
Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks 論文閱讀
阿新 • • 發佈:2018-12-30
一、概述
本文提出了一個多工的人臉檢測模型,可以同時進行人臉檢測和人臉特徵點提取。這個框架主要由三個CNN級聯的方式實現。
- stage1:通過一個淺的CNN來產生一些候選框
- stage2:通過一個較複雜的CNN,對候選框進一步刪選得到更精細的區域
- stage3:通過一個強大的CNN,對結果進一步處理,輸出人臉邊框和5個特徵點位置
二、實現細節

具體的實現過程如上圖所示,總的來說分為四個部分
- 給定一張圖片,首先更改圖片的大小以建立影象金字塔,這作為模型的資料輸入
- 通過一個全卷積網路(P-Net),生成候選框和bounding box regression vectors,使用bounding box regression vectors校準這些候選框,使用NMS合併重疊候選框
- 上層所有的候選框會被傳給當前網路(R-Net),這會進一步篩選,再使用bounding box regression vectors和NMS
- 和上面類似,使用O-Net輸出最終的人臉框和特徵點位置
CNN結構:

三、訓練
演算法需要實現三個任務,分別是人臉與非人臉分類,bounding box 迴歸,人臉特徵點定位
1.人臉與非人臉分類
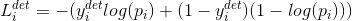
類似於交叉熵損失函式,這裡的y表示ground_truth label,p表示網路結果輸出是人臉的概率。
2.bounding box迴歸
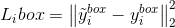
這裡的
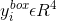
3.人臉特徵點定位
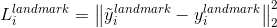
這裡的
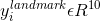
4.多目標訓練

這裡的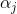
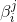
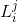
這裡在P-Net和R-Net使用了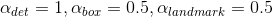
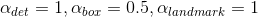
這裡資料集分類以下四個類別
- Positive
- Negative
- Part faces
- Landmark face
其中Negative和Positive用於人臉分類,Positive和Part faces用於bounding box迴歸,Landmark用於特徵點定位。