
轉自知乎-我見過最通俗易懂的KMP演算法詳解
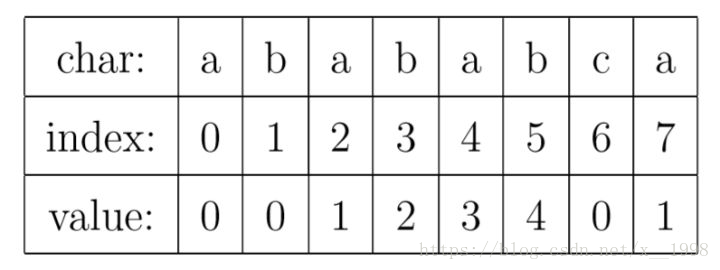
就像例子中所示的,如果待匹配的模式字串有8個字元,那麼PMT就會有8個值。
我先解釋一下字串的字首和字尾。如果字串A和B,存在A=BS,其中S是任意的非空字串,那就稱B為A的字首。例如,”Harry”的字首包括{”H”, ”Ha”, ”Har”, ”Harr”},我們把所有字首組成的集合,稱為字串的字首集合。同樣可以定義字尾A=SB, 其中S是任意的非空字串,那就稱B為A的字尾,例如,”Potter”的字尾包括{”otter”, ”tter”, ”ter”, ”er”, ”r”},然後把所有後綴組成的集合,稱為字串的字尾集合。要注意的是,字串本身並不是自己的字尾。
有了這個定義,就可以說明PMT中的值的意義了。PMT中的值是字串的字首集合與字尾集合的交集中最長元素的長度
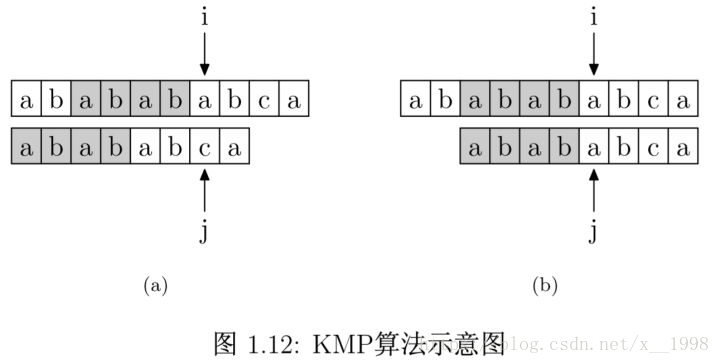
好了,解釋清楚這個表是什麼之後,我們再來看如何使用這個表來加速字串的查詢,以及這樣用的道理是什麼。如圖 1.12 所示,要在主字串"ababababca"中查詢模式字串"abababca"。如果在 j 處字元不匹配,那麼由於前邊所說的模式字串 PMT 的性質,主字串中 i 指標之前的 PMT[j −1] 位就一定與模式字串的第 0 位至第 PMT[j−1] 位是相同的。這是因為主字串在 i 位失配,也就意味著主字串從 i−j 到 i 這一段是與模式字串的 0 到 j 這一段是完全相同的。而我們上面也解釋了,模式字串從 0 到 j−1 ,在這個例子中就是”ababab”,其字首集合與字尾集合的交集的最長元素為”abab”, 長度為4。所以就可以斷言,主字串中i指標之前的 4 位一定與模式字串的第0位至第 4 位是相同的,即長度為 4 的字尾與字首相同。這樣一來,我們就可以將這些字元段的比較省略掉。具體的做法是,保持i指標不動,然後將j指標指向模式字串的PMT[j −1]位即可。
簡言之,以圖中的例子來說,在 i 處失配,那麼主字串和模式字串的前邊6位就是相同的。又因為模式字串的前6位,它的前4位字首和後4位字尾是相同的,所以我們推知主字串i之前的4位和模式字串開頭的4位是相同的。就是圖中的灰色部分。那這部分就不用再比較了。
int KMP(char * t, char * p)
{
int i = 0;
int j = 0;
while (i < strlen(t) && j < strlen(p))
{
if (j == -1 || t[i] == p[j])
{
i++;
j++;
}
else
j = next[j];
}
if (j == strlen(p))
return i - j;
else
return -1;
}
好了,講到這裡,其實KMP演算法的主體就已經講解完了。你會發現,其實KMP演算法的動機是很簡單的,解決的方案也很簡單。遠沒有很多教材和演算法書裡所講的那麼亂七八糟,只要搞明白了PMT的意義,其實整個演算法都迎刃而解。
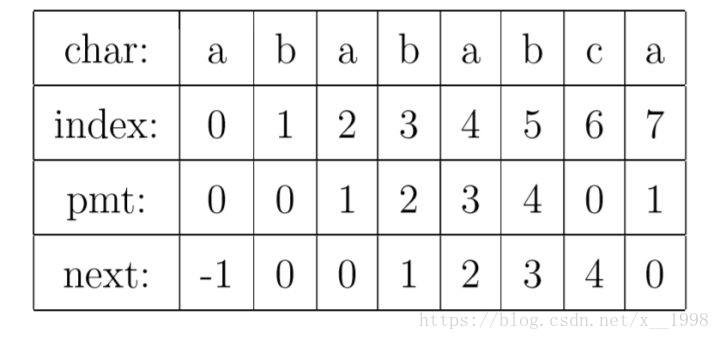
現在,我們再看一下如何程式設計快速求得next陣列。其實,求next陣列的過程完全可以看成字串匹配的過程,即以模式字串為主字串,以模式字串的字首為目標字串,一旦字串匹配成功,那麼當前的next值就是匹配成功的字串的長度。
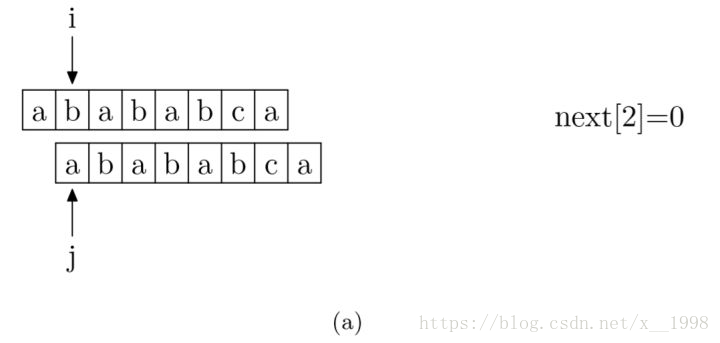
具體來說,就是從模式字串的第一位(注意,不包括第0位)開始對自身進行匹配運算。 在任一位置,能匹配的最長長度就是當前位置的next值。如下圖所示。
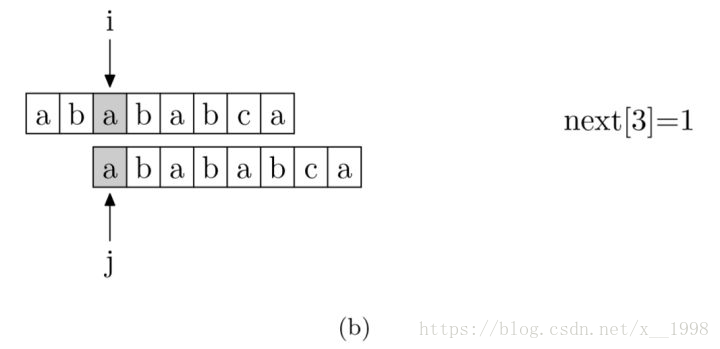
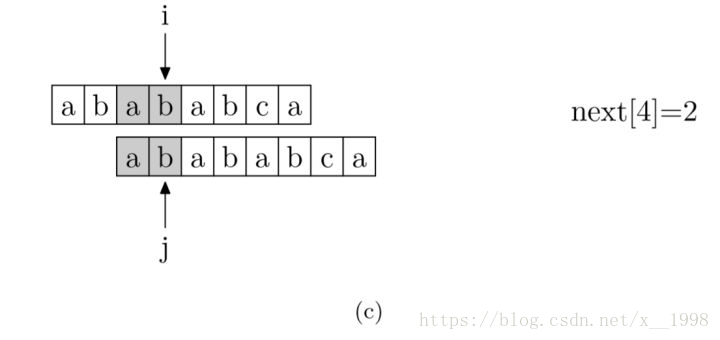
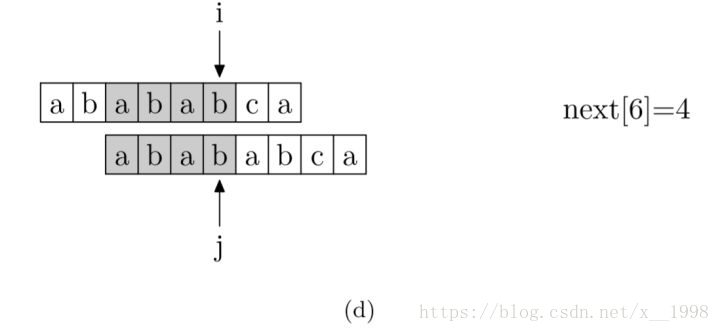
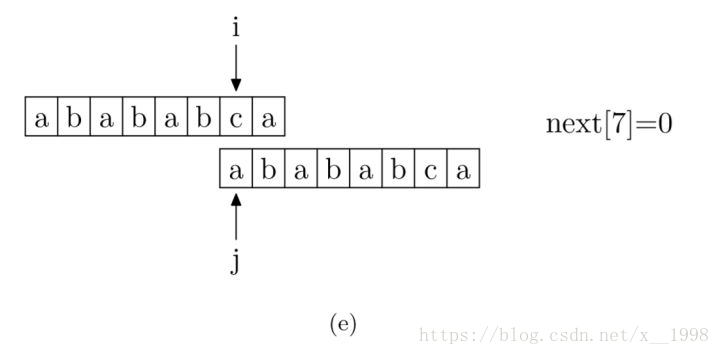
求next陣列值的程式如下所示:
void getNext(char * p, int * next)
{
next[0] = -1;
int i = 0, j = -1;
while (i < strlen(p))
{
if (j == -1 || p[i] == p[j])
{
++i;
++j;
next[i] = j;
}
else
j = next[j];
}
}連結:https://www.zhihu.com/question/21923021/answer/281346746
來源:知乎
著作權歸作者所有。商業轉載請聯絡作者獲得授權,非商業轉載請註明出處。