
關於SimHash去重原理的理解(能力工場小馬哥)
閱讀目錄
- 1. SimHash與傳統hash函式的區別
- 2. SimHash演算法思想
- 3. SimHash流程實現
- 4. SimHash簽名距離計算
- 5. SimHash儲存和索引
- 6. SimHash儲存和索引
- 7. 參考內容
在之前的兩篇博文分別介紹了常用的hash方法([Data Structure & Algorithm] Hash那點事兒)以及區域性敏感hash演算法([Algorithm] 區域性敏感雜湊演算法(Locality Sensitive Hashing)),本文介紹的SimHash是一種區域性敏感hash,它也是Google公司進行海量網頁去重使用的主要演算法。
1. SimHash與傳統hash函式的區別
傳統的Hash演算法只負責將原始內容儘量均勻隨機地對映為一個簽名值,原理上僅相當於偽隨機數產生演算法。傳統的hash演算法產生的兩個簽名,如果原始內容在一定概率下是相等的;如果不相等,除了說明原始內容不相等外,不再提供任何資訊,因為即使原始內容只相差一個位元組,所產生的簽名也很可能差別很大。所以傳統的Hash是無法在簽名的維度上來衡量原內容的相似度,而SimHash本身屬於一種區域性敏感雜湊演算法,它產生的hash簽名在一定程度上可以表徵原內容的相似度。
我們主要解決的是文字相似度計算,要比較的是兩個文章是否相識,當然我們降維生成了hash簽名也是用於這個目的。看到這裡估計大家就明白了,我們使用的simhash就算把文章中的字串變成 01 串也還是可以用於計算相似度的,而傳統的hash卻不行。我們可以來做個測試,兩個相差只有一個字元的文字串,“你媽媽喊你回家吃飯哦,回家羅回家羅” 和 “你媽媽叫你回家吃飯啦,回家羅回家羅”。
通過simhash計算結果為:
1000010010101101111111100000101011010001001111100001001011001011
1000010010101101011111100000101011010001001111100001101010001011
通過傳統hash計算為:
0001000001100110100111011011110
1010010001111111110010110011101
大家可以看得出來,相似的文字只有部分 01 串變化了,而普通的hash卻不能做到,這個就是區域性敏感雜湊的魅力。
回到頂部2. SimHash演算法思想
假設我們有海量的文字資料,我們需要根據文字內容將它們進行去重。對於文字去重而言,目前有很多NLP相關的演算法可以在很高精度上來解決,但是我們現在處理的是大資料維度上的文字去重,這就對演算法的效率有著很高的要求。而區域性敏感hash演算法可以將原始的文字內容對映為數字(hash簽名),而且較為相近的文字內容對應的hash簽名也比較相近。SimHash演算法是Google公司進行海量網頁去重的高效演算法,它通過將原始的文字對映為64位的二進位制數字串,然後通過比較二進位制數字串的差異進而來表示原始文字內容的差異。
3. SimHash流程實現
simhash是由 Charikar 在2002年提出來的,本文為了便於理解儘量不使用數學公式,分為這幾步:
(注:具體的事例摘自Lanceyan的部落格《海量資料相似度計算之simhash和海明距離》)
-
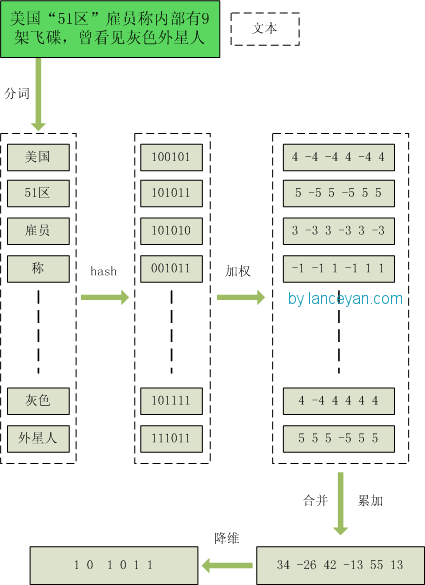
1、分詞,把需要判斷文字分詞形成這個文章的特徵單詞。最後形成去掉噪音詞的單詞序列併為每個詞加上權重,我們假設權重分為5個級別(1~5)。比如:“ 美國“51區”僱員稱內部有9架飛碟,曾看見灰色外星人 ” ==> 分詞後為 “ 美國(4) 51區(5) 僱員(3) 稱(1) 內部(2) 有(1) 9架(3) 飛碟(5) 曾(1) 看見(3) 灰色(4) 外星人(5)”,括號裡是代表單詞在整個句子裡重要程度,數字越大越重要。
-
2、hash,通過hash演算法把每個詞變成hash值,比如“美國”通過hash演算法計算為 100101,“51區”通過hash演算法計算為 101011。這樣我們的字串就變成了一串串數字,還記得文章開頭說過的嗎,要把文章變為數字計算才能提高相似度計算效能,現在是降維過程進行時。
-
3、加權,通過 2步驟的hash生成結果,需要按照單詞的權重形成加權數字串,比如“美國”的hash值為“100101”,通過加權計算為“4 -4 -4 4 -4 4”;“51區”的hash值為“101011”,通過加權計算為 “ 5 -5 5 -5 5 5”。
-
4、合併,把上面各個單詞算出來的序列值累加,變成只有一個序列串。比如 “美國”的 “4 -4 -4 4 -4 4”,“51區”的 “ 5 -5 5 -5 5 5”, 把每一位進行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”。這裡作為示例只算了兩個單詞的,真實計算需要把所有單詞的序列串累加。
-
5、降維,把4步算出來的 “9 -9 1 -1 1 9” 變成 0 1 串,形成我們最終的simhash簽名。 如果每一位大於0 記為 1,小於0 記為 0。最後算出結果為:“1 0 1 0 1 1”。
整個過程的流程圖為:
4. SimHash簽名距離計算
我們把庫裡的文字都轉換為simhash簽名,並轉換為long型別儲存,空間大大減少。現在我們雖然解決了空間,但是如何計算兩個simhash的相似度呢?難道是比較兩個simhash的01有多少個不同嗎?對的,其實也就是這樣,我們通過海明距離(Hamming distance)就可以計算出兩個simhash到底相似不相似。兩個simhash對應二進位制(01串)取值不同的數量稱為這兩個simhash的海明距離。舉例如下: 10101 和 00110 從第一位開始依次有第一位、第四、第五位不同,則海明距離為3。對於二進位制字串的a和b,海明距離為等於在a XOR b運算結果中1的個數(普遍演算法)。
回到頂部5. SimHash儲存和索引
經過simhash對映以後,我們得到了每個文字內容對應的simhash簽名,而且也確定了利用漢明距離來進行相似度的衡量。那剩下的工作就是兩兩計算我們得到的simhash簽名的漢明距離了,這在理論上是完全沒問題的,但是考慮到我們的資料是海量的這一特點,我們是否應該考慮使用一些更具效率的儲存呢?其實SimHash演算法輸出的simhash簽名可以為我們很好建立索引,從而大大減少索引的時間,那到底怎麼實現呢?
這時候大家有沒有想到hashmap呢,一種理論上具有O(1)複雜度的查詢資料結構。我們要查詢一個key值時,通過傳入一個key就可以很快的返回一個value,這個號稱查詢速度最快的資料結構是如何實現的呢?看下hashmap的內部結構:
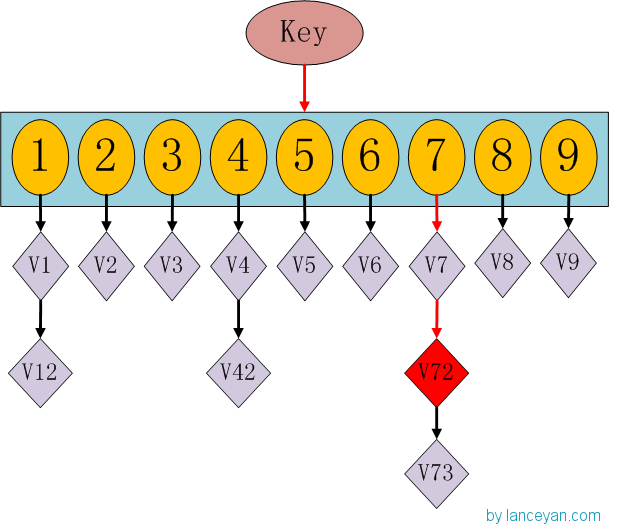
如果我們需要得到key對應的value,需要經過這些計算,傳入key,計算key的hashcode,得到7的位置;發現7位置對應的value還有好幾個,就通過連結串列查詢,直到找到v72。其實通過這麼分析,如果我們的hashcode設定的不夠好,hashmap的效率也不見得高。借鑑這個演算法,來設計我們的simhash查詢。通過順序查詢肯定是不行的,能否像hashmap一樣先通過鍵值對的方式減少順序比較的次數。看下圖:
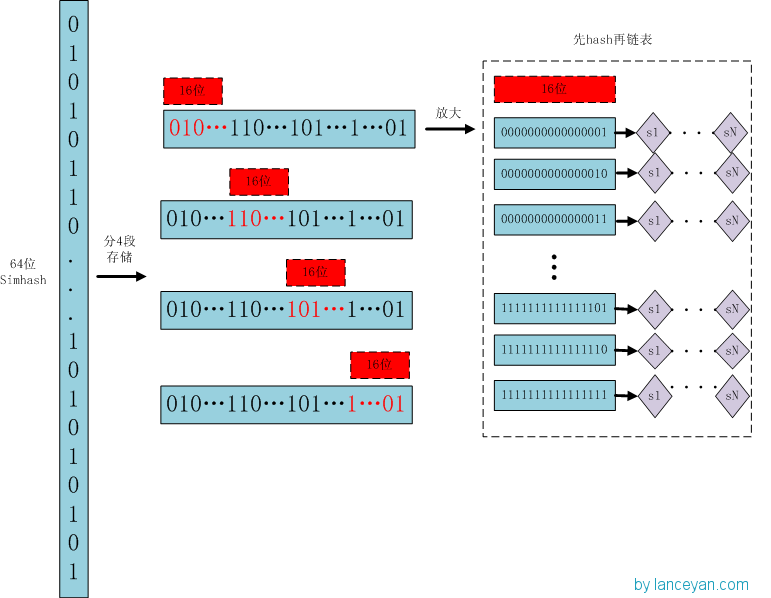
儲存:
1、將一個64位的simhash簽名拆分成4個16位的二進位制碼。(圖上紅色的16位)
2、分別拿著4個16位二進位制碼查詢當前對應位置上是否有元素。(放大後的16位)
3、對應位置沒有元素,直接追加到連結串列上;對應位置有則直接追加到連結串列尾端。(圖上的 S1 — SN)
查詢:
1、將需要比較的simhash簽名拆分成4個16位的二進位制碼。
2、分別拿著4個16位二進位制碼每一個去查詢simhash集合對應位置上是否有元素。
3、如果有元素,則把連結串列拿出來順序查詢比較,直到simhash小於一定大小的值,整個過程完成。
原理:
借鑑hashmap演算法找出可以hash的key值,因為我們使用的simhash是區域性敏感雜湊,這個演算法的特點是隻要相似的字串只有個別的位數是有差別變化。那這樣我們可以推斷兩個相似的文字,至少有16位的simhash是一樣的。具體選擇16位、8位、4位,大家根據自己的資料測試選擇,雖然比較的位數越小越精準,但是空間會變大。分為4個16位段的儲存空間是單獨simhash儲存空間的4倍。之前算出5000w資料是 382 Mb,擴大4倍1.5G左右,還可以接受
6. SimHash儲存和索引
1. 當文字內容較長時,使用SimHash準確率很高,SimHash處理短文字內容準確率往往不能得到保證;
2. 文字內容中每個term對應的權重如何確定要根據實際的專案需求,一般是可以使用IDF權重來進行計算。
回到頂部7. 參考內容
1. 嚴瀾的部落格《海量資料相似度計算之simhash短文字查詢》
2. 《Similarity estimation techniques from rounding algorithms》
聯絡本文作者交流或者索取相關程式碼及軟體請加入QQ群:小馬哥的技術分享 413939157.閱讀目錄
- 1. SimHash與傳統hash函式的區別
- 2. SimHash演算法思想
- 3. SimHash流程實現
- 4. SimHash簽名距離計算
- 5. SimHash儲存和索引
- 6. SimHash儲存和索引
- 7. 參考內容
在之前的兩篇博文分別介紹了常用的hash方法([Data Structure & Algorithm] Hash那點事兒)以及區域性敏感hash演算法([Algorithm] 區域性敏感雜湊演算法(Locality Sensitive Hashing)),本文介紹的SimHash是一種區域性敏感hash,它也是Google公司進行海量網頁去重使用的主要演算法。
回到頂部1. SimHash與傳統hash函式的區別
傳統的Hash演算法只負責將原始內容儘量均勻隨機地對映為一個簽名值,原理上僅相當於偽隨機數產生演算法。傳統的hash演算法產生的兩個簽名,如果原始內容在一定概率下是相等的;如果不相等,除了說明原始內容不相等外,不再提供任何資訊,因為即使原始內容只相差一個位元組,所產生的簽名也很可能差別很大。所以傳統的Hash是無法在簽名的維度上來衡量原內容的相似度,而SimHash本身屬於一種區域性敏感雜湊演算法,它產生的hash簽名在一定程度上可以表徵原內容的相似度。
我們主要解決的是文字相似度計算,要比較的是兩個文章是否相識,當然我們降維生成了hash簽名也是用於這個目的。看到這裡估計大家就明白了,我們使用的simhash就算把文章中的字串變成 01 串也還是可以用於計算相似度的,而傳統的hash卻不行。我們可以來做個測試,兩個相差只有一個字元的文字串,“你媽媽喊你回家吃飯哦,回家羅回家羅” 和 “你媽媽叫你回家吃飯啦,回家羅回家羅”。
通過simhash計算結果為:
1000010010101101111111100000101011010001001111100001001011001011
1000010010101101011111100000101011010001001111100001101010001011
通過傳統hash計算為:
0001000001100110100111011011110
1010010001111111110010110011101
大家可以看得出來,相似的文字只有部分 01 串變化了,而普通的hash卻不能做到,這個就是區域性敏感雜湊的魅力。
回到頂部2. SimHash演算法思想
假設我們有海量的文字資料,我們需要根據文字內容將它們進行去重。對於文字去重而言,目前有很多NLP相關的演算法可以在很高精度上來解決,但是我們現在處理的是大資料維度上的文字去重,這就對演算法的效率有著很高的要求。而區域性敏感hash演算法可以將原始的文字內容對映為數字(hash簽名),而且較為相近的文字內容對應的hash簽名也比較相近。SimHash演算法是Google公司進行海量網頁去重的高效演算法,它通過將原始的文字對映為64位的二進位制數字串,然後通過比較二進位制數字串的差異進而來表示原始文字內容的差異。
回到頂部3. SimHash流程實現
simhash是由 Charikar 在2002年提出來的,本文為了便於理解儘量不使用數學公式,分為這幾步:
(注:具體的事例摘自Lanceyan的部落格《海量資料相似度計算之simhash和海明距離》)
-
1、分詞,把需要判斷文字分詞形成這個文章的特徵單詞。最後形成去掉噪音詞的單詞序列併為每個詞加上權重,我們假設權重分為5個級別(1~5)。比如:“ 美國“51區”僱員稱內部有9架飛碟,曾看見灰色外星人 ” ==> 分詞後為 “ 美國(4) 51區(5) 僱員(3) 稱(1) 內部(2) 有(1) 9架(3) 飛碟(5) 曾(1) 看見(3) 灰色(4) 外星人(5)”,括號裡是代表單詞在整個句子裡重要程度,數字越大越重要。
-
2、hash,通過hash演算法把每個詞變成hash值,比如“美國”通過hash演算法計算為 100101,“51區”通過hash演算法計算為 101011。這樣我們的字串就變成了一串串數字,還記得文章開頭說過的嗎,要把文章變為數字計算才能提高相似度計算效能,現在是降維過程進行時。
-
3、加權,通過 2步驟的hash生成結果,需要按照單詞的權重形成加權數字串,比如“美國”的hash值為“100101”,通過加權計算為“4 -4 -4 4 -4 4”;“51區”的hash值為“101011”,通過加權計算為 “ 5 -5 5 -5 5 5”。
-
4、合併,把上面各個單詞算出來的序列值累加,變成只有一個序列串。比如 “美國”的 “4 -4 -4 4 -4 4”,“51區”的 “ 5 -5 5 -5 5 5”, 把每一位進行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”。這裡作為示例只算了兩個單詞的,真實計算需要把所有單詞的序列串累加。
-
5、降維,把4步算出來的 “9 -9 1 -1 1 9” 變成 0 1 串,形成我們最終的simhash簽名。 如果每一位大於0 記為 1,小於0 記為 0。最後算出結果為:“1 0 1 0 1 1”。
整個過程的流程圖為:
4. SimHash簽名距離計算
我們把庫裡的文字都轉換為simhash簽名,並轉換為long型別儲存,空間大大減少。現在我們雖然解決了空間,但是如何計算兩個simhash的相似度呢?難道是比較兩個simhash的01有多少個不同嗎?對的,其實也就是這樣,我們通過海明距離(Hamming distance)就可以計算出兩個simhash到底相似不相似。兩個simhash對應二進位制(01串)取值不同的數量稱為這兩個simhash的海明距離。舉例如下: 10101 和 00110 從第一位開始依次有第一位、第四、第五位不同,則海明距離為3。對於二進位制字串的a和b,海明距離為等於在a XOR b運算結果中1的個數(普遍演算法)。
回到頂部5. SimHash儲存和索引
經過simhash對映以後,我們得到了每個文字內容對應的simhash簽名,而且也確定了利用漢明距離來進行相似度的衡量。那剩下的工作就是兩兩計算我們得到的simhash簽名的漢明距離了,這在理論上是完全沒問題的,但是考慮到我們的資料是海量的這一特點,我們是否應該考慮使用一些更具效率的儲存呢?其實SimHash演算法輸出的simhash簽名可以為我們很好建立索引,從而大大減少索引的時間,那到底怎麼實現呢?
這時候大家有沒有想到hashmap呢,一種理論上具有O(1)複雜度的查詢資料結構。我們要查詢一個key值時,通過傳入一個key就可以很快的返回一個value,這個號稱查詢速度最快的資料結構是如何實現的呢?看下hashmap的內部結構:
如果我們需要得到key對應的value,需要經過這些計算,傳入key,計算key的hashcode,得到7的位置;發現7位置對應的value還有好幾個,就通過連結串列查詢,直到找到v72。其實通過這麼分析,如果我們的hashcode設定的不夠好,hashmap的效率也不見得高。借鑑這個演算法,來設計我們的simhash查詢。通過順序查詢肯定是不行的,能否像hashmap一樣先通過鍵值對的方式減少順序比較的次數。看下圖:
儲存:
1、將一個64位的simhash簽名拆分成4個16位的二進位制碼。(圖上紅色的16位)
2、分別拿著4個16位二進位制碼查詢當前對應位置上是否有元素。(放大後的16位)
3、對應位置沒有元素,直接追加到連結串列上;對應位置有則直接追加到連結串列尾端。(圖上的 S1 — SN)
查詢:
1、將需要比較的simhash簽名拆分成4個16位的二進位制碼。
2、分別拿著4個16位二進位制碼每一個去查詢simhash集合對應位置上是否有元素。
3、如果有元素,則把連結串列拿出來順序查詢比較,直到simhash小於一定大小的值,整個過程完成。
原理:
借鑑hashmap演算法找出可以hash的key值,因為我們使用的simhash是區域性敏感雜湊,這個演算法的特點是隻要相似的字串只有個別的位數是有差別變化。那這樣我們可以推斷兩個相似的文字,至少有16位的simhash是一樣的。具體選擇16位、8位、4位,大家根據自己的資料測試選擇,雖然比較的位數越小越精準,但是空間會變大。分為4個16位段的儲存空間是單獨simhash儲存空間的4倍。之前算出5000w資料是 382 Mb,擴大4倍1.5G左右,還可以接受
6. SimHash儲存和索引
1. 當文字內容較長時,使用SimHash準確率很高,SimHash處理短文字內容準確率往往不能得到保證;
2. 文字內容中每個term對應的權重如何確定要根據實際的專案需求,一般是可以使用IDF權重來進行計算。
回到頂部7. 參考內容
1. 嚴瀾的部落格《海量資料相似度計算之simhash短文字查詢》
2. 《Similarity estimation techniques from rounding algorithms》