
機器學習實戰(用Scikit-learn和TensorFlow進行機器學習)(三)
上一節講述了真實資料(csv表格資料)訓練集的檢視與預處理以及Pineline的基本架構。今天接著往下進行實戰操作,會用到之前的資料和程式碼,如果有問題請檢視上一節。
三、開始實戰
7、選擇及訓練模型
首先嚐試訓練一個線性迴歸模型(LinearRegression)
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(train_housing_prepared, train_housing_labels)訓練完成,然後評估模型,計算訓練集中的均方根誤差(RMSE)
from sklearn.metrics import mean_squared_error
housing_predictions = lin_reg.predict(train_housing_prepared)
lin_mse = mean_squared_error(train_housing_labels, housing_predictions)
lin_rmse = np.sqrt(lin_mse)
lin_rmse
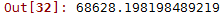
可以看到線性迴歸模型的訓練集均方誤差為68626
再試試看更強大的模型,決策樹模型(DecisionTreeRegressor)
from sklearn.tree

可以看到決策樹迴歸模型的的訓練集均方誤差竟然為0。比線性迴歸模型的的訓練集均方誤差小太多太多。
但這是否說明了決策樹迴歸模型比線性迴歸模型在此問題上好很多,當然不是,訓練誤差小的模型並不代表為好模型,這是因為模型可能過度地學習了訓練集的資料,只是在訓練集上的表現好(即過擬合),一旦測試新的資料表現就會很差。
因此在訓練的時候需要將部分的訓練資料提取出來作為驗證集,驗證該模型是否對此問題適用。其中比較常用的就是交叉驗證法。
交叉驗證法
交叉驗證的基本思想是將訓練資料集分為k份,每次用k-1份訓練模型,用剩餘的1份作為驗證集。按順序訓練k次後,計算k次的平均誤差來評價模型(改變引數後即為另一個模型)的好壞。(具體做法可以看百度百科)

在Scikit-Learn中交叉驗證對應的類為cross_val_score,下面是線性迴歸模型與決策樹迴歸模型的交叉驗證例項:
from sklearn.model_selection import cross_val_score
tree_scores = cross_val_score(tree_reg, train_housing_prepared, train_housing_labels,
scoring="neg_mean_squared_error", cv=10)
lin_scores = cross_val_score(lin_reg, train_housing_prepared, train_housing_labels,
scoring="neg_mean_squared_error", cv=10)
tree_rmse_scores = np.sqrt(-tree_scores)
lin_rmse_scores = np.sqrt(-lin_scores)
def display_scores(scores):
print("Scores:", scores)
print("Mean:", scores.mean())
print("Standard deviation:", scores.std())
display_scores(tree_rmse_scores)
display_scores(lin_rmse_scores)其中引數scoring為選擇一個指標,程式碼中選的為均方誤差;引數cv是交叉驗證劃分的個數,這裡劃為為10份。
需要注意:這裡經過交叉驗證求均方誤差的結果為負值,所以後面求平方根前需要加負號。

可以看到決策樹迴歸模型的交叉驗證平均誤差為71163,而線性迴歸模型的交叉驗證平均誤差為69051,這說明決策樹迴歸模型明顯是過擬合,實際上比線性迴歸模型要差一些。
除了這兩個簡單的模型以外,還應該試驗不同的模型(如隨機森林,不同核的SVM,神經網路等),最終選擇2-5個候選的模型。(也可以寫到同一個檔案下,方便以後直接呼叫)
儲存模型
最後介紹一下如何儲存模型到本地(硬碟)與重新載入本地模型,可以使用Pickle庫,也可以使用scikit-learn中的joblib庫,具體程式碼如下:
from sklearn.externals import joblib
joblib.dump(my_model, "my_model.pkl") #儲存模型
# and later...
my_model_loaded = joblib.load("my_model.pkl") #載入模型
8、模型調參
現在已經有一些候選的模型,你需要對模型的引數進行微調,使模型表現的更好。下面介紹幾種調參方法
網格搜尋(Grid Search)
scikit-learn中提供函式GridSearchCV用於網格搜尋調參,網格搜尋就是通過自己對模型需要調整的幾個引數設定一些可行值,然後Grid Search會排列組合這些引數值,每一種情況都去訓練一個模型,經過交叉驗證今後輸出結果。下面為隨機森林迴歸模型(RandomForestRegression)的一個Grid Search的例子。
from sklearn.model_selection import GridSearchCV
param_grid = [
{'n_estimators': [3, 10, 30], 'max_features': [2, 4, 6, 8]},
{'bootstrap': [False], 'n_estimators': [3, 10], 'max_features': [2, 3, 4]},
]
forest_reg = RandomForestRegressor()
grid_search = GridSearchCV(forest_reg, param_grid, cv=5,
scoring='neg_mean_squared_error')
grid_search.fit(train_housing_prepared, train_housing_labels)例子中首先調第一行的引數為n_estimators和max_features,即有3*4=12種組合,然後再調第二行的引數,即2*3=6種組合,具體引數的代表的意思以後再講述。總共組合數為12+6=18種組合。每種交叉驗證5次,即18*5=90次模型計算,雖然運算量比較大,但執行完後能得到較好的引數。
輸出最好的引數
grid_search.best_params_
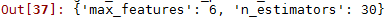
可以看到最好引數中30是選定引數的邊緣,所以可以再選更大的數試驗,可能會得到更好的模型,還可以在6附近選定引數,也可能會得到更好的模型。
輸出最好引數的模型
grid_search.best_params_

也可以看看每一個組合分別的交叉驗證的結果
cvres = grid_search.cv_results_
... for mean_score, params in zip(cvres["mean_test_score"], cvres["params"]):
... print(np.sqrt(-mean_score), params)

隨機搜尋(Randomized Search)
由於上面的網格搜尋搜尋空間太大,而機器計算能力不足,則可以通過給引數設定一定的範圍,在範圍內使用隨機搜尋選擇引數,隨機搜尋的好處是能在更大的範圍內進行搜尋,並且可以通過設定迭代次數n_iter,根據機器的計算能力來確定引數組合的個數,是下面給出一個隨機搜尋的例子。
from sklearn.model_selection import RandomizedSearchCV
param_ran={'n_estimators':range(30,50),'max_features': range(3,8)}
forest_reg = RandomForestRegressor()
random_search = RandomizedSearchCV(forest_reg,param_ran,cv=5,scoring='neg_mean_squared_error',n_iter=10)
random_search.fit(train_housing_prepared, train_housing_labels)分析最好的模型每個特徵的重要性
假設現在調參以後得到最好的引數模型,然後可以檢視每個特徵對預測結果的貢獻程度,根據貢獻程度,可以刪減減少一些不必要的特徵。
feature_importances = grid_search.best_estimator_.feature_importances_
extra_attribs = ["rooms_per_hhold", "pop_per_hhold", "bedrooms_per_room"]
cat_one_hot_attribs = list(encoder.classes_)
attributes = num_attribs + extra_attribs + cat_one_hot_attribs
sorted(zip(feature_importances, attributes), reverse=True)

可以看到ocean_proximity中的4個特徵中只有一個特徵是有用的,其他3個幾乎沒有用,所以可以考慮去除其他3個特徵。
在測試集中評估
經過努力終於得到了最終的模型,現在就差在測試集上驗證這個模型的泛化能力以及準確性。測試集中的操作和訓練集中的操作基本相同,唯一不同的是不需要fit(),只需要transform()就可以了,這是因為測試集不是用來訓練模型,所以不用fit(),所以將fit_transform()改為transform()。
final_model = grid_search.best_estimator_
X_test = strat_test_set.drop("median_house_value", axis=1)
y_test = strat_test_set["median_house_value"].copy()
X_test_prepared = full_pipeline.transform(X_test)
final_predictions = final_model.predict(X_test_prepared)
final_mse = mean_squared_error(y_test, final_predictions)
final_rmse = np.sqrt(final_mse)
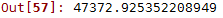
可以發現,結果和交叉驗證以後的結果比較相似,說明經過交叉驗證後,在新的資料集上也能達到類似的效果。
需要注意:在測試集中補缺失值,標準化等用到的值都是訓練集上的中值,平均值等,而不是測試集上的。因為必須把資料放縮到同一尺度。