
linux--fork()函式詳解及底層實現機制
fork底層實現機制:Linux中實現為呼叫clone函式,然後為do_fork,再然後copy_process()複製程序(複製相應資料結構例如:核心棧、thread_info、task_struct),然後設定子程序描述符內一些成員初始值,再設定子程序狀態為阻塞,保證其不執行,分配PID;最後再從父程序中拷貝其他資訊例如:開啟的檔案、檔案系統資訊。
一、fork()基礎
一個程序,包括程式碼、資料和分配給程序的資源。fork()函式通過系統呼叫建立一個與原來程序幾乎完全相同的程序,
也就是兩個程序可以做完全相同的事,但如果初始引數或者傳入的變數不同,兩個程序也可以做不同的事。
一個程序呼叫fork()函式後,系統先給新的程序分配資源,例如儲存資料和程式碼的空間。然後把原來的程序的所有值都
複製到新的新程序中,只有少數值與原來的程序的值不同。相當於克隆了一個自己。
來看一個例子:
- /*
- * fork_test.c
- * version 1
- * Created on: 2010-5-29
- * Author: wangth
- */
- #include <unistd.h>
- #include <stdio.h>
-
int main ()
- {
- pid_t fpid; //fpid表示fork函式返回的值
- int count=0;
- fpid=fork();
- if (fpid < 0)
- printf("error in fork!");
- else if (fpid == 0) {
- printf("i am the child process, my process id is %d/n",getpid());
- printf("我是爹的兒子/n");//對某些人來說中文看著更直白。
-
count++;
- }
- else {
- printf("i am the parent process, my process id is %d/n",getpid());
- printf("我是孩子他爹/n");
- count++;
- }
- printf("統計結果是: %d/n",count);
- return 0;
- }
執行結果是:
i am the child process, my process id is 5574
我是爹的兒子
統計結果是: 1
i am the parent process, my process id is 5573
我是孩子他爹
統計結果是: 1
在語句fpid=fork()之前,只有一個程序在執行這段程式碼,但在這條語句之後,就變成兩個程序在執行了,這兩個程序的幾乎完全相同,
將要執行的下一條語句都是if(fpid<0)……
為什麼兩個程序的fpid不同呢,這與fork函式的特性有關。
fork呼叫的一個奇妙之處就是它僅僅被呼叫一次,卻能夠返回兩次,它可能有三種不同的返回值:
1)在父程序中,fork返回新建立子程序的程序ID;
2)在子程序中,fork返回0;
3)如果出現錯誤,fork返回一個負值;
在fork函式執行完畢後,如果建立新程序成功,則出現兩個程序,一個是子程序,一個是父程序。在子程序中,fork函式返回0,在父程序中,
fork返回新建立子程序的程序ID。我們可以通過fork返回的值來判斷當前程序是子程序還是父程序。
引用一位網友的話來解釋fpid的值為什麼在父子程序中不同。“其實就相當於連結串列,程序形成了連結串列,父程序的fpid(p 意味point)指向子程序的程序id,
因為子程序沒有子程序,所以其fpid為0.
fork出錯可能有兩種原因:
1)當前的程序數已經達到了系統規定的上限,這時errno的值被設定為EAGAIN。
2)系統記憶體不足,這時errno的值被設定為ENOMEM。
建立新程序成功後,系統中出現兩個基本完全相同的程序,這兩個程序執行沒有固定的先後順序,哪個程序先執行要看系統的程序排程策略。
每個程序都有一個獨特(互不相同)的程序識別符號(process ID),可以通過getpid()函式獲得,還有一個記錄父程序pid的變數,可以通過getppid()函式獲得變數的值。
fork執行完畢後,出現兩個程序,
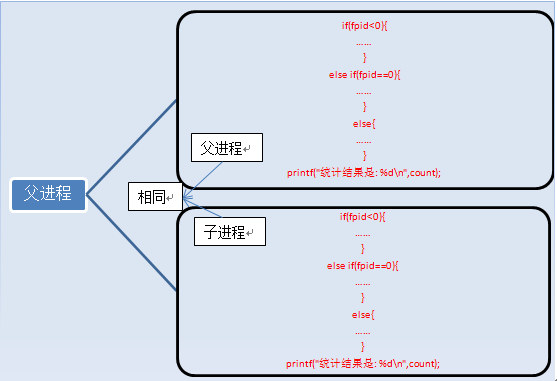
有人說兩個程序的內容完全一樣啊,怎麼列印的結果不一樣啊,那是因為判斷條件的原因,上面列舉的只是程序的程式碼和指令,還有變數啊。
執行完fork後,程序1的變數為count=0,fpid!=0(父程序)。程序2的變數為count=0,fpid=0(子程序),這兩個程序的變數都是獨立的,
存在不同的地址中,不是共用的,這點要注意。可以說,我們就是通過fpid來識別和操作父子程序的。
還有人可能疑惑為什麼不是從#include處開始複製程式碼的,這是因為fork是把程序當前的情況拷貝一份,執行fork時,程序已經執行完了int count=0;
fork只拷貝下一個要執行的程式碼到新的程序。
二、fork進階知識
先看一份程式碼:
- /*
- * fork_test.c
- * version 2
- * Created on: 2010-5-29
- * Author: wangth
- */
- #include <unistd.h>
- #include <stdio.h>
- int main(void)
- {
- int i=0;
- printf("i son/pa ppid pid fpid/n");
- //ppid指當前程序的父程序pid
- //pid指當前程序的pid,
- //fpid指fork返回給當前程序的值
- for(i=0;i<2;i++){
- pid_t fpid=fork();
- if(fpid==0)
- printf("%d child %4d %4d %4d/n",i,getppid(),getpid(),fpid);
- else
- printf("%d parent %4d %4d %4d/n",i,getppid(),getpid(),fpid);
- }
- return 0;
- }
執行結果是:
i son/pa ppid pid fpid
0 parent 2043 3224 3225
0 child 3224 3225 0
1 parent 2043 3224 3226
1 parent 3224 3225 3227
1 child 1 3227 0
1 child 1 3226 0
這份程式碼比較有意思,我們來認真分析一下:
第一步:在父程序中,指令執行到for迴圈中,i=0,接著執行fork,fork執行完後,系統中出現兩個程序,分別是p3224和p3225
(後面我都用pxxxx表示程序id為xxxx的程序)。可以看到父程序p3224的父程序是p2043,子程序p3225的父程序正好是p3224。我們用一個連結串列來表示這個關係:
p2043->p3224->p3225
第一次fork後,p3224(父程序)的變數為i=0,fpid=3225(fork函式在父程序中返向子程序id),程式碼內容為:
- for(i=0;i<2;i++){
-
pid_t fpid=fork();
相關推薦
linux--fork()函式詳解及底層實現機制
fork底層實現機制:Linux中實現為呼叫clone函式,然後為do_fork,再然後copy_process()複製程序(複製相應資料結構例如:核心棧、thread_info、task_
linux中fork() 函式詳解
fork入門知識 一個程序,包括程式碼、資料和分配給程序的資源。fork()函式通過系統呼叫建立一個與原來程序幾乎完全相同的程序,也就是兩個程序可以做完全相同的事,但如果初始引數或者傳入的變數不同,兩個程序也可以做不同的事。 一個程序呼叫fork()函式後,系統先給新的程序分配資源,例如儲存資料和程式碼的
Java併發核心基礎——執行緒池使用及底層實現機制詳解
Java執行緒池概述: 從使用入手: java.util.concurrent.Executosr是執行緒池的靜態工廠,我們通常使用它方便地生產各種型別的執行緒池,主要的方法有三種: 1、newS
字串函式---itoa()函式詳解及實現
itoa()函式 itoa():char *itoa( int value, char *string,int radix); 原型說明: value:欲轉換的資料。 string:目標字串的地址。 radix:轉換後的進位制數,可以是10進位制、16進位制等,範圍必須在
Oracle中的substr()函式 詳解及應用
1)substr函式格式 (俗稱:字元擷取函式) 格式1: substr(string string, int a, int b); 格式2:substr(string string, int a) ; 解釋: 格式1:
exec族函式詳解及迴圈建立子程序
前言:之前也知道exec族函式,但沒有完全掌握,昨天又重新學習了一遍,基本完全掌握了,還有一些父子程序和迴圈建立子程序的問題,還要介紹一下環境變數,今天分享一下。 一、環境變數 先介紹下環境的概念和特性,再舉例子吧。 環境變數,是指在作業系統中用來指定作業系統執行環境的一些引數。通常具備
linux select函式詳解
在Linux中,我們可以使用select函式實現I/O埠的複用,傳遞給 select函式的引數會告訴核心: •我們所關心的檔案描述符 •對每個描述符,我們所關心的狀態。(我們是要想從一個檔案描述符中讀或者寫,還是關注一個描述符中是否出現異常)
Keras入門教程06——CapsNet膠囊神經網路詳解及Keras實現
論文《Dynamic Routing Between Capsules》 參考了一篇部落格還有Keras官方的程式碼,結合程式碼給大家講解下膠囊神經網路。 1. 膠囊神經網路詳解 1.1 膠囊神經網路直觀理解 CNN存在的問題 影象分類中,一旦卷積核檢測到類
opencv-python(cv2)影象二值化函式threshold函式詳解及引數cv2.THRESH_OTSU使用
cv2.threshold()函式的作用是將一幅灰度圖二值化,基本用法如下: #ret:暫時就認為是設定的thresh閾值,mask:二值化的影象 ret,mask = cv2.threshold(img2gray,175,255,cv2.THRESH_BINARY) pl
softmax + cross-entropy交叉熵損失函式詳解及反向傳播中的梯度求導
相關 正文 在大多數教程中, softmax 和 cross-entropy 總是一起出現, 求梯度的時候也是一起考慮. 我們來看看為什麼. 關於 softmax 和 cross-entropy 的梯度的求導過程, 已經在上面的兩篇文章中分別給出, 這裡
倒排索引詳解及C++實現
1.介紹 倒排索引是現代搜尋引擎的核心技術之一,其核心目的是將從大量文件中查詢包含某些詞的文件集合這一任務用O(1)或O(logn)的時間複雜度完成,其中n為索引中的文件數目。也就是說,利用倒排索引技術,可以實現與文件集大小基本無關的檢索複雜度,這一點對於
微博爬蟲“免登入”技巧詳解及 Java 實現
一、微博一定要登入才能抓取? 目前,對於微博的爬蟲,大部分是基於模擬微博賬號登入的方式實現的,這種方式如果真的運營起來,實際上是一件非常頭疼痛苦的事,你可能每天都過得提心吊膽,生怕新浪爸爸把你的那些賬號給封了,而且現在隨著實名制的落地,獲得賬號的渠道估計也會變得越
機器學習經典演算法詳解及Python實現--線性迴歸(Linear Regression)演算法
(一)認識迴歸 迴歸是統計學中最有力的工具之一。機器學習監督學習演算法分為分類演算法和迴歸演算法兩種,其實就是根據類別標籤分佈型別為離散型、連續性而定義的。顧名思義,分類演算法用於離散型分佈預測,如前
小白之KMP演算法詳解及python實現
在看子串匹配問題的時候,書上的關於KMP的演算法的介紹總是理解不了。看了一遍程式碼總是很快的忘掉,後來決定好好分解一下KMP演算法,算是給自己加深印象。 ------------------------- 分割線-------------------------------
迪克斯特拉演算法詳解及C++實現
演算法步驟如下: G={V,E} 1. 初始時令 S={V0},T=V-S={其餘頂點},T中頂點對應的距離值 若存在<V0,Vi>,d(V0,Vi)為<V0,Vi>弧上的權值
spark三種清理資料的方式:UDF,自定義函式,spark.sql;Python中的zip()與*zip()函式詳解//及python中的*args和**kwargs
(1)UDF的方式清理資料 import sys reload(sys) sys.setdefaultencoding('utf8') import re import json from pyspark.sql import SparkSession
遺傳演算法詳解及Java實現
遺傳演算法的起源 ========== 20世紀60年代中期,美國密西根大學的John Holland提出了位串編碼技術,這種編碼既適合於變異又適合雜交操作,並且他強調將雜交作為主要的遺傳操作。遺傳演算法的通用編碼技術及簡單有效的遺傳操作為其廣泛的應用和成功
機器學習經典演算法詳解及Python實現--決策樹(Decision Tree)
(一)認識決策樹 1,決策樹分類原理 決策樹是通過一系列規則對資料進行分類的過程。它提供一種在什麼條件下會得到什麼值的類似規則的方法。決策樹分為分類樹和迴歸樹兩種,分類樹對離散變數做決策樹,迴歸樹對連續變數做決策樹。 近來的調查表明決策樹也是最經常使用的資料探勘演算法,它
常見9大排序演算法詳解及python3實現
穩定:如果a原本在b前面,而a=b,排序之後a仍然在b的前面; 不穩定:如果a原本在b的前面,而a=b,排序之後a可能會出現在b的後面; 內排序:所有排序操作都在記憶體中完成; 外排序:由於資料太大,因此把資料放在磁碟中,而排序通過磁碟和記憶體的資料傳輸才能進行;