
Python與自然語言處理(一)搭建環境
阿新 • • 發佈:2018-12-30
參考書籍《Python自然語言處理》,書籍中的版本是Python2和NLTK2,我使用的版本是Python3和NLTK3
安裝NLTK3,Natural Language Toolkit,自然語言工具包
安裝命令:pip install nltk
安裝完成後測試:import nltk
沒有報錯即表明安裝成功。
下載NLTK-Data,在Python中輸入命令:
>>>import nltk
>>>nltk.download()
彈出新的視窗,用於選擇下載的資源

點選File可以更改下載安裝的路徑。all表示全部資料集合,all-corpora表示只有語料庫和沒有語法或訓練的模型,book表示只有書籍中例子或練習的資料。需要注意一點,就是資料的儲存路徑,要麼在C盤中,要麼在Python的根目錄下,否則後面程式呼叫資料的時候會因為找不到而報錯。
【注意:軟體安裝需求:Python、NLTK、NLTK-Data必須安裝,NumPy和Matplotlin推薦安裝,NetworkX和Prover9可選安裝】
簡單測試NLTK分詞功能:

但是在詞性標註上就出現問題了,百度也沒有明確的解決辦法,若有大神知道是什麼原因請不吝賜教!

詞性標註功能就先暫且放一放。
下面看一下NLTK資料的幾種方法:
1.載入資料
from nltk.book import *
2.搜尋文字
print(text1.concordance('monstrous'))
3.相似文字
print(text1.similar('monstrous'))
4.共用詞彙的上下文
print(text2.common_contexts(['monstrous','very']))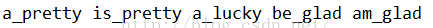
5.詞彙分佈圖
text4.dispersion_plot(['citizens','democracy','freedom','duties','America'])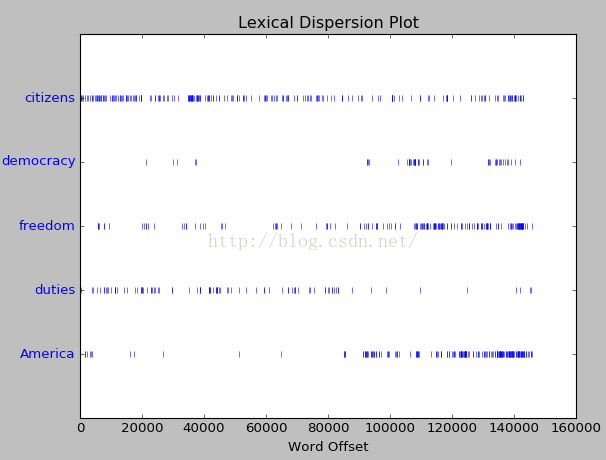
6.詞彙統計
#encoding=utf-8 import nltk from nltk.book import * print('~~~~~~~~~~~~~~~~~~~~~~~~~') print('文件text3的長度:',len(text3)) print('文件text3詞彙和識別符號排序:',sorted(set(text3))) print('文件text3詞彙和識別符號總數:',len(set(text3))) print('單個詞彙平均使用次數:',len(text3)*1.0/len(set(text3))) print('單詞 Abram在text3中使用次數:',text3.count('Abram')) print('單詞Abram在text3中使用百分率:',text3.count('Abram')*100/len(text3))

暫時先練習到這裡,基本上對NLTK-Data有了一定的瞭解,以及學會了其基本使用方法。