
人工智慧各種技術與演算法
目錄:
1>單體人工智慧
>隨機數(Random)
>>狀態空間盲目搜尋
>>>深度優先搜尋(Depth-First-Search)
>>>廣度優先搜尋(Breadth-First-Search)
>>狀態空間啟發式搜尋
>>>A搜尋演算法(A Search Algorithm)
>>>A*尋路(A* Search Algorithm)
>>>D*尋路(Dymamic A* Search Algorithm)
>狀態機機制(Finite-State Machine)
>決策樹機制(Decision Tree)
>博弈論(Game Theroy)
>>最大最小搜尋演算法(Max-min search algorithm)
>>剪枝搜尋演算法(Alpha-beta search algorithm)
>神經網路(Artificial Neural Networks)
>>深度學習(Deep Learning)
>>置信網路(Belief Network)
>>卷積神經網路(Convolutional Neural Network)
>退火演算法(Simulate Anneal Arithmetic)//empty
2>群體人工智慧
>遺傳演算法(Genetic Algorithm)
>群聚技術//empty
其實這篇文章更類似於科普貼,它完全可以作為你學習人工智慧的入門文章,我的目的是用通俗的語言概括人工智慧領域的各項技術,從而讓讀者有個直觀淺顯的認識
隨機(Random)
隨機是智慧的基礎,人工智慧的很多技術都需要用到隨機,因此有必要把這個提到前面談談
一考慮基於C/C++,般我們都是使用的rand()等函式實現隨機,當然我們也有吊炸天的boost提供了各種分佈範圍的隨機:
- #include <boost/random.hpp>
- ...
-
uniform_int<> distribution(1, 100) ;
- mt19937 engine ;variate_generator<mt19937,uniform_int<> > myrandom (engine, distribution);
- // uniform_smallint:在小整數域內的均勻分佈
- // uniform_int:在整數域上的均勻分佈
- // uniform_01:在區間[0,1]上的實數連續均勻分佈
- // uniform_real:在區間[min,max]上的實數連續均勻分佈
- // bernoulli_distribution:伯努利分佈
- // binomial_distribution:二項分佈
- // cauchy_distribution:柯西(洛倫茲)分佈
- // gamma_distribution:伽馬分佈
- // poisson_distribution:泊松分佈
- // geometric_distribution:幾何分佈
- // triangle_distribution:三角分佈
- // exponential_distribution:指數分佈
- // normal_distribution:正態分佈
- // lognormal_distribution:對數正態分
- // uniform_on_sphere:球面均勻分佈
但是這個取到的資料都是偽隨機數,或依靠系統時間,或依靠日期等,顯然這個對於人工智慧是不夠的,我們需要真隨機,C++11的std ::random_device給了我們希望,如名這個的隨機石使用的硬體,linux是讀取dev/urandom硬體裝置,但是windows居然還是呼叫的rand_s()函式!這個沒什麼太多說的,買點專業硬體即可。
狀態空間啟發式搜尋-A尋路演算法(A* Search Algorithm)
A尋路演算法是A*的退化,所以我不考慮說什麼,當然如果你想學習A星,先學A是一個不錯的選擇,為此我特意寫了一篇文章詳細講解各種尋路搜尋策略http://blog.csdn.net/racaljk/article/details/18887881狀態空間啟發式搜尋-A星尋路演算法(A* Search Algorithm)
其實這個標題是我自己寫得到,原翻譯顯然沒有”尋路“這兩個字,因為A星演算法包括但不僅限於存在於人工智慧的尋路中,但是既然標題是人工智慧,這樣也無傷大雅,在說A*之前有必要說所深度優先搜尋演算法DFS和廣度優先搜尋演算法BFS,假設一個map上面,有諸多障礙,目前機器人需要做的就是在這個有限的地圖上沒有其他資訊支援,需要從起點出發找到終點,如上所說,這個地圖裡面的障礙時允許嘗試的,如果我們使用深度有限演算法,他會從起點出發走一條路並一直走下去,直到遇到障礙或者沒有達成條件-到終點,於是返回重新走,顯然他不會愚蠢到走與之前同樣的錯誤路線,DFS比較耗時,但是如果成功了也就執行了這條路線(沒有人為干擾的情況下),而BFS則在遇到障礙時就會向四周試探性的走幾步,一旦試探成功就繼續走,如此遞迴,直到成功(如果在有限的map下,且存在正確路徑,則必然會成功),簡單來說,我們的理論都是基於二叉樹的條件下,BFS是沿著樹的寬度進行完全變遍歷,而DFS是沿著數的一條分支一直走下去,直到成功,A*結合這兩個演算法的優點,從而實現快速尋路下面這個更直觀:假設這個是一個地圖,左#表示起點,右#表示終點,@@表示障礙00000000000000000@0000#0000@@000#000000@000000000000000如果用DFS他會像掃描器一樣從左至右掃描到終點,如果用DFS他會像掃描一樣從中間向兩邊掃描掃描,而A*則結合這兩個演算法的優勢,從而實現最快的尋路,關於A*演算法的原始碼請自行百度下面是一個A*的一個動畫演示

D星尋路演算法(Dynamic A* Search Algorithm)
顧名思義d*也就是動態A*尋路演算法,區別僅在於A*是侷限於A*是生成一條路就一直走下去,但實際情況下有很多突發情況,比如生成的那條路被堵了,就需要重新生成新的路線,這就需要D*了,D*也就是說動態生成A*路線。
狀態機(Finite-State Machine)
FSM看似很高階,的確我當初也被嚇著了,不過看了下面的內容就會覺得很簡單,細分狀態機分為有限狀態機和模糊狀態機,也加同步狀態機和非同步狀態機,兩種狀態機的區別在於有限狀態機在一個時段只能處於一種狀態,而模糊(也即非同步)狀態機有一個權重值,根據這個權重值我們可以分配給不同的狀態不同的權重,比如一個人,有限狀態機允許人去喝水,模糊狀態機允許80%去喝水,20%接水。你甚至可以理解為FSM是單執行緒,FμSM是多執行緒。有關狀態機的資料可以參見:http://zh.wikipedia.org/wiki/%E6%9C%89%E9%99%90%E7%8A%B6%E6%80%81%E6%9C%BA為了便於理解,現複製一下基本概念:狀態(State)指的是物件在其生命週期中的一種狀況,處於某個特定狀態中的物件必然會滿足某些條件、執行某些動作或者是等待某些事件。事件(Event)指的是在時間和空間上佔有一定位置,並且對狀態機來講是有意義的那些事情。事件通常會引起狀態的變遷,促使狀態機從一種狀態切換到另一種狀態。轉換(Transition)指的是兩個狀態之間的一種關係,表明物件將在第一個狀態中執行一定的動作,並將在某個事件發生同時某個特定條件滿足時進入第二個狀態。 動作(Action)指的是狀態機中可以執行的那些原子操作,所謂原子操作指的是它們在執行的過程中不能被其他訊息所中斷,必須一直執行下去。看不懂上面可以看下面:
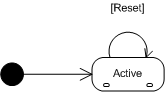
這裡盜用一張UML(http://www.cnblogs.com/ywqu/archive/2009/12/17/1626043.html這是關於UML比較詳細的介紹)圖片來解釋一下,黑圓圈表示初始狀態,非規則長方形表示一個狀態,Active表示狀態條件,也就是這種狀態需要什麼條件,Reset表示轉換事件我們結合boost::statechart可以很容易寫出上述圖片的程式碼
- #include<boost/statechart/state_machine.hpp>
- #include<boost/statechart/simple_state.hpp>
- class Mchine_Initiate;//模板必須有一個class作為初始化後的狀態
- class Machine : boost::statechart::state_machine<Machine, Mchine_Initiate>{
- public:
- Machine(){std::cout << "Machine class";};
- };
- class Mchine_Initiate{
- public:
- Mchine_Initiate(){std::cout << "in";};
- ~ Mchine_Initiate(){std::cout << "out~"};
- };
決策樹(Decision Tree)
這個大家應該都不陌生,當我們遇到一個問題時會有多種處理方法,這符合一個樹狀態結構,我們會選擇最佳策略進行處理,同樣,人工智慧也有類似實現名為決策樹,我們會發現者似乎與FSM有聯絡,恭喜你你的發現時正確的,這其實算是靜態FSM,FSM應該冠名為動態FSM才是最佳的,當然這是我個人看法,何謂靜態,就是既定的方案,這個樹枝都有權重值,50%A樹枝,50%B樹枝,機器人可以按照這個既定的方案執行,因此決策樹可以儲存並分享,而FSM是動態選擇,有關決策樹的概念就這麼多了,詳細實現大家可以去百度一下。這裡提供一篇演算法,遺憾的是裡面專業術語比較多,理解較困難http://www.cnblogs.com/biyeymyhjob/archive/2012/07/23/2605208.html博弈論(Game Theroy)
這是我最感喜歡的部分,某種程度上說沒有博弈論體系的AI算不上AI,博弈論在人工智慧中廣泛用於最優化策略,從原英文中我們就看得出這個與遊戲有關,物件是單體,著名的例子就是簡化的囚徒困境:兩個囚徒甲和已違法被抓,分別關押,有如下選擇:如果兩個人都承認,那麼都判10年如果一人不承認,另一人承認並指認同夥,那麼這個人將無罪釋放,而被指認的那個人將被判20年如果兩個人都不承認,將只是非法帶槍罪判1年。從單體出發,假設我是甲,我心裡會想:如果我認罪,10年,不認罪20年,10<20,認罪最好。對方認罪我0年,對方不認罪1年,0<1認罪最後以類同,因此選擇認罪各10年在人工智慧中我們要窮舉所有可能,並計算最終收益,最後讓收益最大化,這就是人工智慧的博弈論理論,博弈論博大精深,這裡只是十分基礎的認識人工智慧領域的博弈論我們需要考慮兩個東西:期望收益、規則設定。比如我們的規則設定是機器人比賽,然後機器人要選擇收益最大化,因此我們就要窮舉各種可以執行的策略,並最終從這些策略對比使收益最大化,再如田忌賽馬這個強拉硬扯算是博弈論,規則是上中下等馬比賽,上>中,中>下,然後計算機就要窮舉所有策略,優上>良上,優上>良中....,最終更加這些策略對比使收益最大化,我們可以把這些作為一個樹狀結構實現,稱之為博弈樹,博弈樹廣泛引用於各種棋牌遊戲的AI,很多演算法如alpha-beta搜尋都是基於博弈樹實現的
最大最小搜尋演算法(Max-min search algorithm)
最大最小搜尋演算法基於博弈樹,廣泛應用於棋盤較小的棋牌遊戲AI中,詳細請看我的文章http://blog.csdn.net/racaljk/article/details/18842545
神經網路(Artificial Neural Networks)
神經網路同上是人工智慧的智慧所在,神經網路類似於抽象了人類的歷史,請不要反駁遠古時期人類沒有手機這句話,人類的聰明是經驗所得,試想一下,假設機器人前面有一個障礙,這個障礙堵塞了路,機器人就會不斷使用尋路演算法嘗試,顯然,這是沒有效果的,因為沒有正確的道路,想想如果是你你會怎麼做,你會跳過去,是的,這就是一個神經網路的實現,你早就經歷過這種事情,現在你需要做的就是運用之前的經驗來解決這個”新“情況。要想智慧,沒有這種經驗的學習都是紙上談兵(當然前提是你得置入跳的動作程式碼),當機器人用A*嘗試5次都失敗的情況下它就會改變策略,調整腳部神經元閥值,當調節為1,發現跳不過,就調節為8,如此在一定的區間內隨機直到成功置信網路(Belief Network)
從分類中可以看出置信網路從屬於深度學習,而深度學習父級是神經網路,也就是說置信技術是以神經網路為基礎的在其基礎上優化的一門機器學習技術。置信技術把人工智慧推向了極致,他與博弈論、神經網路遺傳演算法構成了AI的核心體系。之前我們的神經網路和遺傳演算法使用窮舉進行嘗試和篩選,而置信網路總結資料並試圖發現規律,這看起來多麼偉大,同時也多麼不容易,把客觀世界object的規律對映到智慧機器,即使是人類也不一定做好同樣是上面走路的例子,我們假設了神經網路的閥值必須要是偶數*2才能通過,貝葉斯智信網路則是用來總結得出這個規律,他需要前面的資料並進行分析,並把抽象資料轉化為客觀規律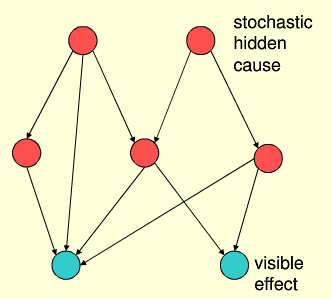
上圖就是一個經典的置信網路,其中紅色圓圈表示未知規律,藍色為表象
置信網路可以極大優化神經網路,減少嘗試次數,比如利用置信網路總結出結果在偶數*2中間,通過其他資訊比如數量是家庭垃圾物體數,神經網路便可在一個較小的範圍類進行偶數*2的嘗試