
CVPR:Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
摘要
背景:影象到影象的遷移是計算機視覺中的一個很有意思的問題。目標是學習一個從輸入圖片到目標圖片的對映,在訓練中需要使用成對的訓練集。
問題:成對的訓練資料並不是那麼容易獲得的。
本文方法:學習一個從源域(source domain)到目標域(target domain)的對映來進行影象的遷移。使用一個對抗損失,使得來自於G(X)的圖片的分佈與分佈Y無法區分,即使得生成的圖片的分佈與目標域的圖片的分佈逼近。既然兩者的分佈是趨向於相同的,那麼可以想到,既然A與B無法區分,那麼也意味著B與A無法區分,即這個關係是相對的,所以我們就可以定義一個逆對映
實驗:
- 定性分析:不使用成對的訓練集的遷移結果展示,包括collection style transfer,object transfiguration,season transfer,photo enhancement等;
- 定量分析:與一些其它的使用成對資料訓練的方法進行比較。
簡介:

如圖-1左上為例,同一場景下,莫奈的畫作與照片的記錄展現出了兩種不同的情境,我們不禁暢想,給你一副莫奈的畫作,是不是可以自動的產生照片中真實的場景,抑或是給你一副真實的場景,是否可以自動的將其轉化為莫奈的風格。作者展示了其方法的魔力,不像其它的方法在訓練中需要一一對應排序好的訓練資料,只需要兩個無序的集合X(源域)和Y(目標域),該演算法就可以自動地進行風格的遷移。
稍微回顧下影象到影象的遷移:給定一個場景的影象x,將其轉換到另一個場景的y,比如:將灰度圖轉化到彩色的圖,影象到語義標籤。目前也有很多研究工作,使用成對的資料進行風格的遷移。如圖-2左側所示。
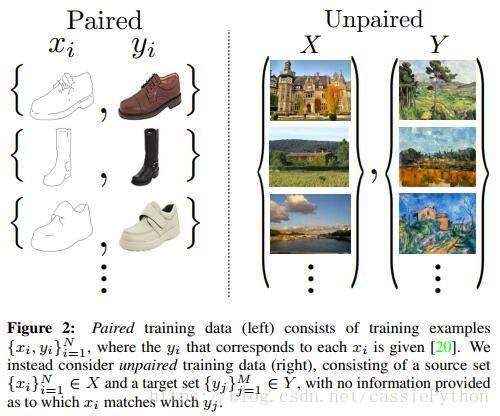
但是呢,這些成對出現的資料集並不是那麼容易獲得的。於是本文探究了一個演算法,不需要這些成對的資料,如圖-2中右側所示。這裡作者做了一個假設:在源域和目標域存在潛在的關係。其實就是兩者從分佈上而言,是存在相似性的。這裡留下一個問題:如果兩個域完全不同或者說差別非常大結果會怎麼樣呢?
給定源域的圖片集合X以及另一個域的圖片集合Y,我們使用對抗的思想學習一個對映,其輸出,與無法區分。
我們不禁想到這樣一個問題,這個不成對的訓練是怎麼進行的呢?如果仍然使用傳統的GAN的損失和訓練方式,使用這些不成對的資料集進行訓練,會出現什麼問題呢?作者發現:
- 無法保證對於一個輸入x,可以得到有意義的輸出y,因為使用了不成對的訓練集,但是可以學到無數種的對映G,而這些G都可以使生成的分佈逼近與目標域。
- 單獨優化對抗損失非常困難,導致了一些不可名狀的問題,如model collapse(即生成的樣本的多樣性問題)。
如何解決呢?作者發現在遷移過程中有這樣一個特性——”迴圈一致性“。比如:我們將一個句子從英語翻譯到法語,再將其翻譯回英語,我們應該得到與原始的英文相同的句子(不禁想起了以前整理的的Dual Learning的文章,有興趣的可以看下)。用數學符號來表示下:我們有一個轉換器(對映):,和另一個轉換器。那麼G和F應該是互逆的,即兩者是一個雙向對映。於是可以同時訓練G和F來確保這個性質,增加一個迴圈一致性損失,使得以及。組合該損失和對抗損失,就得到了我們整體的非正對的影象到影象遷移的優化目標。
公式
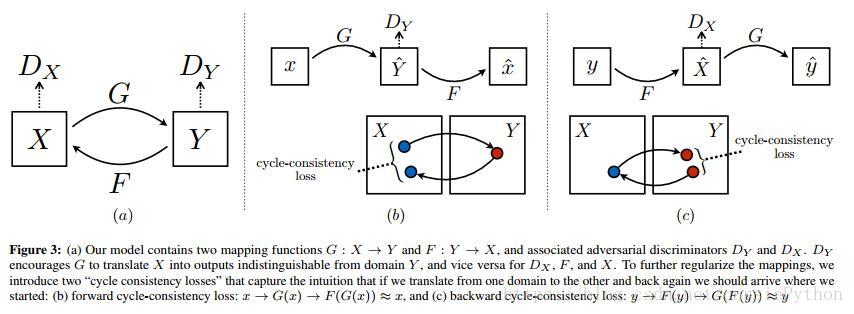
給定訓練集樣本和。如圖-3(a)所示,模型包含兩個對映:和。此外,引入兩個對抗的判別器和,的作用是用來判別和;的作用是用來判別和。優化目標包含兩項:
- 對抗損失(adversarial loss):促使生成影象分佈與目標域的影象分佈相逼近
- 迴圈一致性損失(cycle consistency loss):使得以及。防止學習到的對映G和F互相矛盾。
對抗損失
將對抗損失應用到兩個對映上。對於對映函式和它的識別器,目標函式為: