
常見的時間序列資料庫概述
對於時間序列的儲存,一般會採用專門的時間序列資料庫,而不會去使用mysql或是mongo(但zabbix就是用的mysql,所以它在IO上面遇到了瓶頸)。現在時間序列的資料庫是有很多的,比如graphite、opentsdb以及新生的influxdb。最近也相繼研究了一下這三個資料庫,現在把研究所得記錄下來。
graphite
graphite算是一個老牌的時間序列儲存解決方案了,graphite由三個部分組成,分別是carbon、whisper和graphite web,盜圖:
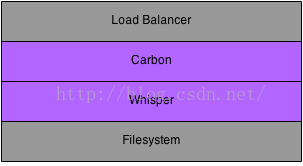
carbon:實際上是一系列守護程序,這些守護程序用Twisted的事件驅動網路引擎監聽時間序列資料。Twisted框架讓Carbon守護程序能夠以很低的開銷處理大量的客戶端和流量。
whisper:是一個用於儲存時間序列資料的資料庫,之後應用程式可以用create,update和fetch操作獲取並操作這些資料。
graphite web:使用django開發的一套web,提供一些常用的聚合函式,可以介面友好的展示出圖形。再盜圖:
whisper支援RRD,可以很方便的定義retention,以及定義storage scheme,不需要手動做,graphite會自動幫你按照不同的scheme實現aggregation。這樣每個metric的大小就是固定的了,所以理論上可以永久儲存資料。graphite的叢集方案主要有兩種,分別是使用graphite自帶的relay或是使用第三方的工具。
當使用自帶的relay時,只需要在配置檔案中配置要relay到哪些機器即可,這樣在資料寫入的時候,被寫入的節點會relay一份到這些機器中。在讀取的時候,在graphite web的settings中配置HOSTS的列表,這樣在django的web中會依次從這些HOSTS中讀出資料。
另一種是需用第三方的relay工具,Booking公司開源出來了他們所用的用C寫得 carbon-c-relay,以及用GO寫得carbon-relay-ng。其基本的思想是運用一致性雜湊,可以將不同的metric發到不同的機器,以來達到叢集的目的,據Booking稱他們的graphite叢集的規模達到了百臺機器,而mertic也達到了百萬的級別.
以上的兩種方式都會遇到了一個共同的問題,就是叢集擴容的問題,我不知道Booking是怎麼來解決這個問題的,但是我這邊目前是想到了幾種方式,這個在我前一篇的文章中已經闡述了:graphite叢集擴容方案探究,在這裡就先不贅述了。
最後說一下,除了叢集問題以外,graphite的還有一效能問題就是讀的效能稍差,這決定於其儲存的方式,其實在讀的時候會去讀whisper檔案(雖然在django層做了快取,但是快取的功能比較弱),通過seek的方式來獲取資料的位置,在將資料取出。
opentsdb
opentsdb是一個比較重的時間序列解決方案,為什麼說他重呢?因為它的組成是這樣的:
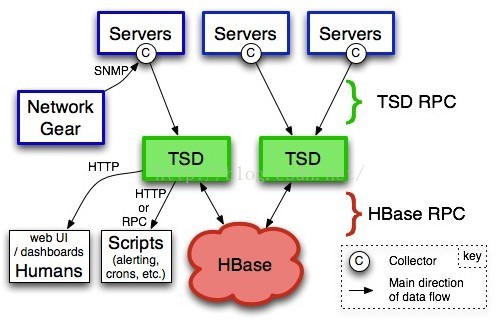
可以看到opentsdb所依賴的儲存是Hbase叢集。TSD在其中擔任的責任是IO部分,TSD其實就是一個後臺的daemon,一般我會會用一組TSD達成一個TSD的叢集(其實不能算是叢集),沒有master/slave之分,也沒有共享狀態,然後在之前用LB裝置來做負載均衡,官方比較推薦的是用varnish。
當讓後端的儲存也可以用其他的例如hadoop,但是官方還是建議用Hbase,因為opentsdb就是Hbase社群孵化出來的產品。那麼問題來了,Hbase的運維將是一個艱鉅的任務,這個依賴於zookeeper搭建的叢集的坑還是很多的,我看了一下官方文件就有上千頁。這裡面的優化維護需要有專業的Hbase專家才能完成。
另外opentsdb做不到graphite那樣自動做downsample,也就是做不到RRD那樣地去儲存資料,需要在外面自己做一層手動幹這活,再把聚合後的資料寫入Hbase,唉,還真是一個費時費力的活。
除此之外opentsdb還是很不錯的,讀寫效能挺高,而且支援tag,支援ttl,支援各種聚合函式。現在很多的監控的metric的儲存都是用的opentsdb,嗯,是的,只要有能力玩轉還是個不錯的選擇。
influxdb
influxdb是最新的一個時間序列資料庫,最新一兩年才產生,但已經擁有極高的人氣。influxdb 是用Go寫的,現在v0.9正在開發中,之前開源出來的最穩定的版本是0.88的,但是0.8X是沒有叢集方案的,但在0.9中會加入進來。
0.9版本的influxdb對於之前會有很大的改變,後端儲存有LevelDB換成了BoltDB,讀寫的API也是有了很大的變化,也將支援叢集化,continuous query,支援retention policy,讀寫效能也是哇哇的,可以說是時間序列儲存的完美方案,但是由於還很年輕,可能還會存在諸多的問題,就像現在正在開發的0.9一樣,釋出一拖再拖,就是由於還有些技術壁壘沒有攻陷。
對於influxdb我不想多說些什麼,之後打算開一個專題,專門詳細來說一說這個玩意,因為我看國內幾乎沒有詳細的文章來講influxdb的。
總結
算是簡單地說了一下,目前比較常用的三個時間序列資料庫吧,可以看到各有優劣,在我們選型的時候,要根據自身情況來選擇最適合自己的解決方案,其實我們現在也正在苦惱中,看似influxdb是最完美的解決方案,但是v0.9卻是遲遲不出。opentsdb呢,雖然成熟,但是缺乏這方面的專家;graphite呢,效能太差,而且叢集太死了。苦惱中啊……