
分類器是如何做檢測的?——【續】檢測中的LBP和HAAR特徵計算過程
前面介紹分類器檢測過程的示例中是以HOG特徵為例,那LBP和HAAR特徵在xml中是如何表達和測試的呢?
2.3 LBP與HAAR特徵
HAAR特徵的計算和表達方式與HOG很類似,在OpenCV的haartraining.exe中,feature儲存在每個weakclassifier中,而之後的traincascade.exe中則是以LBP、HOG、HAAR三種統一的方式——在stages後面用features節點來統一儲存——來儲存features的pool。
2.3.1 HAAR特徵
在haar特徵的訓練中(無論是老版本的haartraining還是現在的traincascade),都是有BASIC/CORE/ALL三種特徵組合待選的,預設情況為BASIC。三種情況下對應的特徵選取分別如下:
BASIC:
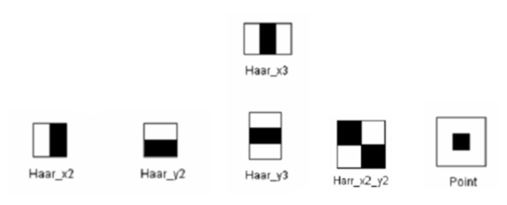
CORE中的增加項:
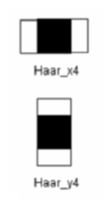
ALL中的增加項:

最後,HAAR特徵的表達形式是以不止一個rect來表示的。比如
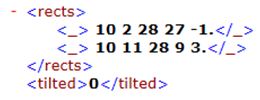
表達的是下圖中的特徵,tilted表達是否傾斜。

其他特徵都是以類似的形式表達,矩形後的-1和3是該矩形的weight,也就是3*rect2-rect1;它的統一形式是sumof( rect[i]*weight[i] )。當然這裡的rect同樣是在維護一系列指向積分圖中的指標。
2.3.2 LBP特徵
LBP特徵的計算與HAAR、HOG有很大不同,在判斷某個矩形的LBP特徵應當屬於左葉子還是右葉子的時候,HAAR和HOG只是用當前節點的threshold來判定就可以了;而LBP的節點結構是圖6所示:

圖6. LBP節點示意圖
節點中同樣是有0和-1來做左右節點程式碼,33是feature ID,也就是所在的矩形,而後面緊跟的8個數將會被儲存在vector<int> subset結構中,每個節點有8個這樣的數,因而最終subset的size = nodes.size()* 8。
就以上面的這個節點來描述下判定規則:
首先33對應的是下面的矩形

這個矩形將對應到積分圖中的16個int型指標,他們的對應關係如圖7所示,ID號33中給出的矩形位置就是圖中的A矩形。根據圖中的關係可以得到9個矩形中的16個指標,每個指標儲存的是積分圖中該點右上方矩形內的灰度和。這樣利用積分圖能夠快速計算出A~I共9個矩形內的灰度和,然後除E之外的其他矩形與E矩形內的結果作對比,大小將被標記為0或1,這樣8個矩形將得到一個8位數c。

圖7. Rect與LBP特徵計算位置的關係示意圖
接下來就是關鍵的如何根據c判斷當前矩形應當走向左節點還是右節點了。
sum += cascadeLeaves[subset[c>>5]& (1 << (c & 31)) ? leafOfs : leafOfs+1];
c中的8個位由高到低分別來自於矩形A-B-C-F-I-H-G-D,因而c>>5得到的是上面ABC三個位所代表的0~7範圍的一個數,根據此數將得到subset(也就是每個節點中都會儲存的8個數)中的一個值,這裡命名為X。1<<(c & 31)得到的是2^n,n是F-I-H-G-D共5個矩形的位,這裡將2^n這個值命名為Y,可見Y的範圍是1~2^31,(它想表達的就是在這5個矩形中的對比情況,因為他們是一一對應的)。最後X和Y做“按位與”運算如果是0就進入右節點,否則進入左節點。
這裡的判定規則應該是有更好的詮釋的,暫時還沒有找到相關資料,以上僅僅是在程式碼中解析的一些內容。
相比其他兩種,LBP的判定規則似乎有點複雜了。