
基於空間規則化區域建議的無人機物件計數網路
原文:Drone-based Object Counting by Spatially Regularized Regional Proposal Network
摘要:現有的計數方法通常採用基於迴歸的方法,並且不能精確定位目標物件,這妨礙了進一步的分析(例如高階理解和細粒度分類)。此外,以前的大部分工作主要集中在使用固定攝像頭對靜態環境中的物體進行計數。受無人駕駛飛行器(即無人駕駛飛機)出現的驅動,我們有興趣在這種動態環境中檢測和計數物體。我們提出佈局建議網路(LPN)和空間核心,以同時對無人機錄製的視訊中的目標物件(例如汽車)進行計數和本地化。與傳統的地區建議(region proposal)方法不同,我們利用空間佈局資訊(例如,汽車經常停車),並將這些空間正則化約束引入到我們的網路中,以提高定位精度。為了評估我們的計數方法,我們提出了一個新的大型汽車停車場資料集(CARPK),其中包含從不同停車場捕獲的近9萬輛汽車。據我們所知,它是支援物件計數的第一個也是最大的無人機檢視資料集,並提供了邊界框註釋。
1、介紹
隨著無人駕駛飛行器的出現,新的潛在應用出現在針對航空相機的無限制影象和視訊分析中。 在這項工作中,我們解決了計算無人駕駛視訊中物體(例如汽車)數量的計數問題。 用於監視停車場的現有方法[10,2,1]通常假設場景的被監視物件的位置已經預先已知並且攝像機被固定,並且投擲汽車計數作為分類問題,這使得傳統汽車 計數方法不直接適用於無約束無人機視訊。
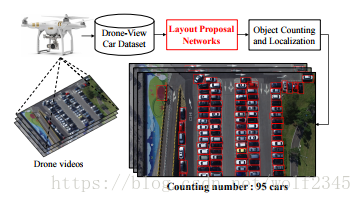
圖1.我們提出了一個佈局建議網路(LPN)來對無人機視訊中的物件進行本地化和統計。 我們介紹了用於學習我們的網路的空間限制,以提高定位精度。 詳細的網路結構如圖4所示。
目前的物件計數方法經常學習一種將高維影象空間對映到非負計數的迴歸模型
我們觀察到,對於一組物件例項存在某些佈局模式,可以利用這些佈局模式來提高物件計數的準確性。 例如,汽車常常停在一排,動物聚集在一定的佈局(例如,魚環和鴨漩渦)。 在本文中,我們介紹了一種新穎的佈局建議網路(LPN),可對無人機視訊中的物體進行計數和本地化(圖1)。 與現有的物件提議方法不同,我們引入了一種新的空間正則化損失來學習我們的佈局建議網路。 請注意,我們的方法學習物件提議之間的一般相鄰關係,並不特定於某個場景。
我們的空間正則化損失是一種權重方案,它對不同的物件提議的重要性分數進行重新加權,並鼓勵將區域提案放置在正確的位置。
表1.鳥瞰車相關資料集的比較。 與PUCPR資料集相比,我們的資料集支援在單個場景中為所有車輛提供邊界框註釋的計數任務。 最重要的是,與其他汽車資料集相比,我們的CARPK是無人機場景中唯一的資料集,並且具有足夠多的數量,以便為深度學習模型提供足夠的訓練樣本。


圖2.(a),(b),(c),(d)和(e)是OIRDS [28],VEDAI [20],COWC [18],PUCPR [10]和CARPK (我們的)資料集(每個資料集有兩個影象)。 與(a),(b)和(c)相比,PUCPR資料集和CARPK資料集在單個場景中擁有更多的汽車數量,更適合評估計數任務。
為了評估我們方法的有效性和可靠性,我們引入了一個新的大型計數資料集CARPK(表1)。 我們的資料集包含89,777輛車,併為每輛車提供邊界框註釋。 此外,我們考慮PKLot [10]的子資料集PUCPR,它是PKLot資料集中場景關閉到鳥瞰圖的那個。 我們的新CARPK資料集提供了無約束場景中的第一個和最大規模的無人機檢視停車場資料集,而不是PUCPR資料集中高層建築的固定攝像機檢視(圖2)。 此外,PUCPR資料集只能與分類任務結合使用,該分類任務將預先裁剪的影象(汽車或非汽車)與給定位置分類。
此外,PUCPR資料集僅註釋部分關注區域的停車區域,因此不能支援計數任務。 由於我們的任務是對影象中的物件進行計數,因此我們還為部分PUCPR資料集以單幅全影象對所有汽車進行註釋。 我們的CARPK資料集的內容在4個不同停車場的各種場景中是無指令碼和多樣化的。 據我們所知,我們的資料集是第一個也是最大的基於無人機的資料集,它可以支援計數任務,併為完整影象中的眾多汽車提供手動標註的註釋。 本文的主要貢獻總結如下:
1. 據我們所知,這是利用空間佈局資訊進行物體區域建議的第一項工作。 我們改進了公共PUCPR資料集中最新地區提案方法的平均召回率(即59.9%[22]至62.5%)。
2. .我們引入了一個新的大型停車場資料集(CARPK),其中包含近9萬輛基於無人機場景的高解析度影象記錄的汽車停車場。 最重要的是,與其他停車場資料集相比,我們的CARPK資料集是支援計數的第一個也是最大的停車場資料集.
3. 我們對本區域提案方法的不同決策選擇提供深入分析,並證明利用佈局資訊可以大大減少提案並改進計數結果。
2 相關工作
2.1 目標計數
大多數當代計數方法大致可以分為兩類。 一個是通過迴歸方法計數,另一個是通過檢測例項計數[17,14]。 迴歸計數器通常是高維影象空間到非負計數的對映。 有幾種方法[3,6,7,8,15]試圖通過使用受低階特徵訓練的全域性迴歸器來預測計數。 但是,全域性迴歸方法忽略了一些約束條件,例如人們通常在人行道上行走以及例項的大小。 還有一些基於密度迴歸的方法[23,16,5],它們可以通過可計數物件的密度來估計物件計數,然後在該密度上聚合。
最近,大量作品將深入學習引入人群統計任務。 Zhang等人沒有將計算物體的數量計算在有限的場景中, [31]解決了過場人群統計任務的問題,這是過去的密度估計方法的弱點。 Sindagi等人 [26]結合全球和當地的背景資訊,以更好地估計人群數量。 Mundhenk等人 [18]通過提取影象塊的表示來估計航空影象子空間中的汽車數量,以近似物體組的外觀。 Zhang等人 [32]利用FCN和LSTM聯合估算車輛密度並計算城市攝像機拍攝的低解析度視訊。 然而,基於迴歸的方法不能產生精確的物件位置,這嚴重限制了進一步的研究和應用(例如,高階理解和細粒度分類)。
2.2 目標建議
近年來,地區提案發展良好,網路深厚。 由於在推斷時間內在多個位置和尺度上檢測物件需要計算量大的分類器,因此解決此問題的最佳方法是檢視可能位置的一小部分。 最近的一些工作證明,基於深度網路的區域提案方法已經超過了以前的作品[29,4,33,9],這些作品基於低階提示,有了大幅度提高
3 資料集
由於缺乏大型標準化公共資料集,其中包含無數基於無人機的影象集合,因此很難建立用於深度學習模型的自動計數系統。例如,OIRDS [28]僅有180輛獨特的汽車。最近與汽車相關的資料集VEDAI [20]擁有2,950輛汽車,但這些資料仍然太少,無法用於深度學習者。較新的資料集COWC [18]擁有32,716輛汽車,但影象解析度仍然很低。它每輛車只有24到48個畫素。此外,標註格式不是以boundingbox的形式標註,而是以汽車模型檢索,汽車品牌統計,以及探索哪種型別的汽車為主的汽車的中心畫素點,不能進一步調查。將在當地開車。此外,以上所有資料都是低解析度影象,無法提供詳細資訊用於學習細粒度的深層模型。現有資料集的問題是:1)低解析度影象可能損害訓練模型的效能; 2)資料集中的車號較少,有可能在訓練深度模型時導致過度擬合。
由於現有資料集存在上述問題,因此我們從無人機檢視影象建立了大型停車場資料集,這些資料集更適合深度學習演算法。它支援物件計數,物件本地化和進一步調查,通過提供boundingbox方面的註釋。與我們最相似的公共資料集,也有高解析度的汽車影象,是PKLot的子資料集PUCPR [10],它從建築物的第10層提供檢視,因此類似於無人機檢視影象到一定程度上。但是,PUCPR資料集只能與分類任務一起使用,該分類任務會將給定位置的預處理影象(汽車或非汽車)分類。此外,該資料集僅從單個影象中的總共331個停車位註釋了一部分汽車(100個特定停車位),使其無法支援計數和本地化任務。因此,我們從部分PUCPR資料集的單個影象中完成所有汽車的註釋,稱為PUCPR +資料集,現在總共擁有近17,000輛汽車。除了PUCPR的不完整標註問題之外,還有一個致命的問題,即它們的攝像機感測器被固定在同一個地方,使得資料集的影象場景完全相同 - 導致深度學習模型遇到資料集偏差問題。
出於這個原因,我們引入了一個全新的資料集CARPK,我們的資料集的內容在4個不同的停車場的各種場景中是無指令碼和多樣化的。我們的資料集還包含大約90,000輛無人機視角的汽車。它與PUCPR資料集中高層建築的攝像頭不同。這是一個用於在各種停車場場景中進行汽車計數的大型資料集。該影象集通過為每輛車提供邊界框進行註釋。所有標記的邊界框都用左上角和右下角記錄得很好。只要標記區域可以被識別,並且可以確定該例項是一輛汽車,就會包含位於影象邊緣的汽車。據我們所知,我們的資料集是第一個也是最大的基於無人機檢視的停車場資料集,可支援以全圖形方式為大量汽車提供手動標記的註釋計數。表1中列出了資料集的細節,圖2中顯示了一些示例。
4 方法
我們的物品計數系統採用了一個區域建議模組,它考慮了規則化的佈局結構。 它是一個深度完全卷積網路,將任意大小的影象作為輸入,並輸出可能包含例項的物件不可知提議。 整個系統是一個統一的物件統一框架(圖1)。 通過利用復現例項物件的空間資訊,LPN模組不僅關注可能的位置,而且還建議目標檢測模組在影象中應該看的方向。
4.1. Layout Proposal Network(佈局建議網路LPN)
我們觀察到,對於一組物件例項存在某些佈局模式,可用於預測可能以相同方向或相同例項附近出現的物件。 因此,我們設計了一個新穎的地區建議模組,可以利用結構佈局並從特定方向收集附近物體的置信度分數(圖3)。
我們綜合描述LPNs的設計網路結構(圖4)如下。 類似於RPN [22],網路通過在共享卷積特徵對映上滑動小網路來生成區域提議。 它將最後一個卷積層上的3×3視窗作為輸入,用於減少表示維度,然後將特徵饋送到兩個相同的1×1卷積層,其中一個用於定位,另一個用於分類該框屬於前景還是分類。 區別在於我們的損失函式為每個位置處的預測框引入空間正則化權重。 利用空間資訊的權重,我們可以最大限度地減少網路中多工物件功能的損失。 我們在每幅影象上使用的損失函式定義如下:
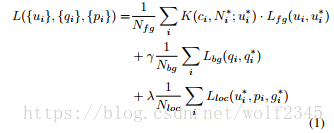
Nfg和Nbg約定俗成的前景和背景。Nloc和Nfg相同是因為它只考慮前景類的數量,如果IoU與ground trouth重疊高於0.7,或者具有最高的IoU與gruoud trouth框交疊的預設框,預設框標記為u * i = 1;如果IoU與ground trouth重疊低於0.3,預設框標記為q*i=0。Lfg(ui,ui*) = -log[ui,ui*]和Lbg(qi,qi*)=-log(1-qi)(1-qi*)是真實類別最小化的負面對數似然率。這裡,i是預測框的索引。在前景損失前面,K表示我們應用空間正則化權重來重新加權每個預測框的客觀分數。對於預測盒的中心位置ci,通過高斯空間核得到權重。 它將根據鄰近ci的m個相鄰的ground truth 中心點給出重新排列的權重。 ci的真實相鄰中心被表示為N * i = {c * 1,...,c * m}∈S ci,其落入輸入影象上的空間視窗畫素大小S內。 我們在本文中使用S = 255來獲得更大的空間範圍。
Lloc是本地化損失,這是一個強大的損失函式[11]。 這個項只對前景predict box(u * i = 1)有效,否則為0.與[22]類似,我們計算前景預測盒pi與地面真值盒gi之間的偏移損失與它們的中心位置(x ,y),寬度(w)和高度(h)。

在我們的實驗中,我們將γ和λ設定為1.另外,為了處理小物件,而不是conv5-3層,我們選擇conv4-3圖層特徵以獲得輸入影象上更好的拼貼預設框跨度並選擇 預設盒子尺寸比預設設定(128×128,256×256,512×512)小四倍(16×16,40×40,100×100)。
圖4.佈局建議網路的結構。 在損失層,結構權重被整合以重新加權候選人
框以獲得更好的結構建議。 更多細節見第4.2節。
4.2. Spatial Pattern Score
例項的大多數物件在彼此之間呈現出一定的模式。 例如,汽車將在停車場沿著一個方向排列,船舶將定期擁抱岸邊。 即使在生物學中,我們也可以找到集體動物的行為,讓他們看到某種佈局(例如,魚類環面,鴨漩渦和螞蟻廠)。 因此,我們引入了一種在培訓階段以端對端方式重新加權區域提案的方法。 所提出的方法可以減少推斷階段中用於減少計數和檢測過程的計算成本的提議的數量。 對於嵌入式裝置(如無人機)來說,降低功耗尤為重要,因為電池電量只能為無人機提供能量,僅能維持20分鐘。
為了設計佈局模式,我們在輸入影象的空間上應用不同方向的二維高斯空間核K(見方程1),其中高斯核的中心是預測的方框位置ci。 我們計算所有正向預測框的置信度權重。 通過結合基礎事實的佈局知識,我們可以瞭解每個預測盒子的權重。 在方程4中,它表明預測位置ci的空間模式分數是Sci內部的地面真值位置的權重總和。 我們計算輸入三元組的分數(ci,N * i,u * i):
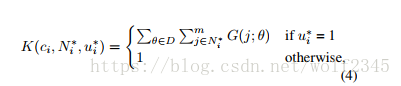
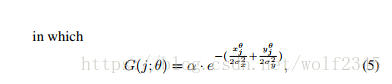
G具有不同旋轉半徑D = {θ1,...θr}的二維高斯空間核,其中我們使用r = 4,範圍從0到π。 座標(xj,yj)是方程5中第j個地面真值盒的中心位置,係數α是高斯函式的幅值。 所有實驗使用α= 1
我們只給出標記為u * i = 1的前景預測box ci的權重。通過在不同方向核心(方程4)中聚合來自地面真值盒子N * i的權重,我們可以計算出一個總和 考慮各種佈局結構的分數。 它將給物體位置提供更高的概率,物體位置的weight更大。 即,圍繞它的例項越相似的物件,預測的盒子越有可能是相同類別的例項。 因此,預測盒子收集來自附近相同物體的信心(圖3)。 通過利用空間正則化的權重,我們可以學習一個用於生成區域建議的模型,其中例項的物件將以其自己的佈局顯示。