
時間序列資料庫TSDB排名
DB-Engines 中時序列資料庫排名
我們先來看一下DB-Engines中關於時序列資料庫的排名,這是當前(2016年2月的)排名情況:
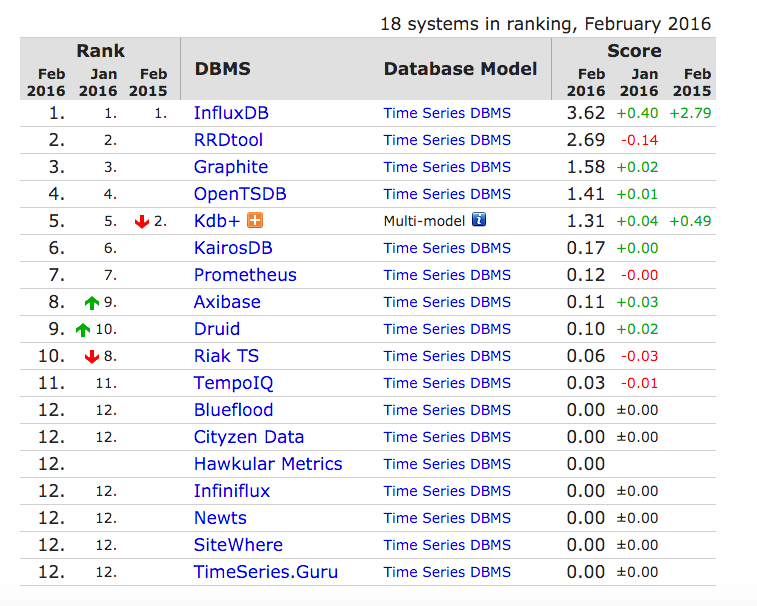
下面,我們就按照這個排名的順序,簡單介紹一下這些時序列資料庫中的一些。下面要介紹的 TSDB 以開源的為主,如果是商業或者 SaaS 服務,也簡單介紹一下其特點,讓大家能對其他領域的事物也有所瞭解。
這裡有一個例外,就是 Pinot 並不在這個排名裡,但是我也把它列在了這裡。
1. InfluxDB
InfluxDB 由 Golang 語言編寫,也是由 Golang 編寫的軟體中比較著名的一個,在很多 Golang 的沙龍或者文章中可能都會把 InfluxDB 當標杆來介紹,這也間接幫助 InfluxDB 提高了知名度。
InfluxDB的主要特點包括下面這些:
- schemaless(無結構),可以是任意數量的列
- 可擴充套件(叢集)
- 方便、強大的查詢語言
- Native HTTP API
- 集成了資料採集、儲存、視覺化功能
- 實時資料 Downsampling
- 高效儲存,使用高壓縮比演算法,支援retention polices
InfluxDB 是 TSDB 中為數不多的進行了使用者和角色方面實現的,提供了 Cluster Admin、Database Admin 和 Database User 三種角色。
InfluxDB 的資料採集系統也支援多種協議和外掛: - 行文字 - UDP - Graphite - CollectD - OpenTSDB
不過 InfluxDB 每次變動都較大,尤其是在儲存和叢集方面,追求平平安過日子,不想瞎折騰的可以考慮下。
注意:由於InfluxDB開發太活躍了,很可能你在網上搜到的資料都是老的,會害到你,所以你需要以官方文件為主。
一句話總結:欣欣向榮、值得一試。
2. RRDtool

RRDtool 全稱為 Round Robin Database Tool,也就是用於操作 RRD 的工具,簡單明瞭的軟體名。
什麼是 RRD 呢?簡單來說它就是一個迴圈使用的固定大小的資料庫檔案(其實也不太像典型的資料庫)。
大體來說,RRDtool 提供的主要工具如下:
- 建立RRD(rrdtool create)
- 更新RRD(rrdtool update)
- 畫圖(rrdtool graph)
這其中,畫圖功能是最複雜也是最強大的,甚至支援下面這些圖形,這是其他 TSDB 中少見的:
- 指標比較,對兩個指標值進行計算,描畫出滿足條件的區域
- 移動平均線
- 和歷史資料進行對比
- 基於最小二乘法的線性預測
- 曲線預測
- 總之,它的畫圖功能太豐富了。
一句話總結:老牌經典、藝多不壓身。
3. Graphite

Graphite 由 Orbitz, LLC 的 Chris Davis 創立於 2006 年,它主要有兩個功能:
- 儲存數值型時序列資料
- 根據請求對資料進行視覺化(畫圖)
相應的,它的特點為:
- 分散式時序列資料儲存,容易擴充套件
- 功能強大的畫圖Web API,提供了大量的函式和輸出方式
- Graphite本身不帶資料採集功能,但是你可以選擇很多第三方外掛,比如適用於* collectd、Ganglia或Sensu的外掛等。同時,Graphite也支援Plaintext、Pickle和AMQP這些資料輸入方式。
Graphite主要由三個模組組成:
- whisper:建立、更新RRD檔案
- carbon:以守護程序的形式執行,接收資料寫入請求
- carbon-cache:資料儲存
- carbon-relay:分割槽和複製,位於carbon-cache之前,類似carbon-cache的負載均衡
- carbon-aggregator:資料集計,用於減輕carbon-cache的負載
- graphite-web:用於讀取、展示資料的Web應用
whisper 使用了類似 RRDtool 的 RRD 檔案格式,它也不像 C/S 結構的軟體一樣,沒有服務程序,只是作為 Python library 使用,提供對資料的 create/update/fetch 操作。
如果你對它的效能比較在意,這裡有一份老的資料可供參考。
Google、Etsy、GitHub、豆瓣、Instagram、Evernote 和 Uber 等很多知名公司都是 Graphite 的使用者。有此背景,其可信度又加一層,而且網上的資料也相當的多,值得評估一下。
一句話總結:群眾基礎好、可以參考。
4. OpenTSDB

OpenTSDB 是一個分散式、可伸縮的時間序列資料庫。它支援豪秒級資料採集所有 metrics,支援永久儲存(不需要 downsampling),和 InfluxDB 類似,它也是無模式,以 tag 來實現維度的概念。
比如,這就是它的一個metric例子:
mysql.bytes_received 1287333217 66666666 schema=foo host=db1 |
OpenTSDB 的節點稱為 TSD(Time Series Daemon (TSD)),它沒有主、從之分,消除了單點隱患,非常容易擴充套件。它主要以HBase作為儲存系統,現在也增加了對 Cassandra 和 Bigtable(非雲端)。
OpenTSDB 以資料儲存和查詢為主,附帶了一個簡單地圖形介面(依賴Gnuplot),共開發、除錯使用。
一句話總結:好用,Cloud Insight也在用這項技術來實現對效能指標進行聚合、分組、過濾。
5.KDB+

所有 TSDB 中,估計就數這個最酷了,我說的是域名,只有兩個字母,猥瑣地想一下,域名就值很多錢 :-)。
kdb+是一個面向列的時序列資料庫,以及專門為其設計的查詢語言q(和他們的域名一樣簡短)。Kdb+ 混合使用了流、記憶體和實時分析,速度很快,支援分析 10 億級別的記錄以及快速訪問TB級別的歷史資料。
不過這是一個商業產品,但是也提供了免費版本(貌似還限制在32位)。
6.KairosDB

KairosDB 是一個 OpenTSDB 的 fork,不過是基於 Cassandra 儲存的。由於 Cassandra 的行比 HBase 寬,所以 KairosDB 的 Cassandra 的預設行大小為 3 星期,而 OpenTSDB 的 HBase 則為 1 小時。
KairosDB 支援通過 Telnet、Rest、Graphite 等協議寫入資料,你也可以通過編寫外掛自己實現資料寫入。
KairosDB 也提供了基於 Web API 的查詢介面,支援資料聚合、持過濾和分組等功能。
同時 KairosDB 提供了一個供開發用的 Web UI,圖形繪製引擎使用了 Flot。
和 OpenTSDB 類似,KairosDB 也提供了外掛機制,你可以使用外掛完成如下工作:
- 新增資料點(data point)監聽器
- 新增新的資料儲存服務
- 新增新的協議處理程式
- 新增自定義系統監視服務
7.Druid

Druid 是一個快速、近實時的海量資料 OLAP 系統,並且是開源的。Druid 誕生於 Metamarkets,後來一些核心人員創立了 IMPLY 公司,進行 Druid 相關的產品開發。
Druid 會按時間來進行分割槽(segment),並且是面向列儲存的。它的主要特性如下:
- 支援巢狀資料的列式儲存
- 層級查詢
- 二級索引
- 實時資料攝取
- 分散式容錯架構
根據去年底 druid.io 的白皮書,現在生產環境下最大的叢集規模如下:
- >3M EVENTS / SECOND SUSTAINED (200B+ EVENTS/DAY)
- 10 – 100K EVENTS / SECOND / CORE
- >500TB OF SEGMENTS (>50 TRILLION RAW EVENTS)
- >5000 CORES (>400 NODES, >100TB RAM)
- QUERY LATENCY (500MS AVERAGE)
- 90% < 1S 95% < 2S 99% < 10S
- 3+ trillion events/month
- 3M+ events/sec through Druid’s real-time ingestion
- 100+ PB of raw data
- 50+ trillion events
Druid 企業使用者比較多,比如 Netflix、Paypal 等。具體可以參考http://druid.io/druid-powered.html。
Druid 架構比較複雜,因此對部署和運維也有一定的負擔,比如需要的機器多、機器配置要高(尤其是記憶體)。
一句話總結:好用,我們在用。
8.Prometheus
Prometheus 是一個開源的服務監控系統和時序列資料庫,由社交音樂平臺 SoundCloud 在2012年開發,最近也變得很流行,最新版本為 0.17.0rc2。
Prometheus 從各種輸入源採集 metric,進行計算後顯示結果,或者根據指定條件出發報警。
和其他監控系統相比,Prometheus 的特點包括:
- 多維資料模型(時序列資料由metric名和一組key/value組成)
- 靈活的查詢語言
- 不依賴分散式儲存,單臺伺服器即可工作
- 通過基於HTTP的pull方式採集是序列資料
- 可以通過中間閘道器進行時序列資料推送
- 多種視覺化和儀表盤支援
由於 Prometheus 採用了類似 OpenTSDB 和 InfluxDB 的 key/value 維度機制,所以如果你對任一種 TSDB 有了解的話,學習起來會簡單些。
一句話總結:貌似比較火,何不試一試?
9.Pinot
Pinot 是一個開源的實時、分散式 OLAP 資料儲存方案。它來自 Linkedin,雖然 Linkedin 最近估價表現很差,但是他們建立的各種軟體、中介軟體實在太多了。這一點我們做軟體的都應該向 Linkedin 表示感謝。
Pinot 就像是一個 Druid 的 copy,不過兩者的靈感都來源於SenseiDB(Sensei 在日語裡為老師的意思,寫成漢字為“先生”)。
Pinot 也像 Druid 一樣,能載入 offline 資料(Hadoop 檔案)和實時資料(Kafka)。Pinot 從設計上就面向水平擴充套件。
Pinot 主要特點:
- 面向列
- 插拔式索引引擎:排序索引、點陣圖索引和反向索引
- 根據查詢語句和segment資訊對查詢/執行計劃進行優化
- 從 Kafka 實時資料攝取(ingestion)
- 從 Hadoop 進行批量攝取
- 類似 SQL 的查詢語言,支援聚合、過濾、分組、排序和唯一處理。
- 支援多值欄位
- 水平擴充套件和容錯
Pinot 的特點和 Druid 很像,兩者可互為參考。
一句話總結:背靠大樹好乘涼。