
使用spark ml pipeline進行機器學習
阿新 • • 發佈:2018-12-30
一、關於spark ml pipeline與機器學習
一個典型的機器學習構建包含若干個過程 1、源資料ETL 2、資料預處理 3、特徵選取 4、模型訓練與驗證 以上四個步驟可以抽象為一個包括多個步驟的流水線式工作,從資料收集開始至輸出我們需要的最終結果。因此,對以上多個步驟、進行抽象建模,簡化為流水線式工作流程則存在著可行性,對利用spark進行機器學習的使用者來說,流水線式機器學習比單個步驟獨立建模更加高效、易用。 受scikit-learn 專案的啟發,並且總結了MLlib在處理複雜機器學習問題的弊端(主要為工作繁雜,流程不清晰),旨在向用戶提供基於DataFrame 之上的更加高層次的 API 庫,以更加方便的構建複雜的機器學習工作流式應用。一個pipeline二、使用spark ml pipeline構建機器學習工作流
在此以Kaggle資料競賽Display Advertising Challenge的資料集(該資料集為利用使用者特徵進行廣告點選預測)開始,利用spark ml pipeline構建一個完整的機器學習工作流程。Display Advertising Challenge的這份資料本身就不多做介紹了,主要包括3部分,numerical型特徵集、Categorical型別特徵集、類標籤。 首先,讀入樣本集,並將樣本集劃分為訓練集與測試集:
//使用file標記檔案路徑,允許spark讀取本地檔案 String fileReadPath = "file:\\D:\\dac_sample\\dac_sample.txt"; //使用textFile讀入資料 SparkContext sc = Contexts.sparkContext; RDD<String> file = sc.textFile(fileReadPath,1); JavaRDD<String> sparkContent = file.toJavaRDD(); JavaRDD<Row> sampleRow = sparkContent.map(new Function<String, Row>() { public Row call(String string) { String tempStr = string.replace("\t",","); String[] features = tempStr.split(","); int intLable= Integer.parseInt(features[0]); String intFeature1 = features[1]; String intFeature2 = features[2]; String CatFeature1 = features[14]; String CatFeature2 = features[15]; return RowFactory.create(intLable, intFeature1, intFeature2, CatFeature1, CatFeature2); } }); double[] weights = {0.8, 0.2}; Long seed = 42L; JavaRDD<Row>[] sampleRows = sampleRow.randomSplit(weights,seed);
得到樣本集後,構建出 DataFrame格式的資料供spark ml pipeline使用:
List<StructField> fields = new ArrayList<StructField>();
fields.add(DataTypes.createStructField("lable", DataTypes.IntegerType, false));
fields.add(DataTypes.createStructField("intFeature1", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("intFeature2", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("CatFeature1", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("CatFeature2", DataTypes.StringType, true));
//and so on
StructType schema = DataTypes.createStructType(fields);
DataFrame dfTrain = Contexts.hiveContext.createDataFrame(sampleRows[0], schema);//訓練資料
dfTrain.registerTempTable("tmpTable1");
DataFrame dfTest = Contexts.hiveContext.createDataFrame(sampleRows[1], schema);//測試資料
dfTest.registerTempTable("tmpTable2");
//Cast integer features from String to Double
dfTest = dfTest.withColumn("intFeature1Temp",dfTest.col("intFeature1").cast("double"));
dfTest = dfTest.drop("intFeature1").withColumnRenamed("intFeature1Temp","intFeature1"); /*特徵轉換,部分特徵需要進行分箱,比如年齡,進行分段成成年未成年等 */
double[] splitV = {0.0,16.0,Double.MAX_VALUE};
Bucketizer bucketizer = new Bucketizer().setInputCol("").setOutputCol("").setSplits(splitV);再次,需要將categorical 型別的特徵轉換為numerical型別。主要包括兩個步驟,缺失值處理和編碼轉換。 缺失值處理方面,可以使用全域性的NA來統一標記缺失值:
/*將categoricalb型別的變數的缺失值使用NA值填充*/
String[] strCols = {"CatFeature1","CatFeature2"};
dfTrain = dfTrain.na().fill("NA",strCols);
dfTest = dfTest.na().fill("NA",strCols);缺失值處理完成之後,就可以正式的對categorical型別的特徵進行numerical轉換了。在spark ml中,可以藉助StringIndexer和oneHotEncoder完成 這一任務:
// StringIndexer oneHotEncoder 將 categorical變數轉換為 numerical 變數
// 如某列特徵為星期幾、天氣等等特徵,則轉換為七個0-1特徵
StringIndexer cat1Index = new StringIndexer().setInputCol("CatFeature1").setOutputCol("indexedCat1").setHandleInvalid("skip");
OneHotEncoder cat1Encoder = new OneHotEncoder().setInputCol(cat1Index.getOutputCol()).setOutputCol("CatVector1");
StringIndexer cat2Index = new StringIndexer().setInputCol("CatFeature2").setOutputCol("indexedCat2");
OneHotEncoder cat2Encoder = new OneHotEncoder().setInputCol(cat2Index.getOutputCol()).setOutputCol("CatVector2");至此,特徵預處理步驟基本完成了。由於上述特徵都是處於單獨的列並且列名獨立,為方便後續模型進行特徵輸入,需要將其轉換為特徵向量,並統一命名, 可以使用VectorAssembler類完成這一任務:
/*轉換為特徵向量*/
String[] vectorAsCols = {"intFeature1","intFeature2","CatVector1","CatVector2"};
VectorAssembler vectorAssembler = new VectorAssembler().setInputCols(vectorAsCols).setOutputCol("vectorFeature"); /*特徵較多時,使用卡方檢驗進行特徵選擇,主要是考察特徵與類標籤的相關性*/
ChiSqSelector chiSqSelector = new ChiSqSelector().setFeaturesCol("vectorFeature").setLabelCol("label").setNumTopFeatures(10)
.setOutputCol("selectedFeature");在特徵預處理和特徵選取完成之後,就可以定義模型及其引數了。簡單期間,在此使用LogisticRegression模型,並設定最大迭代次數、正則化項:
/* 設定最大迭代次數和正則化引數 setElasticNetParam=0.0 為L2正則化 setElasticNetParam=1.0為L1正則化*/
/*設定特徵向量的列名,標籤的列名*/
LogisticRegression logModel = new LogisticRegression().setMaxIter(100).setRegParam(0.1).setElasticNetParam(0.0)
.setFeaturesCol("selectedFeature").setLabelCol("lable");在上述準備步驟完成之後,就可以開始定義pipeline並進行模型的學習了:
/*將特徵轉換,特徵聚合,模型等組成一個管道,並呼叫它的fit方法擬合出模型*/
PipelineStage[] pipelineStage = {cat1Index,cat2Index,cat1Encoder,cat2Encoder,vectorAssembler,logModel};
Pipeline pipline = new Pipeline().setStages(pipelineStage);
PipelineModel pModle = pipline.fit(dfTrain); //擬合得到模型的transform方法進行預測
DataFrame output = pModle.transform(dfTest).select("selectedFeature", "label", "prediction", "rawPrediction", "probability");
DataFrame prediction = output.select("label", "prediction");
prediction.show();分析計算,得到模型在訓練集上的準確率,看看模型的效果怎麼樣:
/*測試集合上的準確率*/
long correct = prediction.filter(prediction.col("label").equalTo(prediction.col("'prediction"))).count();
long total = prediction.count();
double accuracy = correct / (double)total;
System.out.println(accuracy);最後,可以將模型儲存下來,下次直接使用就可以了:
String pModlePath = ""file:\\D:\\dac_sample\\";
pModle.save(pModlePath);三,梳理和總結:
上述,藉助程式碼實現了基於spark ml pipeline的機器學習,包括資料轉換、特徵生成、特徵選取、模型定義及模型學習等多個stage,得到的pipeline模型後,就可以在新的資料集上進行預測,總結為兩部分並用流程圖表示如下: 訓練階段:
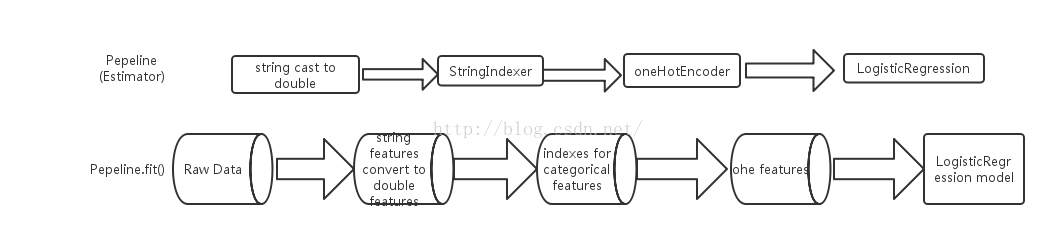
預測階段:
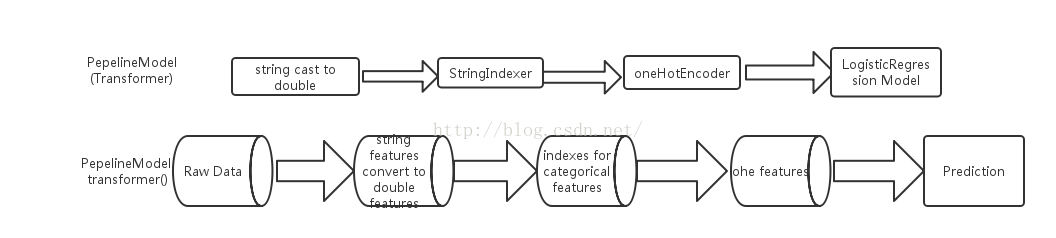
藉助於Pepeline,在spark上進行機器學習的資料流向更加清晰,同時每一stage的任務也更加明瞭,因此,無論是在模型的預測使用上、還是 模型後續的改進優化上,都變得更加容易。