface RunnableFuture<V> extends Runnable, Future<V> {void run();
}
可見,FutureTask實際上同時實現了Future介面和Runnable介面,所以它既可以作為Runnable被Thread執行緒執行,也可以作為Future得到Callable的返回值;
FutureTask提供了兩個構造器:
public FutureTask(Callable<V> callable) {}public FutureTask(Runnable runnable, V result) {}
用這兩個構造器,FutureTask可以對callable和runnable的做出實現,並且由於FutureTask實現了Future介面,所以可以實現對於callable和runnable的管理。
執行緒池
執行緒池存在的目的在於:提前建立好需要的執行緒,減少臨時建立執行緒帶來的資源消耗。而且每個ThreadPoolExecutor執行緒池還維護者一些統計資料,如完成的任務數,可以方便的進行統計,同時該類還提供了很多可調整的引數和擴充套件的鉤子(hook)。
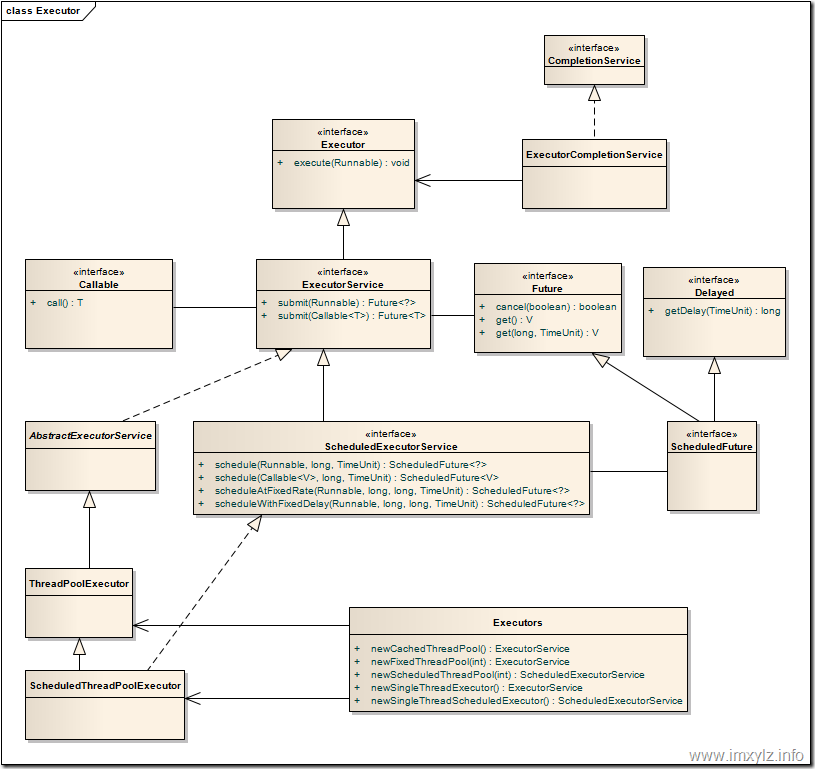
java.util.concurrent中,關於執行緒池提供了很多介面和類,這些介面和類的關係如下:(圖片來自:http://www.blogjava.net/xylz/archive/2010/12/21/341281.html,深入淺出 Java Concurrency (29): 執行緒池 part 2 Executor 以及Executors)
從圖中可以看出:
Executor是頂層介面,其中只有一個execute(Runnable)的宣告,返回值是void;
ExecutorService介面集成了Executor介面,同時提供了submit、invokeAll、invokeAny、shutDown等方法;
AbstractExecutorService實現了ExecutorService介面,並基本實現其所有方法;
ThreadPoolExecutor繼承了類AbstractExecutorService;並提供了execute()/submit()/shutdown()/shudownNow()等方法的具體實現(execute是提供了具體實現,其它方法用了超類的實現);
注:execute和submit的區別在於:
execute是定義在Executor中,並在ThreadPoolExecutor中具體實現,沒有返回值的,其作用就是向執行緒池提交一個任務並執行;
submit是定義在ExecutorService中,並在AbstractExecutorService中具體實現,且在ThreadPoolExecutor中沒有對其進行重寫,submit能夠返回結果,其內部實現,其實還是在呼叫execute(),不過,它利用Future&FutureTask來獲取任務結果。
ExecutorService提供了管理終止的方法,以及可為跟蹤一個或多個非同步任務執行狀況而生成 Future 的方法。可以關閉 ExecutorService,這將導致其拒絕新任務。
提供兩個方法來關閉 ExecutorService:
- shutdown()方法在終止前允許執行以前提交的任務;
- shutdownNow() 方法阻止等待任務的啟動並試圖停止當前正在執行的任務。在終止後,執行程式沒有任務在執行,也沒有任務在等待執行,並且無法提交新任務。應該關閉未使用的 ExecutorService以允許回收其資源;
- 當建立執行緒池後,初始時,執行緒池處於RUNNING狀態;
- 如果呼叫了shutdown()方法,則執行緒池處於SHUTDOWN狀態,此時執行緒池不能夠接受新的任務,它會等待所有任務執行完畢;
- 如果呼叫了shutdownNow()方法,則執行緒池處於STOP狀態,此時執行緒池不能接受新的任務,並且會去嘗試終止正在執行的任務;
- 當執行緒池處於SHUTDOWN或STOP狀態,並且所有工作執行緒已經銷燬,任務快取佇列已經清空或執行結束後,執行緒池被設定為TERMINATED狀態。
privatefinalBlockingQueue<Runnable> workQueue;//任務快取佇列,用來存放等待執行的任務privatefinalReentrantLock mainLock =newReentrantLock();//執行緒池的主要狀態鎖,對執行緒池狀態(比如執行緒池大小、runState等)的改變都要使用這個鎖privatefinalHashSet<Worker> workers =newHashSet<Worker>();//用來存放工作集privatevolatilelongkeepAliveTime;//執行緒存貨時間privatevolatilebooleanallowCoreThreadTimeOut;//是否允許為核心執行緒設定存活時間privatevolatileintcorePoolSize;//核心池的大小(即執行緒池中的執行緒數目大於這個引數時,提交的任務會被放進任務快取佇列)privatevolatileintmaximumPoolSize;//執行緒池最大能容忍的執行緒數privatevolatileintpoolSize;//執行緒池中當前的執行緒數privatevolatileRejectedExecutionHandler handler;//任務拒絕策略privatevolatileThreadFactory threadFactory;//執行緒工廠,用來建立執行緒privateintlargestPoolSize;//用來記錄執行緒池中曾經出現過的最大執行緒數privatelongcompletedTaskCount;//用來記錄已經執行完畢的任務個數
- 如果當前執行緒池中的執行緒數目小於corePoolSize,則每來一個任務,就會建立一個執行緒去執行這個任務;
- 如果當前執行緒池中的執行緒數目>=corePoolSize,則每來一個任務,會嘗試將其新增到任務快取隊列當中,若新增成功,則該任務會等待空閒執行緒將其取出去執行;若新增失敗(一般來說是任務快取佇列已滿),則會嘗試建立新的執行緒去執行這個任務;
- 如果當前執行緒池中的執行緒數目達到maximumPoolSize,則會採取任務拒絕策略進行處理;
- 如果執行緒池中的執行緒數量大於 corePoolSize時,如果某執行緒空閒時間超過keepAliveTime,執行緒將被終止,直至執行緒池中的執行緒數目不大於 corePoolSize;如果允許為核心池中的執行緒設定存活時間,那麼核心池中的執行緒空閒時間超過keepAliveTime,執行緒也會被終止。
預設情況下,建立執行緒池之後,執行緒池中是沒有執行緒的,需要提交任務之後才會建立執行緒。
在實際中如果需要執行緒池建立之後立即建立執行緒,可以通過以下兩個方法辦到:
- prestartCoreThread():初始化一個核心執行緒;
- prestartAllCoreThreads():初始化所有核心執行緒
在前面我們多次提到了任務快取佇列,即workQueue,它用來存放等待執行的任務。
workQueue的型別為BlockingQueue<Runnable>,通常可以取下面三種類型:
1)ArrayBlockingQueue:基於陣列的先進先出佇列,此佇列建立時必須指定大小;
2)LinkedBlockingQueue:基於連結串列的先進先出佇列,如果建立時沒有指定此佇列大小,則預設為Integer.MAX_VALUE;
3)synchronousQueue:這個佇列比較特殊,它不會儲存提交