
使用 Elasticsearch ik分詞實現同義詞搜尋
阿新 • • 發佈:2018-12-30
1、首先需要安裝好Elasticsearch 和elasticsearch-analysis-ik分詞器
2、配置ik同義詞
Elasticsearch 自帶一個名為 synonym 的同義詞 filter。為了能讓 IK 和 synonym 同時工作,我們需要定義新的 analyzer,用 IK 做 tokenizer,synonym 做 filter。聽上去很複雜,實際上要做的只是加一段配置。
開啟 /config/elasticsearch.yml 檔案,加入以下配置:
index: analysis: analyzer: ik_syno: type: custom tokenizer: ik_max_word filter: [my_synonym_filter] ik_syno_smart: type: custom tokenizer: ik_smart filter: [my_synonym_filter] filter: my_synonym_filter: type: synonym synonyms_path: analysis/synonym.txt
以上配置定義了 ik_syno 和 ik_syno_smart 這兩個新的 analyzer,分別對應 IK 的 ik_max_word 和 ik_smart 兩種分詞策略。根據 IK 的文件,二者區別如下:
- ik_max_word:會將文字做最細粒度的拆分,例如「中華人民共和國國歌」會被拆分為「中華人民共和國、中華人民、中華、華人、人民共和國、人民、人、民、共和國、共和、和、國國、國歌」,會窮盡各種可能的組合;
- ik_smart:會將文字做最粗粒度的拆分,例如「中華人民共和國國歌」會被拆分為「中華人民共和國、國歌」;
3、建立/config/analysis/synonym.txt 檔案,輸入一些同義詞並存為 utf-8 格式。例如
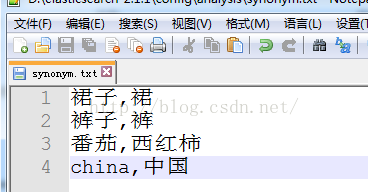
到此同義詞配置已經完成,重啟ES即可,搜尋時指定分詞為ik_syno或ik_syno_smart。
建立Mapping對映。執行curl命令如下
以上程式碼為 test 索引下的 article 型別指定了欄位特徵: title 、 content 和 tags 欄位使用 ik_syno 做為 analyzer,說明它使用 ik_max_word 做為分詞,並且應用 synonym 同義詞策略; slug 欄位沒有指定 analyzer,說明它使用預設分詞;而 update_date 欄位則不會被索引。curl -XPOST http://192.168.1.99:9200/goodsindex/goods/_mapping -d'{ "goods": { "_all": { "enabled": true, "analyzer": "ik_max_word", "search_analyzer": "ik_max_word", "term_vector": "no", "store": "false" }, "properties": { "title": { "type": "string", "term_vector": "with_positions_offsets", "analyzer": "ik_syno", "search_analyzer": "ik_syno" }, "content": { "type": "string", "term_vector": "with_positions_offsets", "analyzer": "ik_syno", "search_analyzer": "ik_syno" }, "tags": { "type": "string", "term_vector": "no", "analyzer": "ik_syno", "search_analyzer": "ik_syno" }, "slug": { "type": "string", "term_vector": "no" }, "update_date": { "type": "date", "term_vector": "no", "index": "no" } } } }'