
hadoop原理學習——hdfs寫入資料
阿新 • • 發佈:2018-12-30
轉自:http://blog.sina.com.cn/s/blog_4aca42510102vuxo.html
Hadoop 的存在價值是什麼?Hadoop 解決的是哪些問題?簡單來講,大型企業和政府都可能會包含有大量資料, (我們可以看做是一塊巨大的豆腐)例如馬路卡口監控視訊拍攝的機動車號牌,我們如果要對如此海量的資料進行復雜的分析,還要非常快速的得到結果,如果使用一臺計算機,根本無法勝任這個工作。如果能將這個龐然大物分割成許多小的資料塊,並將其分發給許許多多的伺服器來協同計算,那麼這個效率自然是很快的,所以,Hadoop 的存在價值就體現在這裡。 例如上面那個郵件的例子,經過日積月累,我們的伺服器存有大量的郵件,我們可以將這些郵件打包成文字傳送給Hadoop 叢集,只需要編寫一個簡單的計算單詞量的函式,並提交給叢集,叢集通過相互協調,在短時間內計算完畢之後返回一個結果。我就可以得到我想要的結果了。
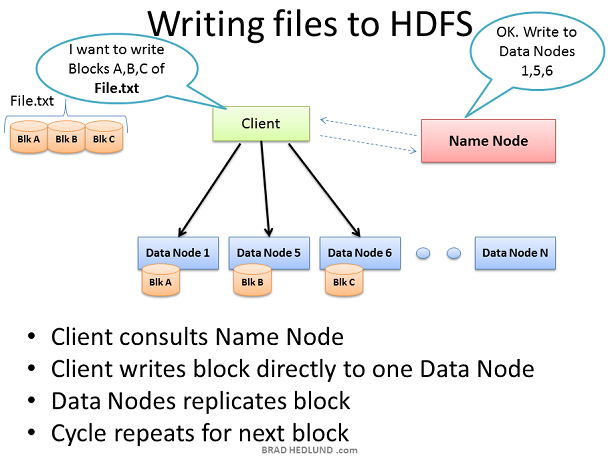
Hadoop 叢集有了資料之後,便開始工作。我們在此的目的是大量資料的快速並行處理,為了實現這個目標,我們應當利用盡可能多的機器,為此,客戶端需要將資料分揀分成較小的塊,然後將這些快在叢集中不同的機器上平行計算。但是,這些伺服器中的某些伺服器可能會出現故障,因此,應當將每個資料塊做幾次拷貝,以確保資料不會被丟失。預設的拷貝次數是3次,但是我們可以通過 hdfs-site.xml 配置檔案中 dfs.replication 這個引數來控制拷貝次數。 客戶端將 File.txt 切割成三塊,並與Name Node協調,Name Node告知客戶端將這些資料分發到哪些 Data Node 上,收到資料塊的 Data Node 將會對收到的資料塊做幾次複製分發給其他的 Data Node 讓其他的 Data Node 也來計算同樣的資料(確保資料完整性)。此時,Name Node 的作用僅僅是負責管理資料,例如:哪些資料塊正在哪個Data Node上計算,以及這些資料將會執行到哪裡。(檔案系統的元資料資訊)
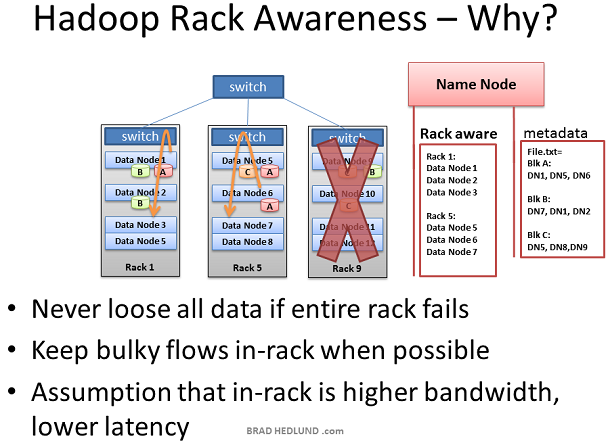
Hadoop 有“機架意識”的概念,作為 Hadoop 的管理者,你可以手動的在你的叢集中為每一個Slave Data Node定義機架號。你可能會問,我為什麼要做這個工作?這裡有兩個關鍵點:資料丟失防護以及網路效能。 記住,每一個數據塊將會被複制到多型伺服器上以確保資料不會因某個伺服器的宕機而造成資料丟失,但是如果不幸的是,所有的拷貝都存放於一臺機架上,而這個機架由於種種原因造成了整個機架與外部斷開連線或整體宕機。例如一個嚴重的錯誤:交換機損壞。因此,為了避免這種情況的發生,需要有人知道每一個 Data Node 在整個網路拓撲圖中的位置,並智慧的將資料分配到不同的機架中。這個就是 Name Node 的作用所在。 還有一種假設,即兩臺機器在同一個機架和分屬於不同的機架比起來有更好的頻寬和更低的延遲。機架交換機上行鏈路頻寬通常比下行頻寬更少,此外,在機架內延遲通常比機架外的延遲要底。如果 Hadoop 有了相同機架優化的意識(提高網路效能),同時能夠保護資料,這不是很酷嗎?
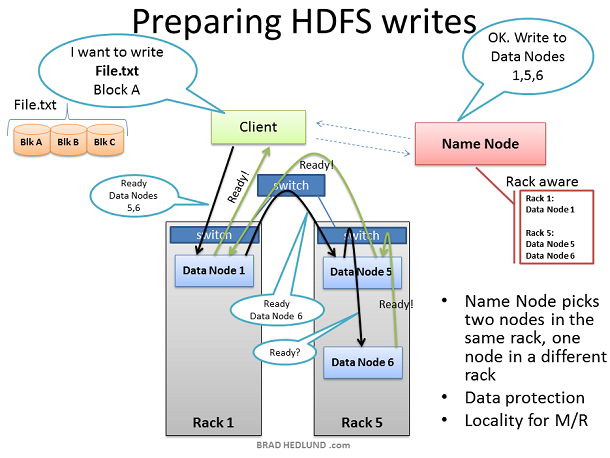
這裡的客戶端已經準備好將 FILE.txt 分成三塊新增到叢集中。客戶端會先告訴 Name Node 它將要把資料寫入到叢集中,從 Name Node處得到允許後,並受到 Name Node 為其分配的 Data Node 清單,Name Node分配 Data Node 的時候會有一個智慧決策的步驟,以預設的拷貝次數來講(3次), Name Node 會將其中兩個副本放在同一個機架中,而剩下的一個副本會放在另外一個機架中,並將分配結果告訴給客戶端,客戶端將會遵循這個分配結果將資料分配給三個 Data Node。 當客戶端接收到 Name Node 給出的任務分配清單後,開始將資料傳輸給 Data Node,例如:Client 選擇 Block A 開啟 TCP 50010 埠,告訴 Data Node 1 說:“嘿,給你一個數據塊 Block A,然後你去確保 Data Node 5 也準備好了,並讓它問問 Data Node 6 是不是也準備好了”。如此,Data Node們會通過TCP 50010 埠原路返回並逐層告知自己準備好了,最終讓客戶端得知清單上所列出的 Data Node 都準備好了。當客戶端得知都準備好之後,開始準備寫資料塊到叢集中。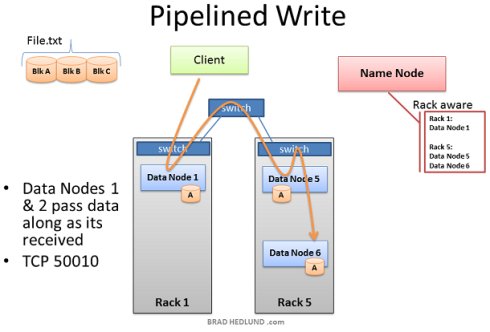
資料塊被第一個 Data Node 接收後,會將其複製給下一個 Data Node 以此類推(複製次數由 dfs.replication 引數控制)。 此處我們可以看到,Data Node 1 之所以在不同的機架上,是為了避免資料丟失,而 Data Node 5 和 Data Node 6 存在於同一個機架是為了保證網路效能和低延遲。直到 Block A 被成功的寫入到第三個節點,Block B 才會開始繼續寫入。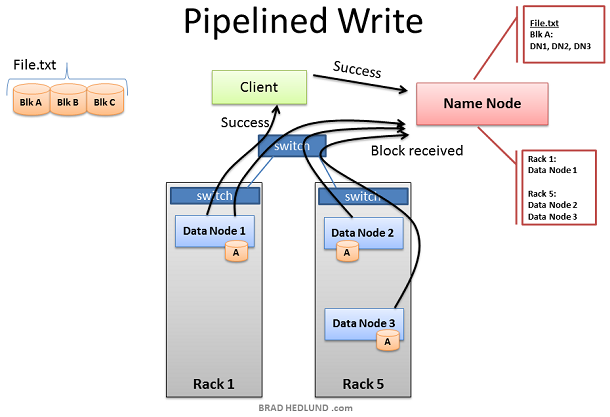
當所有的 Data Node 已經成功的接收到了資料塊,它們將會報告給 Name Node,同時也會告知客戶端一切準備就緒並關閉回話,此時客戶端也會返回一個成功的資訊給 Name Node。Name Node 開始更新元資料資訊將 Block A 在 File.txt 中的位置記錄下來。 然後重複以上操作,直到剩下的兩個資料塊 Block B和 Block C 也分別寫入到其他的 Data Node 中。
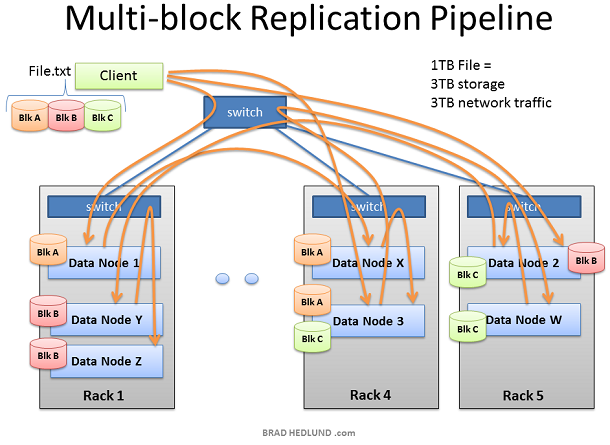
通過以上步驟我們可以得知,如果我們有一個1TB的資料要做分析,那麼我們所佔用的網路流量和磁碟空間將如下: 使用流量= 磁碟空間 = dfs.replication*資料大小 例如我們預設的設定是拷貝三次,那麼我們就需要消耗3TB的網路流量和3TB的磁碟空間。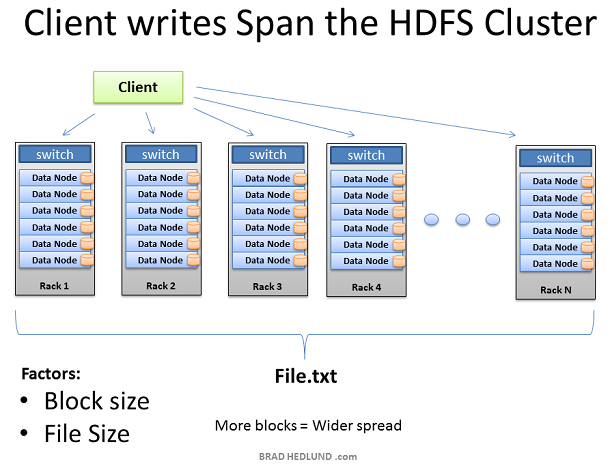
這樣,就如我們預期的那樣,將一個大的資料分割成無數小的資料提交給多個Data Node 進行平行計算。在這裡,我們可以通過橫向擴充套件增加伺服器的數量來提高計算效能,但同時,網路I/O 的吞吐也成為了計算效能瓶頸之一,因為如果橫向擴充套件,會給網路吞吐帶來巨大的壓力,如何將 Hadoop 過渡到萬兆乙太網是即將到來的難題。、
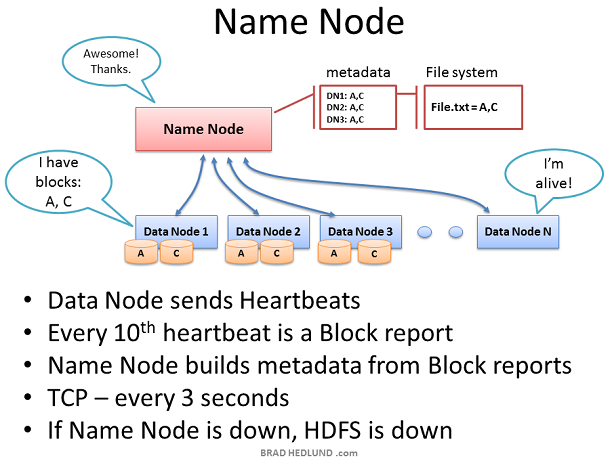
Name Node 在整個 HDFS 中處於關鍵位置,它儲存了所有的檔案系統的元資料資訊用來監控每個 Data Node 的健康狀況。只有 Name Node 知道資料從哪裡來、將要被分配到哪裡去,最後返回給誰。 Data Node 會每3秒鐘一次通過 TCP 9000埠傳送心跳給 Name Node。每10次心跳生成一個健康報告,心跳資料都會包含關於該Data Node所擁有的資料塊資訊。該報告讓 Name Node 知道不同的機架上不同的Data Node上存在的資料快的副本,併為此建立元資料資訊。 Name Node的重要性不言而喻,沒有它,客戶端將不知道如何向HDFS寫入資料和讀取結果,就不可能執行 Map Reduce 工作,因此,Name Node 所在的伺服器應當是一個比較牛逼的伺服器(熱插拔風扇、冗餘網絡卡連線、雙電源等)。 如果 Name Node 沒有接收到 Data Node 傳送過來的心跳,那麼它將會假定該 Data Node 已經死亡。因為有前面的心跳報告,因此 Name Node 知道該死亡的 Data Node 目前的工作內容以及進度,它將會將該 Data Node 所負責的內容分發給其他的 Data Node去完成。(同樣根據機架意識來分發該任務)。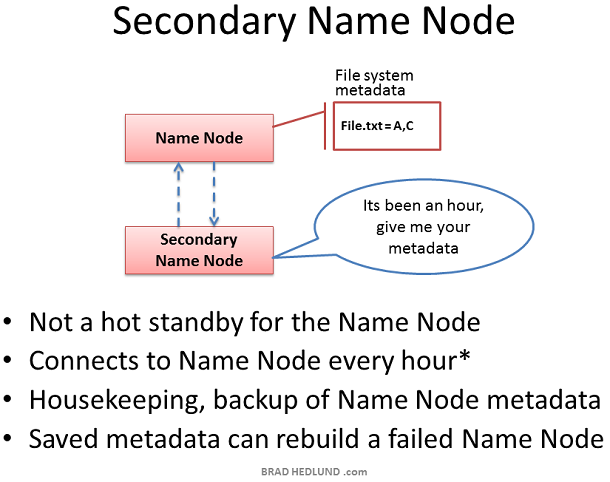
Secondary Name Node 在國內通常被稱為輔助 Name Node 因為它並不是一個完整備份, Secondary Name Node 的存在雖然是為了確保 Name Node 在宕機後能夠接手其職責,但是它與 Name Node 之間的元資料互動不是實時的。預設為每隔一小時,Secondary Name Node 會主動請求 Name Node,並從 Name Node 中拿到檔案系統的元資料資訊(同步)。這個間隔可以通過配置項來設定。 因此,如果萬一 Name Node 宕機,雖然 Secondary Name Node 能夠接手參加工作,但是依然會造成部分的資料丟失。因此,如果資料非常重要,預設的一小時同步一次可能遠遠不足以保護資料的計算進度,我們可以縮短其同步時間來增加資料的安全性例如:每分鐘同步一次。
Hadoop 的存在價值是什麼?Hadoop 解決的是哪些問題?簡單來講,大型企業和政府都可能會包含有大量資料, (我們可以看做是一塊巨大的豆腐)例如馬路卡口監控視訊拍攝的機動車號牌,我們如果要對如此海量的資料進行復雜的分析,還要非常快速的得到結果,如果使用一臺計算機,根本無法勝任這個工作。如果能將這個龐然大物分割成許多小的資料塊,並將其分發給許許多多的伺服器來協同計算,那麼這個效率自然是很快的,所以,Hadoop 的存在價值就體現在這裡。 例如上面那個郵件的例子,經過日積月累,我們的伺服器存有大量的郵件,我們可以將這些郵件打包成文字傳送給Hadoop 叢集,只需要編寫一個簡單的計算單詞量的函式,並提交給叢集,叢集通過相互協調,在短時間內計算完畢之後返回一個結果。我就可以得到我想要的結果了。
Hadoop 叢集有了資料之後,便開始工作。我們在此的目的是大量資料的快速並行處理,為了實現這個目標,我們應當利用盡可能多的機器,為此,客戶端需要將資料分揀分成較小的塊,然後將這些快在叢集中不同的機器上平行計算。但是,這些伺服器中的某些伺服器可能會出現故障,因此,應當將每個資料塊做幾次拷貝,以確保資料不會被丟失。預設的拷貝次數是3次,但是我們可以通過 hdfs-site.xml 配置檔案中 dfs.replication 這個引數來控制拷貝次數。 客戶端將 File.txt 切割成三塊,並與Name Node協調,Name Node告知客戶端將這些資料分發到哪些 Data Node 上,收到資料塊的 Data Node 將會對收到的資料塊做幾次複製分發給其他的 Data Node 讓其他的 Data Node 也來計算同樣的資料(確保資料完整性)。此時,Name Node 的作用僅僅是負責管理資料,例如:哪些資料塊正在哪個Data Node上計算,以及這些資料將會執行到哪裡。(檔案系統的元資料資訊)
Hadoop 有“機架意識”的概念,作為 Hadoop 的管理者,你可以手動的在你的叢集中為每一個Slave Data Node定義機架號。你可能會問,我為什麼要做這個工作?這裡有兩個關鍵點:資料丟失防護以及網路效能。 記住,每一個數據塊將會被複制到多型伺服器上以確保資料不會因某個伺服器的宕機而造成資料丟失,但是如果不幸的是,所有的拷貝都存放於一臺機架上,而這個機架由於種種原因造成了整個機架與外部斷開連線或整體宕機。例如一個嚴重的錯誤:交換機損壞。因此,為了避免這種情況的發生,需要有人知道每一個 Data Node 在整個網路拓撲圖中的位置,並智慧的將資料分配到不同的機架中。這個就是 Name Node 的作用所在。 還有一種假設,即兩臺機器在同一個機架和分屬於不同的機架比起來有更好的頻寬和更低的延遲。機架交換機上行鏈路頻寬通常比下行頻寬更少,此外,在機架內延遲通常比機架外的延遲要底。如果 Hadoop 有了相同機架優化的意識(提高網路效能),同時能夠保護資料,這不是很酷嗎?
這裡的客戶端已經準備好將 FILE.txt 分成三塊新增到叢集中。客戶端會先告訴 Name Node 它將要把資料寫入到叢集中,從 Name Node處得到允許後,並受到 Name Node 為其分配的 Data Node 清單,Name Node分配 Data Node 的時候會有一個智慧決策的步驟,以預設的拷貝次數來講(3次), Name Node 會將其中兩個副本放在同一個機架中,而剩下的一個副本會放在另外一個機架中,並將分配結果告訴給客戶端,客戶端將會遵循這個分配結果將資料分配給三個 Data Node。 當客戶端接收到 Name Node 給出的任務分配清單後,開始將資料傳輸給 Data Node,例如:Client 選擇 Block A 開啟 TCP 50010 埠,告訴 Data Node 1 說:“嘿,給你一個數據塊 Block A,然後你去確保 Data Node 5 也準備好了,並讓它問問 Data Node 6 是不是也準備好了”。如此,Data Node們會通過TCP 50010 埠原路返回並逐層告知自己準備好了,最終讓客戶端得知清單上所列出的 Data Node 都準備好了。當客戶端得知都準備好之後,開始準備寫資料塊到叢集中。
資料塊被第一個 Data Node 接收後,會將其複製給下一個 Data Node 以此類推(複製次數由 dfs.replication 引數控制)。 此處我們可以看到,Data Node 1 之所以在不同的機架上,是為了避免資料丟失,而 Data Node 5 和 Data Node 6 存在於同一個機架是為了保證網路效能和低延遲。直到 Block A 被成功的寫入到第三個節點,Block B 才會開始繼續寫入。
當所有的 Data Node 已經成功的接收到了資料塊,它們將會報告給 Name Node,同時也會告知客戶端一切準備就緒並關閉回話,此時客戶端也會返回一個成功的資訊給 Name Node。Name Node 開始更新元資料資訊將 Block A 在 File.txt 中的位置記錄下來。 然後重複以上操作,直到剩下的兩個資料塊 Block B和 Block C 也分別寫入到其他的 Data Node 中。
通過以上步驟我們可以得知,如果我們有一個1TB的資料要做分析,那麼我們所佔用的網路流量和磁碟空間將如下: 使用流量= 磁碟空間 = dfs.replication*資料大小 例如我們預設的設定是拷貝三次,那麼我們就需要消耗3TB的網路流量和3TB的磁碟空間。
這樣,就如我們預期的那樣,將一個大的資料分割成無數小的資料提交給多個Data Node 進行平行計算。在這裡,我們可以通過橫向擴充套件增加伺服器的數量來提高計算效能,但同時,網路I/O 的吞吐也成為了計算效能瓶頸之一,因為如果橫向擴充套件,會給網路吞吐帶來巨大的壓力,如何將 Hadoop 過渡到萬兆乙太網是即將到來的難題。、
Name Node 在整個 HDFS 中處於關鍵位置,它儲存了所有的檔案系統的元資料資訊用來監控每個 Data Node 的健康狀況。只有 Name Node 知道資料從哪裡來、將要被分配到哪裡去,最後返回給誰。 Data Node 會每3秒鐘一次通過 TCP 9000埠傳送心跳給 Name Node。每10次心跳生成一個健康報告,心跳資料都會包含關於該Data Node所擁有的資料塊資訊。該報告讓 Name Node 知道不同的機架上不同的Data Node上存在的資料快的副本,併為此建立元資料資訊。 Name Node的重要性不言而喻,沒有它,客戶端將不知道如何向HDFS寫入資料和讀取結果,就不可能執行 Map Reduce 工作,因此,Name Node 所在的伺服器應當是一個比較牛逼的伺服器(熱插拔風扇、冗餘網絡卡連線、雙電源等)。 如果 Name Node 沒有接收到 Data Node 傳送過來的心跳,那麼它將會假定該 Data Node 已經死亡。因為有前面的心跳報告,因此 Name Node 知道該死亡的 Data Node 目前的工作內容以及進度,它將會將該 Data Node 所負責的內容分發給其他的 Data Node去完成。(同樣根據機架意識來分發該任務)。
Secondary Name Node 在國內通常被稱為輔助 Name Node 因為它並不是一個完整備份, Secondary Name Node 的存在雖然是為了確保 Name Node 在宕機後能夠接手其職責,但是它與 Name Node 之間的元資料互動不是實時的。預設為每隔一小時,Secondary Name Node 會主動請求 Name Node,並從 Name Node 中拿到檔案系統的元資料資訊(同步)。這個間隔可以通過配置項來設定。 因此,如果萬一 Name Node 宕機,雖然 Secondary Name Node 能夠接手參加工作,但是依然會造成部分的資料丟失。因此,如果資料非常重要,預設的一小時同步一次可能遠遠不足以保護資料的計算進度,我們可以縮短其同步時間來增加資料的安全性例如:每分鐘同步一次。