
R語言︱機器學習模型評價指標+(轉)模型出錯的四大原因及如何糾錯
筆者寄語:機器學習中交叉驗證的方式是主要的模型評價方法,交叉驗證中用到了哪些指標呢?
交叉驗證將資料分為訓練資料集、測試資料集,然後通過訓練資料集進行訓練,通過測試資料集進行測試,驗證集進行驗證。
模型預測效果評價,通常用相對絕對誤差、平均絕對誤差、根均方差、相對平方根誤差等指標來衡量。
只有在非監督模型中才會選擇一些所謂“高大上”的指標如資訊熵、複雜度和基尼值等等。
其實這類指標只是看起來老套但是並不“簡單”,《資料探勘之道》中認為在監控、評估監督模型時還是一些傳統指標比較靠譜,例如平均絕對誤差(MAE)、平均平方差(MSE)、標準平均方差(NMSE)和均值等,計算簡單、容易理解;
三者各有優缺點,就單個模型而言,
——————————————————————————
相關內容:
——————————————————————————
1、絕對誤差與相對誤差
絕對誤差(AbsoluteError)=原值-估計值
相對誤差(RelativeError)=(原值-估計值)/原值
2、平均絕對誤差(MeanAbsoluteError , MAE)
平均絕對誤差=︱原值-估計值︱/n
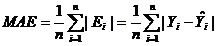
其中n代表資料個數,相當於誤差絕對值的加權平均值。
由於預測誤差有正有負,為了避免正負相抵消,故取誤差的絕對值進行綜合並取其平均數,這是誤差分析的綜合指標法之一。
優缺點:雖然平均絕對誤差能夠獲得一個評價值,但是你並不知道這個值代表模型擬合是優還是劣,只有通過對比才能達到效果;
3、均方誤差(MeanSquaredError , MSE)≈方差
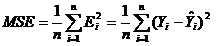
跟方差一樣,均方誤差是預測誤差平方之和的平均數,它避免了正負誤差不能相加的問題。
由於對誤差進行了平方,加強了數值大的誤差在指標中的作用,從而提高了這個指標的靈敏性,是一大優點。均方誤差是誤差分析的綜合指標法之一。
優缺點:均方差也有同樣的毛病,而且均方差由於進行了平方,所得值的單位和原預測值不統一了,比如觀測值的單位為米,均方差的單位就變成了平方米,更加難以比較。
4、均方根誤差(RootMeanSquaredError , RMSE)≈標準差
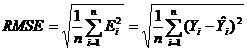
這是均方誤差的平方根,代表了預測值的離散程度,也叫標準誤差,最佳擬合情況為。均方根誤差也是誤差分析的綜合指標之一。
優點:標準化平均方差對均方差進行了標準化改進,通過計算擬評估模型與以均值為基礎的模型之間準確性的比率,標準化平均方差取值範圍通常為0~1,比率越小,說明模型越優於以均值進行預測的策略,
NMSE的值大於1,意味著模型預測還不如簡單地把所有觀測值的平均值作為預測值,
缺點:但是通過這個指標很難估計預測值和觀測值的差距,因為它的單位也和原變數不一樣了,綜合各個指標的優缺點,我們使用三個指標對模型進行評估。
5、平均絕對百分誤差(MeanAbsolute PercentageError , MAPE)≈標準差
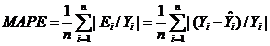
跟上面的均方根誤差有點相似。
6、混淆矩陣(Confusion Matrix)
對角線元素=分類器正確識別的百分率,而非對角線元素=錯誤判斷的百分率。
| 混淆矩陣表 | 預測類 | ||
| 類=1 | 類=0 | ||
| 實際類 | 類=1 | A | B |
| 類=0 | C | D | |
7、受試者工作特性(Receiver Operating Characteristic,ROC)曲線
一種非常有效的模型評價方法,可為選定臨界值給出定量提示。
該曲線下的積分面積(Area)大小與每種方法優劣密切相關,反映分類器正確分類的統計概率,其值越接近1說明該演算法效果越好。
分類器演算法最後都會有一個預測精度,而預測精度都會寫一個混淆矩陣,所有的訓練資料都會落入這個矩陣中,而對角線上的數字代表了預測正確的數目,即True Positive+True Nagetive。
同時可以相應算出TPR(真正率或稱為靈敏度)和TNR(真負率或稱為特異度)。
我們主觀上希望這兩個指標越大越好,但可惜二者是一個此消彼漲的關係。除了分類器的訓練引數,臨界點的選擇,也會大大的影響TPR和TNR。有時可以根據具體問題和需要,來選擇具體的臨界點。
————————————————————————————————————
(轉)模型出錯的四大原因及如何糾錯
可供選擇的機器學習模型並不少。我們可以用線性迴歸來預測一個值,用邏輯迴歸來對不同結果分類,用神經網路來對非線性行為建模。
我們建模時通常用一份歷史資料讓機器學習模型學習一組輸入特性的關係,以預測輸出。但即使這個模型能準確預測歷史資料中的某個值,我們怎麼知道它是否能同樣準確地預測新的資料呢?
簡而言之,如何評估一個機器學習模型是否真的“好”呢?
在這篇文章裡,我們將介紹一些看似很好的機器學習模型依然會出錯的常見情況, 討論如何用偏差(bias)vs 方差 (variance),精確率 (precision)vs 召回率(recall)這樣的指標來評估這些模型問題, 並提出一些解決方案以便你在遇到此類情況時使用。
高偏差還是高方差
檢驗一個機器學習模型時要做的第一件事就是看是否存在“高偏差(High Bias)”或“高方差(High Variance)”。
高偏差指的是你的模型對實驗資料是否“欠擬合(underfitting)”(見上圖)。高偏差是不好的,因為你的模型沒有非常準確或者有代表性地反映輸入值和預測的輸出值之間的關係, 而且經常輸出高失誤的值(例如模型預測值與真實值之間有差距)。
高方差則指相反情況。出現高方差或者“過擬合”時, 機器學習模型過於準確,以至於完美地擬合了實驗資料。這種結果看上去不錯,但需引起注意,因為這樣的模型往往無法適用於未來資料。所以儘管模型對已有資料執行良好,你並不知道它在其他資料上能執行得怎樣。
那怎樣才能知道自己的模型是否存在高偏差或是高方差呢?
一種直接了當的方法就是把資料一分為二:訓練集和測試集。例如把模型在 70% 的資料上做訓練,然後用剩下的 30% 資料來測量失誤率。如果模型在訓練資料和測試資料上都存在著高失誤,那這個模型在兩組資料都欠擬合,也就是有高偏差。如果模型在訓練集上失誤率低,而在測試集上失誤率高,這就意味著高方差,也就是模型無法適用於第二組資料。
如果模型整體上在訓練集(過往資料)和測試集(未來資料)上都失誤率較低,你就找到了一個“正好”的模型,在偏差度和方差度間達到了平衡。
低精確率還是低召回率
即使機器學習模型準確率很高,也有可能出現其他型別的失誤。
以將電子郵件分類為垃圾郵件(正類別 positive class)和非垃圾郵件(負類別 negative class)為例。99% 的情況下, 你收到的郵件都並非垃圾郵件,但可能有1% 是垃圾郵件。假設我們訓練一個機器學習模型,讓它學著總把郵件預測為非垃圾郵件(負類別), 那這個模型 99% 的情況下是準確的,只是從未捕獲過正類別。
在這種情況下,用兩個指標——精準率和召回率來決定究竟要預測多少百分比的正類別就很有幫助了。

精準率是測量正類別多常為真, 可以通過計算“真正(true positive, 例如預測為垃圾郵件且真的為垃圾郵件)”與“真負(true negative, 例如預測為垃圾郵件但事實並非如此)”總和中“真正”的個數而得出。
召回率則用來測量實際上的正類別多常被準確預測, 以計算真正與假負(false negative, 例如預測郵件為非垃圾郵件,但事實上郵件是垃圾郵件)的總和裡有多少個真正而得出。
另一種理解精確率與召回率區別的方法是,精確率測量的是對正類別的預測中有多少比例成真,而召回率則告訴你預測中多常能真正捕獲到正類別。因此,當正類別預測為真的情況很少時, 就出現了低精確率,當正類別很少被預測到的時候,就出現了低召回率。
一個良好的機器學習模型目標在於,通過試圖最大化“真正”的數量以及最小化“假負”和“假正”的數量來實現精確率與召回率的平衡(如上圖所示)。
5 種改進模型的方法
如果模型面臨高偏差 vs. 高方差的問題,或者在精確率和召回率之間難以平衡,有幾種策略可以採用。
比如機器學習模型出現高偏差時,你可以試試增加輸入特徵(input feature)的數量。上文已討論過,高偏差出現於模型對背後的資料欠擬合時,在訓練集和測試集都會出現高失誤率。如果把模型的失誤以基於輸入特徵個數的函式畫出(見上圖), 我們發現特徵越多,模型的擬合度越好。
同理,對於高方差,你可以減少輸入特徵的數量。如果模型對訓練資料過擬合,有可能是你用了太多特徵,減少輸入特徵的數量會使模型對測試或者未來資料更靈活 。同樣,增加訓練樣本的數量對高方差也是有益的, 這會幫助機器學習演算法建出一個更通用的模型。
對要平衡低精確率與低召回率的情況,你可以調整區分正負類別的概率臨界值(probability threshold)。對低精確率可以提高概率臨界值,以使模型在指定正類別時更為保守。反之,遇到低召回率時可以降低概率臨界值,以能更常預測到正類別。
經過足夠迭代,就很有可能找到一個能平衡偏差與方差,精確率與召回率的合適的機器學習模型了。
本文是基於 Andrew Ng 在 Coursera 上的斯坦福機器學習課程筆記裡教授的概念。
原文地址:http://www.kdnuggets.com/2016/12/4-reasons-machine-learning-model-wrong.html
