
大資料實時計算Spark學習筆記(5)—— RDD的 transformation
阿新 • • 發佈:2018-12-30
1 RDD的轉換
1.1 groupByKey
- (k,v) => (k,Iterable)
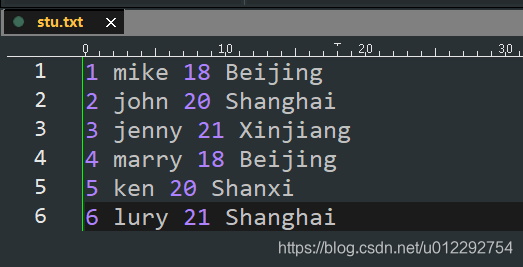
package com.bigdataSpark.cn
import org.apache.spark.{SparkConf, SparkContext}
object GroupByKeyDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("GroupByKeyDemo")
conf. 

1.2 aggregateByKey
1.3 sortByKey
1.4 join
- (k,v).join(k,w) => (k,(v,w))
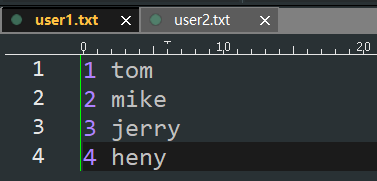
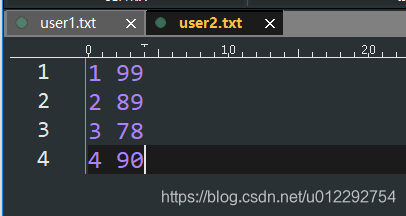
package com.bigdataSpark.cn
import org. 
1.5 cogroup 協分組
- (k,v).cogroup(k,w) => (k,(Iterable,Iterable))
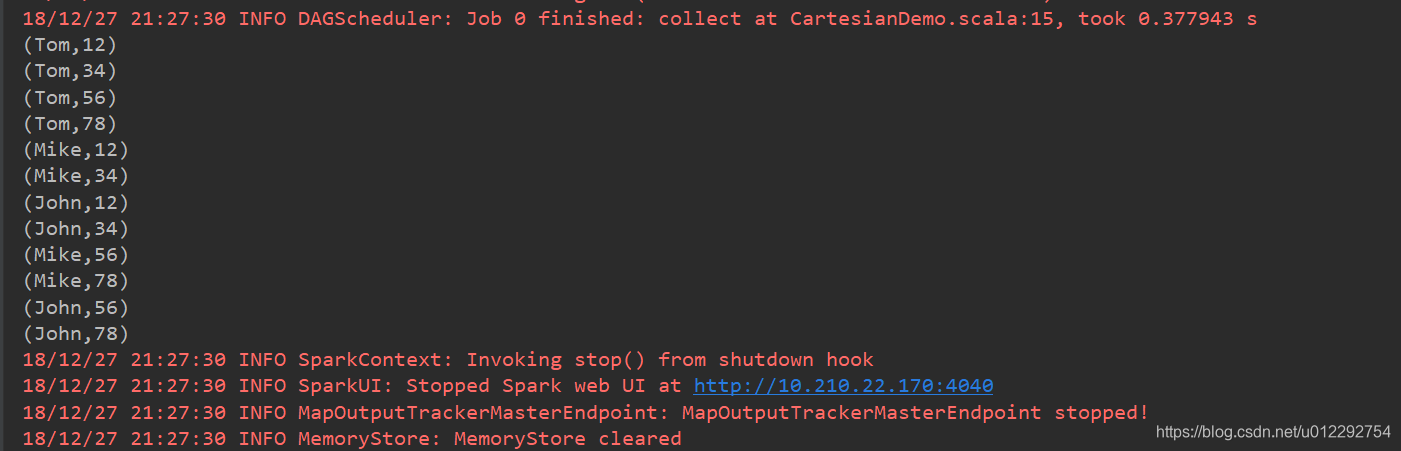
1.6 笛卡爾積 cartesian
- RR[T] RDD[U] => RDD[(T,U)]
package com.bigdataSpark.cn
import org.apache.spark.{SparkConf, SparkContext}
object CartesianDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("cartesianDemo")
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(Array("Tom", "Mike", "John"))
val rdd2 = sc.parallelize(Array("12", "34", "56", "78"))
val rdd = rdd1.cartesian(rdd2)
rdd.collect().foreach(t => {
println(t)
})
}
}
1.7 pipe

1.8 coalesce
- 降低 RDD 的分割槽