
【OverFeat】《OverFeat:Integrated Recognition, Localization and Detection using Convolutional Networks》

ICLR-2014
全稱為「International Conference on Learning Representations」(國際學習表徵會議),由位列深度學習三大巨頭之二的 Yoshua Bengio 和 Yann LeCun 牽頭創辦。詳細介紹可以參考才辦了五年的 ICLR,為何被譽為“深度學習的頂級會議”?| ICLR 2017。
對於用卷積神經網路進行影象目標的分類問題,我們要明白一些相關東西。
一個訓練好的卷積神經網路,它的相關的引數是固定的對吧, 引數都存在這些地方:第一,卷積核,所以呢,卷積層中的 feature map的個數是固定的,但是它的大小不是固定的哦。 第二就是網路中的全連線層
以上說的為常用的卷積神經網路。 不過有一種 fully-convnet 可以不受這個限制,它的做法就是把網路的後面的全連線層看層為卷積層來對待。這樣,我們在測試時,就可以 multi-scale 的輸入了。
目錄
1 Abstract
- one CNN model(Overfeat),three tasks:
- classification
- localization
- detection
- multi-scales and sliding window(feature map)
- localization & detection by
- predict object bounding boxes
- accumulation not suppression to increase detection confidence(好處:無需做背景樣本的訓練、避免耗時複雜的抽樣訓練,讓模型聚焦positive class 提高預測精度)
2 Motivation
面臨的問題:
- While images from the ImageNet classification dataset are largely chosen to contain a roughly centered object that fills much of the image, objects of interest sometimes vary significantly in size and position within the image.
idea有三個:
CNN with a sliding window fashion, and over multiple scales,但是如果window抓住 a perfectly identifiable portion of the object(比如狗的頭部),This leads to decent classification but poor localization and detection.
train the system to not only produce a distribution over categories for each window, but also to produce a prediction of the location and size of the bounding box containing the object relative to the window.
accumulate the evidence for each category at each location and size.
本文首次
provide a clear explanation how ConvNets can be used for localization and detection for ImageNet data.
3 Advantages
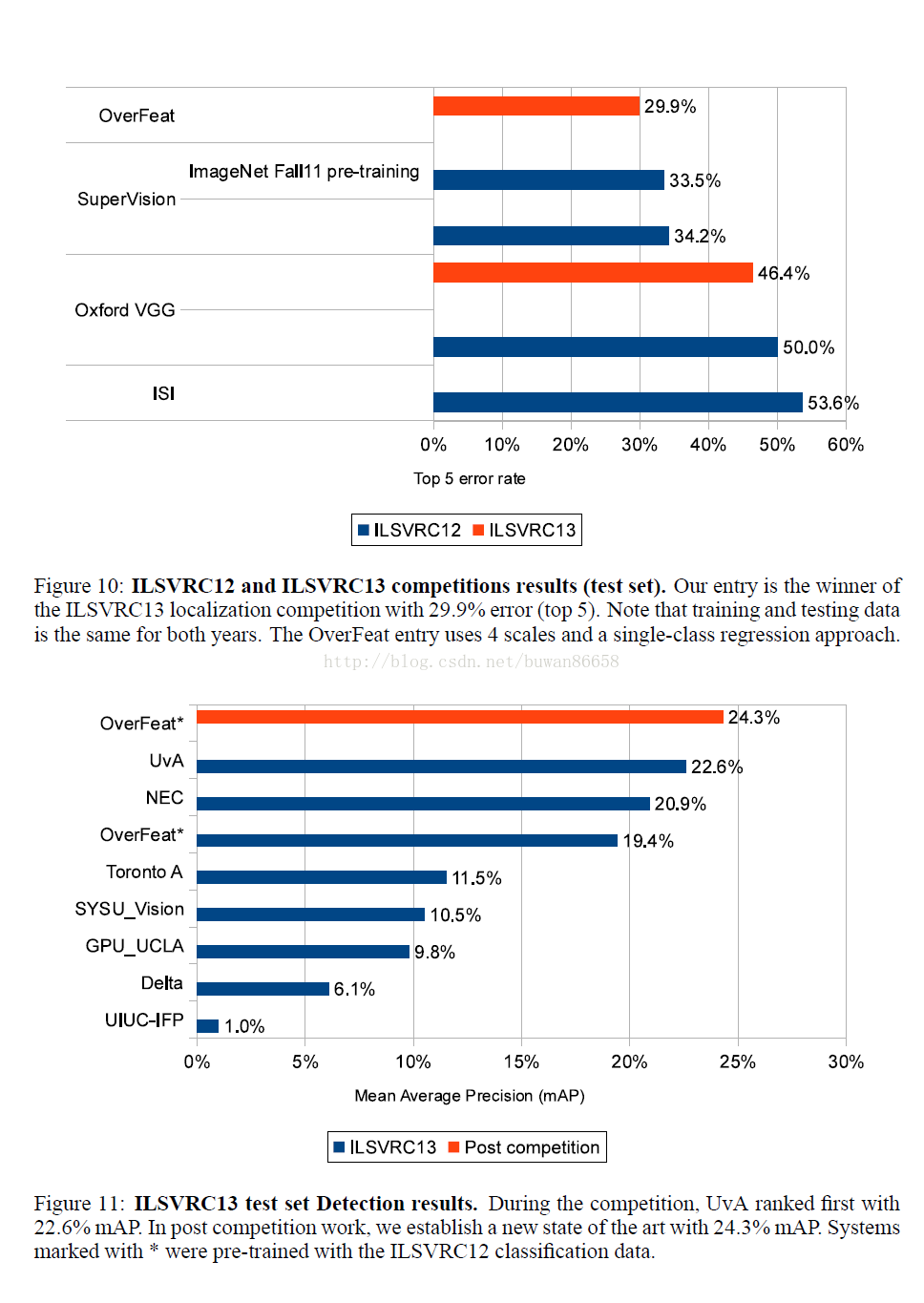
ILSVRC 2013 datasets, ranks 4th in classification, 1st in localization and 1st in detection
explaining how ConvNets can be effectively used for detection and localization tasks
4 Methods
4.1 Vision Tasks
- classification:for a image, assign a category
- localization: you know ahead of time that there is one object, we’re gong to make classification decision and give produce exactly one bounding box
- detection: there exists some fixed set of categories, given a image, we want to find all objects in that set of categories, and give bounding box and category label for each object,(we don’t konw ahead of time how many objects to find)



4.2 Classification
4.2.1 Model Design
基於AlexNet 改進
Feature Extractor(layers 1-5) + Multi-Scale Classification(layers 6-output)
- fast model
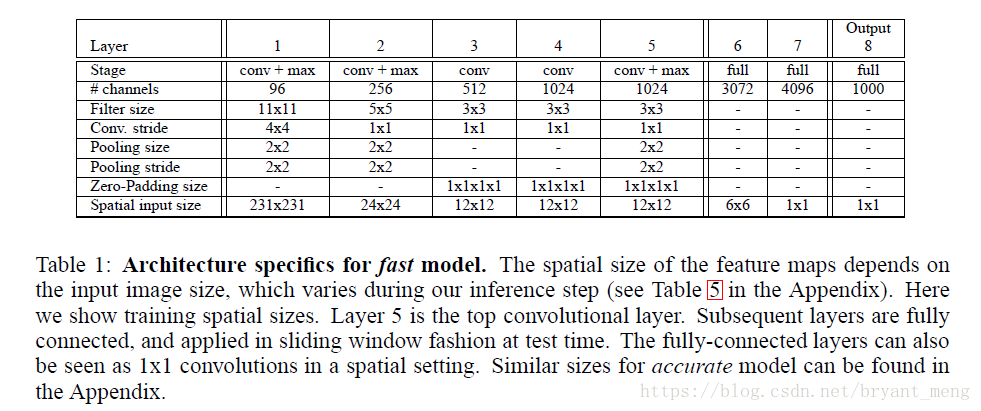
1)不使用LRN;
2)不使用over-pooling使用普通pooling;
3)第3,4,5卷基層特徵數變大,從AlexNet 的 384→384→256;變為512→1024→1024.
4)fc-6層神經元個數減少,從4096 變為 3072
- accuracy model

1) 不使用LRN;
2)不使用over-pooling,使用普通pooling,更大的pooling間隔 S=2 或 3
3)第一個卷基層的間隔從4變為2(accurate 模型),卷積大小從11*11變為7*7;第二個卷基層filter從5*5升為7*7
4)增加了一個第三層,是的卷積層變為6層;從Alex-net的 384→384→256;變為512→512→1024→1024.
關於stride,需要注意,stride大雖然有利於速度,但會損害準確性。
4.2.2 Training
回顧 Alexnet的訓練、測試:
1) 訓練階段:每張訓練圖片256*256,然後我們隨機裁剪出224*224大小的圖片,作為CNN的輸入進行訓練。
2) 測試階段:輸入256*256大小的圖片,我們從圖片的5個指定的方位(上下左右+中間)進行裁剪出5張224*224大小的圖片,然後水平映象一下再裁剪5張,這樣總共有10張;然後我們把這10張裁剪圖片分別送入已經訓練好的CNN中,分別預測結果,最後用這10個結果的平均作為最後的輸出。
overfeat這篇文獻的圖片分類演算法,在訓練階段採用與Alexnet相同的訓練方式,然而在測試階段可是差別很大
OverFeat
1)訓練:對於每張原圖片為256*256,然後進行隨機裁剪為221*221的大小作為CNN輸入,進行訓練。
2)測試:多尺度+offset-max pooling
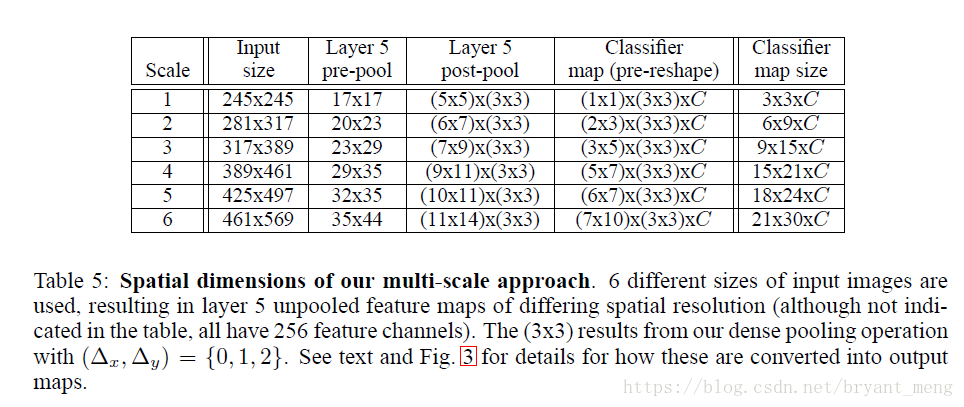
layer5 pre-pooling → layer5 post-layer,過程如下,以一維為例:
輸入20畫素(layers 1-5 提取出來的 feature map 的長或者寬)
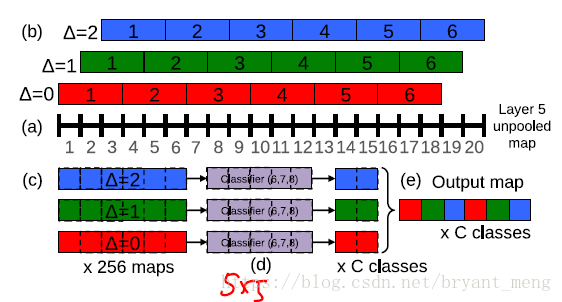
- 從第一個畫素開始(△=0)經過 size為3,stride 為3 的 max pooling 後,結果為 6(圖中(c)紅色) ,餘下的兩個畫素(19、20)扔掉
- 從第二個畫素開始(△=1)經過 size為3,stride 為3 的 max pooling 後,結果為 6 (圖中(c)綠色),餘下的兩個畫素(1、20)扔掉
- 從第三個畫素開始(△=2)經過 size為3,stride 為3 的 max pooling 後,結果為 6(圖中(c)藍色) ,餘下的兩個畫素(1、2)扔掉
一個維度 offset max-pooling 後有三個結果,兩個維度(picture)就有 3X3 個結果,這就對應 table5 中的(3*3),之後經過 layer 6-8 層 輸出結果,layer 6-8相當於一個 5*5 的卷積核(圖中(d),一維就是5),所以,6個畫素經過一個 5 的卷積後,會輸出 2,把輸出的3個2結合一下就是圖中的(e)了。
明白了offset之後,再回過頭來看測試的表
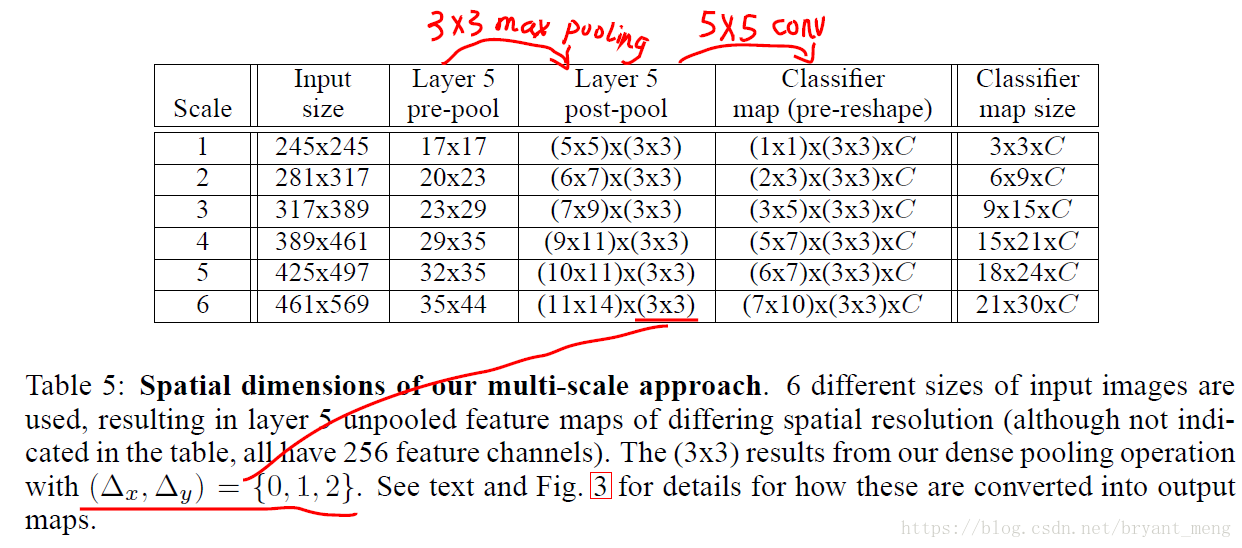
- scale1:(17-2)/ 3 = 5,5 卷積(核大小5,步長1) 後 為 1
- scale2:(20-2)/ 3 = 6,6 卷積(核大小5,步長1) 後 為 2,(23-2)/ 3 = 7,7 卷積(核大小5,步長1) 後 為 3
後面類似,就不一一列舉了,最終把所有的預測結果平均一下即可
上圖中(c)到(d)的過程,是 layer6-layer8的過程,具體如下,我們稱之為(FCN)
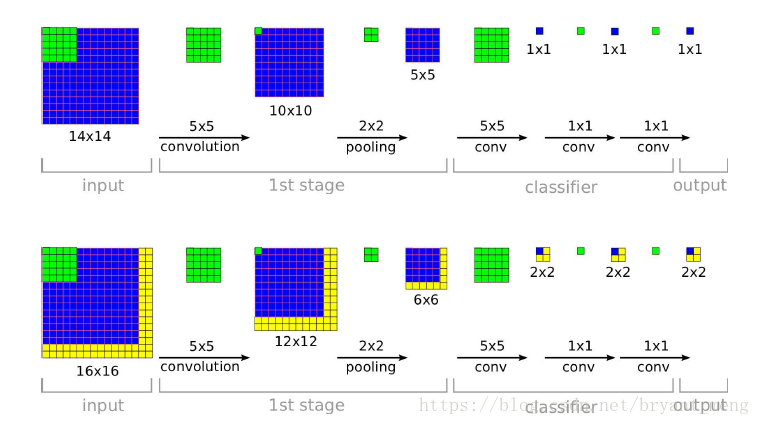
核心就是把全連線層換成了conv層,這樣就是很好的適應 multi-scale
原來CNN

fully-convnet

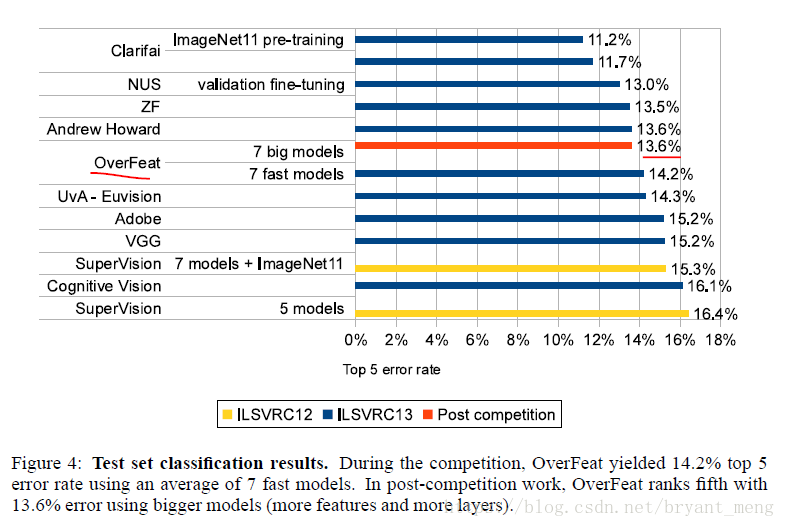
4.2.3 Resuls

6-scalse fine steps 表現最好
4.3 Localization
4.3.1 Generating Predictions
To generate object bounding box predictions, we simultaneously run the classifier and regressor networks across all locations and scales. Since these share the same feature extraction layers, only the final regression layers need to be recomputed after computing the classification network.
4.3.2 Regressor Training
定位問題的模型也是一個CNN,1-5層作為特徵提取層和分類問題完全一樣,後面接兩個全連線層(4096*1024→輸出4),組成regressor network。訓練時,前面5層的引數由classification network給定,只需要訓練後面的兩個全連線層。這個regressor network的輸出就是一個bounding box,也就是說,如果將一幅影象或者一個影象塊送到這個regressor network中,那麼,這個regressor network 輸出一個相對於這個影象或者影象塊的區域,這個區域中包含感興趣的物體。
對於定位問題,測試時,在每一個尺度上同時執行classification network和regressor network。這樣,對於每一個尺度來說,classification network給出了影象塊的類別的概率分佈,regressornetwork進一步為每一類給出了一個bounding box,這樣,對於每一個bounding box,就有一個置信度與之對應。最後,綜合這些資訊,給出定位結果。
我們把用圖片分類學習的特徵提取層的引數固定下來,然後繼續訓練後面的迴歸層的引數,網路包含了4個輸出,對應於bounding box的上左上角點和右下角點,然後損失函式採用歐式距離L2損失函式。
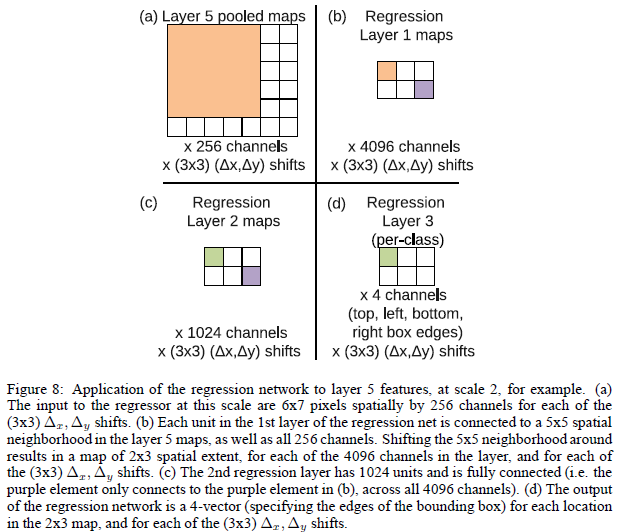
如上圖所示,每個迴歸網路,以最後一個卷積層作為輸入,迴歸層也有兩個全連線層,隱層單元為4096,1024(為什麼作者沒有說,估計也是交叉實驗驗證的),最後的輸出層有4個單元,分別是預測bounding box的四個邊的座標。和分類使用offset-pooling一樣,迴歸預測也是用這種方式,來產生不同的預測結果。

上圖展示了在單個比例上預測的在各個offset和sliding window下 pooling後,預測的多個bounding box;從圖中可以看出本文通過迴歸預測bounding box的方法可以很好的定位出物體的位置,而且bounding box都趨向於收斂到一個固定的位置,而且還可以定位多個物體和同一個物體的不同姿勢。但是感覺offset和sliding window方式,通過融合雖然增加了了準確度,但是感覺好複雜;而且很多的邊框都很相似,感覺不需要這麼多的預測值。就可以滿足超過覆蓋50%的測試要求。
4.3.3 Combining Predictions


match score: using the sum of the distance between centers of the two bounding boxes and the intersection area of the boxes
box merge:compute the average of the bounding boxes’ coordinates

表現

4.4 Detection
The main difference with the localization task, is the necessity to predict a background class when no object is present.
參考
【1】對 OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks 一文的理解
【3】深度學習(二十)基於Overfeat的圖片分類、定位、檢測
【4】深度學習研究理解6:OverFeat:Integrated Recognition, Localization and Detection using Convolutional Networks
【5】Overfeat