
自然語言處理(一)
阿新 • • 發佈:2019-01-29
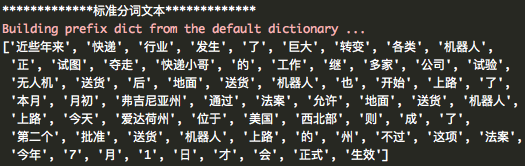
1、計算jieba和thula的P,R,F值。基於文字‘express.txt’,標準文字是人工切分。
基本計算公式:
精度(Precision)、召回率(Recall)、F值(F-mesure)。
N :標準分割的單詞數e :分詞器錯誤標註的單詞數c :分詞器正確標註的單詞數
P = c/N R = c/(c+e) F = 2*R*P/(R+P)
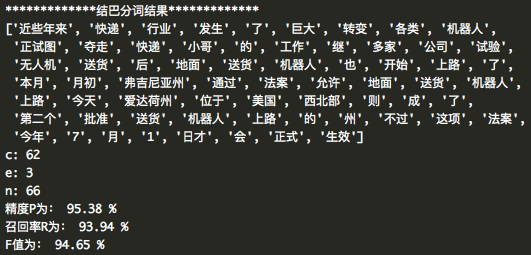
結巴分詞的使用函式:s1 = list(jieba.cut(f))清華分詞的使用函式:
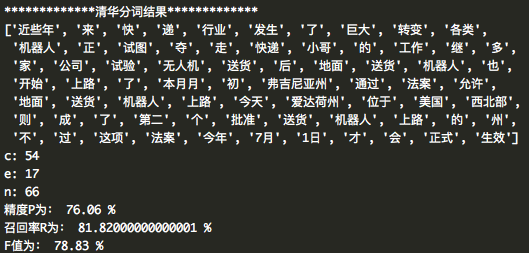
thu1=thulac.thulac(seg_only=True)
s_2 = thu1.cut(f, text=True)程式設計思路
- 讀取標準文字,建立詞典(資料型別為list),去除文字中的標點符號,計算n值
- 通過jieba進行分詞,jieba分詞後可直接生成list,刪除文字中的標點符號,將jieba分詞的結果與詞典進行對比,遍歷jieba分詞結果中的每個詞,若詞典中有,則c+1,若沒有,則e+1,最後計算P、R、F值,輸出結果
- 通過清華分詞,清華分詞後的結果為一個字串,用空格隔開,先通過一個迴圈將字串中的詞分割開,存入list中,再刪除list中的標點符後,其餘步驟與jieba分詞相同
- 將P、R、F的計算過程寫成函式,簡化程式碼
結果
程式碼
#!/usr/bin/env python # -*- coding:utf-8 -*- #Date:2018/3/26 19:07 #__Author__:cimoko #File Name:lesson_3_1.py import jieba import re import thulac def P_R_F(n, c, e): R = round(c / n, 4) P = round(c / (c + e), 4) F = round(2*P*R / (P + R), 4) print("精度P為:", P * 100, '%') print("召回率R為:", R * 100, '%') print("F值為:", F * 100, '%') return P, R, F f = str(open("express.txt").readlines()) #print(f) #標準文字 raw = open('express_cut.txt').readlines() d=[re.split(r' |\n',w)[0] for w in raw] dict = [] for w in d: if w == r',' or w == r'。' or w == r'('or w == r')': pass else: dict.append(w) print('*************標準分詞文字*************') print(dict) n = len(dict) #結巴 s1 = list(jieba.cut(f)) s_jieba = [] for w in s1: if w == r',' or w == r'。' or w == r'('or w == r')'or w == r'['or w == r']'or w == r"'": pass else: s_jieba.append(w) #print(s_jieba) e_jieba = 0 c_jieba = 0 for i in range(len(s_jieba)): if s_jieba[i] in dict: c_jieba += 1 else: e_jieba += 1 print('*************結巴分詞結果*************') print(s_jieba) print('c:',c_jieba) print('e:',e_jieba) print('n:',n) P_R_F(n, c_jieba, e_jieba) #清華 thu1=thulac.thulac(seg_only=True) s_2 = thu1.cut(f, text=True) s2=[] #print(s_2) s_qinghua = [] a=0 for i in range(len(s_2)): if s_2[i] == ' ': s2.append(s_2[a:i]) a = i+1 else: continue for w in s2: if w == r',' or w == r'。' or w == r'('or w == r')'or w == r'['or w == r']'or w == r"'": pass else: s_qinghua.append(w) #print(s_qinghua) e_qinghua = 0 c_qinghua = 0 for i in range(len(s_qinghua)): if s_qinghua[i] in dict: c_qinghua += 1 else: e_qinghua += 1 print('*************清華分詞結果*************') print(s_qinghua) print('c:',c_qinghua) print('e:',e_qinghua) print('n:',n) P_R_F(n, c_qinghua, e_qinghua)