
net.sz.framework 框架 ORM 消消樂超過億條資料排行榜分析 天王蓋地虎
序言
天王蓋地虎,
老婆馬上生孩子了,在家待產,老婆喜歡玩消消樂類似的休閒遊戲,閒置狀態,無聊的分析一下消消樂遊戲的一些技術問題;
由於我主要是伺服器研發,客戶端屬於半吊子,所以就分析一下消消樂排行榜問題;
第一章
消消樂排行榜大致分為好友排行榜和全國排行榜;
好友排行榜和全國排行榜的其實是重合的只是需要從全國排行榜中提取出來而已;
那麼就需要記錄所有玩家的通關記錄已進行查詢;
也許你說全國排行榜只顯示前xxx名就好;但是你的好友記錄必須要的吧?你的好友不可能全部進入全國排行榜吧;
而好友排行榜基本都是要去全部顯示出來排名;
所有那麼問題來了:
我們加入400萬用戶,那麼每一關卡都會有400萬記錄;
目前消消樂關卡開始1200關,那麼就是400萬 x 1200 = 48億條資料;這他媽的嚇死人啊;
消消樂遊戲,最大的技術關鍵是排行榜查詢問題,反而寫入速度,和頻率卻不高;
還有重要的一點是每一關卡的玩家流失率大約:0.xx%;
由於我在家休息中,家裡開發環境限制所以設定資料存在是sqlite、mysql資料庫,其他資料庫有待研究;如果redis 牽涉排序問題,搜尋問題,麼有想到好的方案;
第二章
我首先設計通關記錄儲存表結構模型;
需要,玩家id,通關關卡,通關星級,通關積分,通關時間


1 class TopList extends DataBaseModel implements Serializable, Cloneable {View Code2 3 /*玩家id*/ 4 private long pid; 5 /*關卡*/ 6 private int point; 7 /*星級*/ 8 private int star; 9 /*通關時間*/ 10 private long time; 11 /*積分*/ 12 private int integral; 13 14 public long getPid() { 15 return pid; 16 } 17 18 public void setPid(long pid) {19 this.pid = pid; 20 } 21 22 public int getPoint() { 23 return point; 24 } 25 26 public void setPoint(int point) { 27 this.point = point; 28 } 29 30 public int getStar() { 31 return star; 32 } 33 34 public void setStar(int star) { 35 this.star = star; 36 } 37 38 public long getTime() { 39 return time; 40 } 41 42 public void setTime(long time) { 43 this.time = time; 44 } 45 46 public int getIntegral() { 47 return integral; 48 } 49 50 public void setIntegral(int integral) { 51 this.integral = integral; 52 } 53 54 @Override 55 public Object clone() { 56 try { 57 return super.clone(); //To change body of generated methods, choose Tools | Templates. 58 } catch (CloneNotSupportedException ex) { 59 } 60 return null; 61 } 62 63 }
測試程式碼
1 public static void main(String[] args) throws Exception { 2 3 SqliteDaoImpl sdi = new SqliteDaoImpl("/home/toplist.db"); 4 TopList topList = new TopList(); 5 6 CUDThread cudt = new CUDThread(sdi, "top-list-thread"); 7 /*設定非同步操作的緩衝容量*/ 8 cudt.setMaxTaskCount(500000); 9 /*設定單次寫入的資料量*/ 10 cudt.setGetTaskMax(5000); 11 /*建立表*/ 12 sdi.createTable(topList); 13 14 /*id生成器*/ 15 LongId0 longId0 = new LongId0(); 16 17 /*模擬5萬個玩家*/ 18 for (int i = 0; i < 50000; i++) { 19 long id = longId0.getId(); 20 /*模擬500關卡*/ 21 for (int j = 1; j <= 500; j++) { 22 23 TopList clone = (TopList) topList.clone(); 24 clone.setPid(id); 25 clone.setTime(System.currentTimeMillis()); 26 clone.setPoint(j); 27 clone.setStar(3); 28 /*隨機積分*/ 29 clone.setIntegral(RandomUtils.random(20000, 400000)); 30 31 cudt.insert_Sync(clone); 32 } 33 } 34 35 }
sqlite插入速度非常快,
[07-25 11:28:20:368:DEBUG:CUDThread.run():219] 新增資料插入影響行數:5000 耗時:115 [07-25 11:28:20:368:DEBUG:CUDThread.run():246] 當前待處理剩餘數量:7257 [07-25 11:28:20:524:DEBUG:CUDThread.run():219] 新增資料插入影響行數:5000 耗時:155 [07-25 11:28:20:524:DEBUG:CUDThread.run():246] 當前待處理剩餘數量:8342 [07-25 11:28:20:696:DEBUG:CUDThread.run():219] 新增資料插入影響行數:5000 耗時:172 [07-25 11:28:20:696:DEBUG:CUDThread.run():246] 當前待處理剩餘數量:9129 [07-25 11:28:20:818:DEBUG:CUDThread.run():219] 新增資料插入影響行數:5000 耗時:122 [07-25 11:28:20:818:DEBUG:CUDThread.run():246] 當前待處理剩餘數量:8188 [07-25 11:28:20:973:DEBUG:CUDThread.run():219] 新增資料插入影響行數:5000 耗時:154 [07-25 11:28:20:973:DEBUG:CUDThread.run():246] 當前待處理剩餘數量:8424
我們查詢一下資料庫;
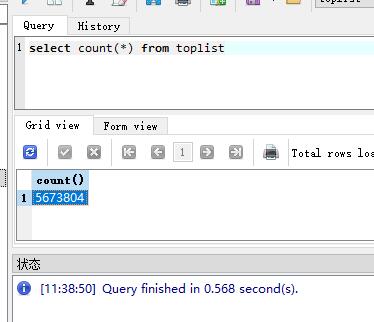
總資料是560多萬行資料;
查詢一下關卡資料
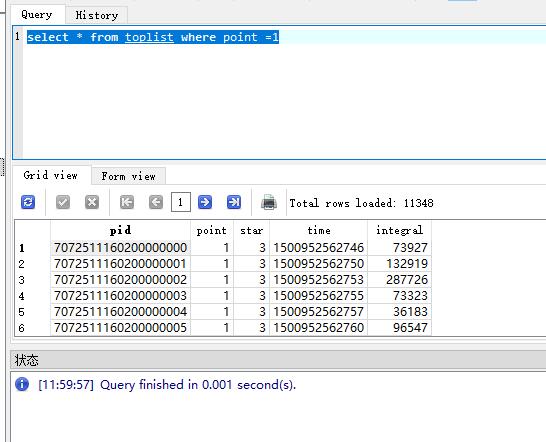
查詢關卡資料很快;
但是我需要排序
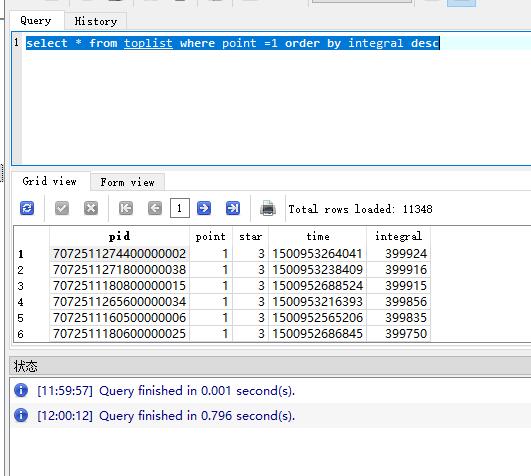
這些就看出對比了吧,這僅僅只有不到600萬條資料呢;而且我們僅僅是查詢了全國總排行,還麼有牽涉好友排行榜,多條件搜尋;
第三章
資料庫可以增加索引的,加入索引後,查詢會快很多;
那麼接下來我們修改模型,測試
1 class TopList extends DataBaseModel implements Serializable, Cloneable { 2 3 /*玩家id*/ 4 @AttColumn(index = true) 5 private long pid; 6 /*關卡*/ 7 @AttColumn(index = true) 8 private int point; 9 /*積分*/ 10 @AttColumn(index = true) 11 private int integral; 12 /*星級*/ 13 private int star; 14 /*通關時間*/ 15 private long time; 16 17 public long getPid() { 18 return pid; 19 } 20 21 public void setPid(long pid) { 22 this.pid = pid; 23 } 24 25 public int getPoint() { 26 return point; 27 } 28 29 public void setPoint(int point) { 30 this.point = point; 31 } 32 33 public int getStar() { 34 return star; 35 } 36 37 public void setStar(int star) { 38 this.star = star; 39 } 40 41 public long getTime() { 42 return time; 43 } 44 45 public void setTime(long time) { 46 this.time = time; 47 } 48 49 public int getIntegral() { 50 return integral; 51 } 52 53 public void setIntegral(int integral) { 54 this.integral = integral; 55 } 56 57 @Override 58 public Object clone() { 59 try { 60 return super.clone(); //To change body of generated methods, choose Tools | Templates. 61 } catch (CloneNotSupportedException ex) { 62 } 63 return null; 64 } 65 66 }View Code
修改模型,在玩家id,分數,關卡,這三個地方加入索引;
1 [07-25 13:11:04:759:DEBUG:CUDThread.run():219] 新增資料插入影響行數:5000 耗時:662 2 [07-25 13:11:04:760:DEBUG:CUDThread.run():246] 當前待處理剩餘數量:22525 3 [07-25 13:11:05:549:DEBUG:CUDThread.run():219] 新增資料插入影響行數:5000 耗時:787 4 [07-25 13:11:05:550:DEBUG:CUDThread.run():246] 當前待處理剩餘數量:24975 5 [07-25 13:11:06:437:DEBUG:CUDThread.run():219] 新增資料插入影響行數:5000 耗時:885 6 [07-25 13:11:06:438:DEBUG:CUDThread.run():246] 當前待處理剩餘數量:27030 7 [07-25 13:11:07:198:DEBUG:CUDThread.run():219] 新增資料插入影響行數:5000 耗時:759 8 [07-25 13:11:07:199:DEBUG:CUDThread.run():246] 當前待處理剩餘數量:27454 9 [07-25 13:11:08:023:DEBUG:CUDThread.run():219] 新增資料插入影響行數:5000 耗時:823 10 [07-25 13:11:08:027:DEBUG:CUDThread.run():246] 當前待處理剩餘數量:27449 11 [07-25 13:11:08:966:DEBUG:CUDThread.run():219] 新增資料插入影響行數:5000 耗時:936 12 [07-25 13:11:08:967:DEBUG:CUDThread.run():246] 當前待處理剩餘數量:27900 13 [07-25 13:11:09:945:DEBUG:CUDThread.run():219] 新增資料插入影響行數:5000 耗時:977
資料庫資料越來越多的時候,插入速度就會越來越慢;看下圖,是不是很嚇人?
1 [07-25 13:15:06:511:DEBUG:CUDThread.run():246] 當前待處理剩餘數量:23473 2 [07-25 13:15:10:948:DEBUG:CUDThread.run():219] 新增資料插入影響行數:5000 耗時:4434 3 [07-25 13:15:10:950:DEBUG:CUDThread.run():246] 當前待處理剩餘數量:42028 4 [07-25 13:15:14:666:DEBUG:CUDThread.run():219] 新增資料插入影響行數:5000 耗時:3715 5 [07-25 13:15:14:668:DEBUG:CUDThread.run():246] 當前待處理剩餘數量:49338
也許與我當前筆記本硬碟有關係;電腦效能佔用問題;

插入速度是慢了,我們來看看查詢速度吧,
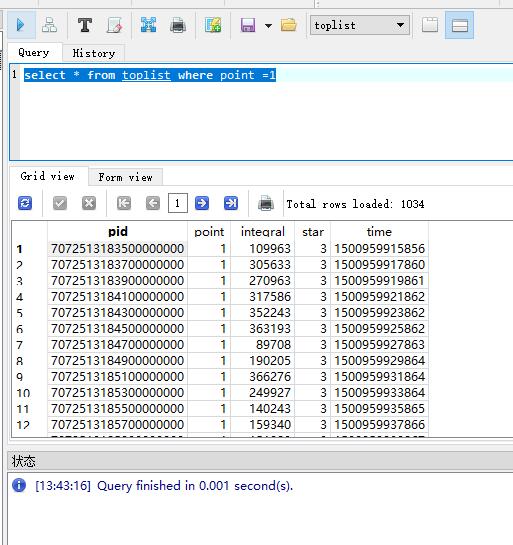
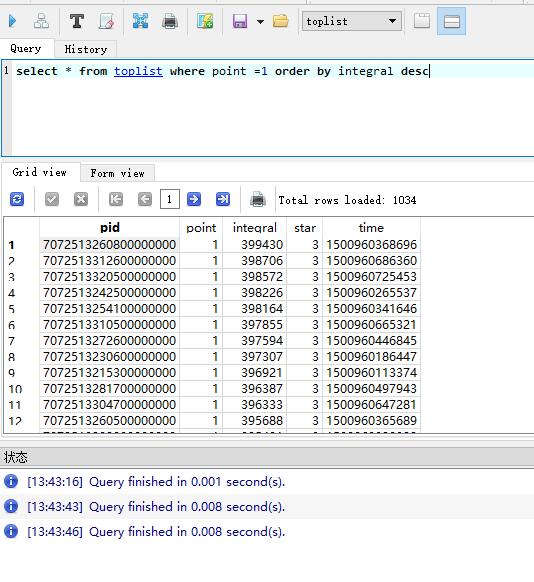
我們可以看到插入速度快很多;
當然此時的資料量確實麼有之前的多,因為測試問題,插入的資料的確實很慢,
如果是mysql 資料庫,還需要加入聯合索引查詢才會翻倍提升效能;mysql插入速度會比sqlite好一點,因為sqlie本身就不適用於大型資料集合;
第四章
其實以上工作只是做到了索引優化問題;但是也抵不住越來越多的資料;對不對?
所以還是的尋求其他方式來解決問題;
我們先來分析情況
可以建立分割槽表形式;但是建立分割槽表,資料也只是在一個表內大hash集合,然後區分的小hash集合,然後就算mysql這種官方建議的分割槽表都是200萬條資料;
所以沒有嘗試過;有興趣的同學可以研究研究;
我想到的第二種方式,分表,之前在做遊戲運營後臺,接受來之多個遊戲的運營日誌資料,就採用了這種方式,分表,每一天一張表,來劃分;
所以我很快又想到了這種方式,我以每一個關卡劃分通關資料記錄,
可是仔細一想肯定不行啊,因為按照現在消消樂這種遊戲來說1200關,1000多張表,維護都得忙死;而且越往後越更新越多,依然不可行!
任何遊戲只要在生存週期內,就有有人加入,有人流失;
那麼消消樂這種關卡類的遊戲,那麼資料量永遠都在前面關卡,越往後越少,就跟我前面說的一樣,每一關卡都會流失0.xxx%;
那麼我們可以設計30張表,30張總能接受了吧?
起碼我是能接受了;
可是如何優雅的利用30張表資料的呢?
我們分析可得越靠前的關卡,資料越多,
那麼我們設計前800關卡的資料存入20張表;
後面的所以表記錄到剩餘的10張表中;
建立表,獲取表名的簡易演算法;
1 /** 2 * 獲取表名 3 * 4 * @param point 5 * @return 6 */ 7 static String getTableName(int point) { 8 int tableId = 0; 9 if (point < 300) { 10 /*第一段前300關存入15張表*/ 11 tableId = 1000 + point % 15; 12 } else if (point < 800) { 13 /*第二段後500關卡存入5張表*/ 14 tableId = 2000 + point % 5; 15 } else { 16 /*800關卡以後的資料存入剩餘10張表*/ 17 tableId = 3000 + point % 10; 18 } 19 20 return TopList.class.getSimpleName().toLowerCase() + tableId; 21 }
建立表
1 int points = 1200; 2 3 TopList topList = new TopList(); 4 for (int i = 1; i <= points; i++) { 5 topList.setDataTableName(getTableName(i)); 6 /*建立表*/ 7 sdi.createTable(topList); 8 }
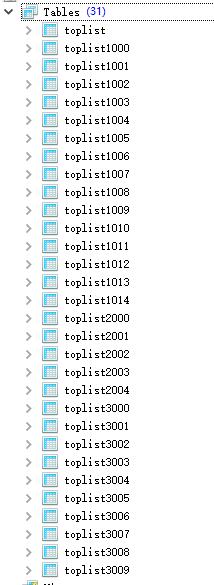
表自動建立完成;
1 /*模擬5萬個玩家*/ 2 for (int i = 1; i <= 50000; i++) { 3 long id = longId0.getId(); 4 /*模擬關卡*/ 5 int j = 1; 6 for (; j <= points; j++) { 7 8 TopList clone = (TopList) topList.clone(); 9 clone.setDataTableName(getTableName(j)); 10 clone.setPid(id); 11 clone.setTime(System.currentTimeMillis()); 12 clone.setPoint(j); 13 clone.setStar(3); 14 /*隨機積分*/ 15 clone.setIntegral(RandomUtils.random(20000, 400000)); 16 17 cudt.insert_Sync(clone); 18 } 19 log.info("總共寫入資料量:" + (i * (j - 1))); 20 Thread.sleep(1000); 21 }
寫入速度,已經得到提升了,
1 [07-25 14:24:12:293:DEBUG:CUDThread.run():219] 新增資料插入影響行數:3000 耗時:2750 2 [07-25 14:24:12:294:DEBUG:CUDThread.run():246] 當前待處理剩餘數量:3600 3 [07-25 14:24:12:605:INFO :TopTest.main():68] 總共寫入資料量:222185 4 [07-25 14:24:13:619:INFO :TopTest.main():68] 總共寫入資料量:223386 5 [07-25 14:24:14:647:INFO :TopTest.main():68] 總共寫入資料量:224587 6 [07-25 14:24:14:757:DEBUG:CUDThread.run():219] 新增資料插入影響行數:3000 耗時:2463 7 [07-25 14:24:14:758:DEBUG:CUDThread.run():246] 當前待處理剩餘數量:4200 8 [07-25 14:24:15:690:INFO :TopTest.main():68] 總共寫入資料量:225788 9 [07-25 14:24:16:709:INFO :TopTest.main():68] 總共寫入資料量:226989 10 [07-25 14:24:17:502:DEBUG:CUDThread.run():219] 新增資料插入影響行數:3000 耗時:2744 11 [07-25 14:24:17:502:DEBUG:CUDThread.run():246] 當前待處理剩餘數量:3600 12 [07-25 14:24:17:743:INFO :TopTest.main():68] 總共寫入資料量:228190 13 [07-25 14:24:18:755:INFO :TopTest.main():68] 總共寫入資料量:229391 14 [07-25 14:24:19:783:INFO :TopTest.main():68] 總共寫入資料量:230592 15 [07-25 14:24:20:250:DEBUG:CUDThread.run():219] 新增資料插入影響行數:3000 耗時:2748 16 [07-25 14:24:20:250:DEBUG:CUDThread.run():246] 當前待處理剩餘數量:4200 17 [07-25 14:24:20:824:INFO :TopTest.main():68] 總共寫入資料量:231793 18 [07-25 14:24:21:843:INFO :TopTest.main():68] 總共寫入資料量:232994
查詢速度在第三章已經驗證了,就不在驗證;
總結
像消消樂這型別遊戲重點就在於排行榜資料儲存和讀取,然後寫入和讀取相比,寫入的需求遠遠小於讀取的需求;
我做的是實時資料排行榜區分;
當然我們還可以利用mysql的主從關係,提供讀寫分離情況,做非實時排行榜資料;
也可以利用非滑動快取來做非實時排行榜,解決寫入和讀取的效能平衡問題,快取可以設定比如每5分鐘或者每10分鐘更新一次排行榜資料來完成;
以上分析就不再做程式碼測試;
這是我分析和我的解決方案,不知道屌大的園友們還要更好的解決方案嗎?


