
GAN系列:Image-to-Image Translation with Conditional Adversarial Networks
Abstract
1. image-to-image trainslation
存在的兩個問題:
1)many-to-one:將照片對映為edges/segments/semantic labels
2)one-to-many:將labels/sparse user inputs對映為真實圖片
一般的做法是predict pixels form pixels;作者的創新點為develop a common network,通用網路,可以用來進行Image translation領域的各種任務。
2. naive方法得到的通常是比較blurry的結果,原因是目標只是通過最小化真實的和預測的畫素之間的歐氏距離,因此平均得到的效果應該會使得損失函式最小,所以輸出的結果就會變得很blurry以及沒有鮮明的色彩;作者針對這個提出的想法是,只明確high-level的目標,即讓輸出圖片和真實圖片看起來沒有太大的差別。
3.作者表明自己這篇文章的兩個主要貢獻是:
1)在image-to-image trainslation領域創新了一種通用演算法
2)簡單網路就可以達到很好的效果

Related Work
1.影象建模中的結構化損失
傳統的image-to-image trainslation都是對每個畫素進行預測/迴歸,此時我們對輸出空間的結構化並不在意,即,認為輸出圖片的畫素之間是相互獨立的;而cGAN則使用了結構化損失;作者提出的損失的特點是為損失可以被學習而且it can penalize any possible structure that differs between output and target;作者提出的結構的特點是a)nothing is application-specific;b)U-Net based architecture;c)convolutional "PatchGAN" classifier as Discriminator
2.方法
GANs G: z對映到y
cGANs G: {x, z}對映到y
2.1 Objective
cGAN
GAN
L1 instead of L2
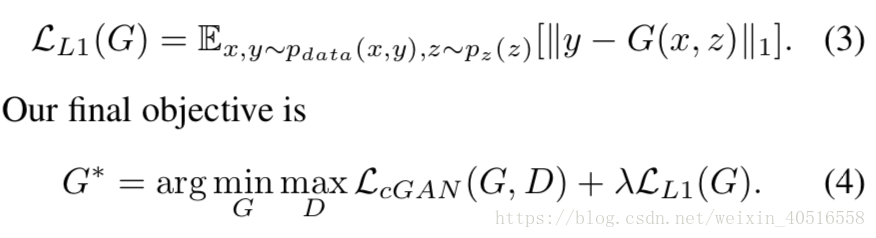
注意,沒有噪聲z,輸出就是確定的。因此要在輸入x的基礎上加上噪聲z。
2.2 網路架構
Generator、Discriminator的結構參考了DCGAN, 兩者modules的結構為conv-BN-ReLu。
2.2.1 Generator with skips
image-to-image trainslation結果的特點為input and output differ in surface appearance but with same underlying structure
1.最開始解決這種問題的結構為Encoder-Decoder,即輸入一張圖片先downsample,再upsample,中間是一個bottleneck layer,這種結構存在的問題是輸入和輸出之間存在很多的底層資訊共享。
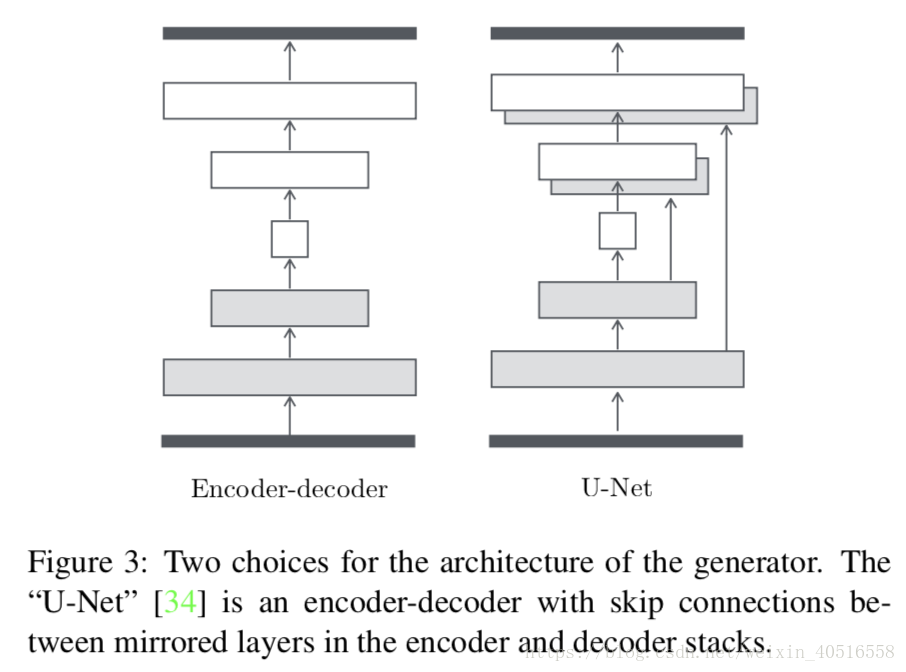
為了避免這種情況作者添加了skip connections,並遵從了U-Net大致形式,即在第i層和第n-i層之間新增skip connections,其中n為總層數。具體結構參考(https://arxiv.org/pdf/1505.04597.pdf)
2.在image generation問題上,L2總是會產生blurry的結果,這種損失在high-frequence上的表現不是很好,在low-frequence上的表現卻不錯。關於什麼是high frequence和low frequence,可以參考:
通俗地說high frequence通常出現在邊界上,而low frequence則通常出現在連續的表面;因此選擇的方法是用L1去限制GAN在high frequence結構上進行建模。
3.那麼如何對high frequence進行建模呢?——PatchGAN
1)將注意力限制在區域性圖片切片的結構上,提出了所謂的PatchGAN結構;
2)所謂的PatchGAN就是當我們判別一張圖片是真還是假時,我們先將其分為NxN個patch之後進行判別的;
3)還可以以卷積地形式進行,即,即使用精度更小的圖片訓練出來的PatchGAN也可以用於精度更大的圖片的判別,最後的輸出結果取平均;
4)實驗中證明Patch的N可以很小,意味著計算量更少,引數也會更少;
5)PatchGAN將圖片建模成一個馬爾科夫隨機場,即,他認為在一個patch diameter距離之外的pixels之間是相互獨立的。