
基於深度學習的影象壓縮
近年來,深度學習在計算機視覺領域已經佔據主導地位,不論是在影象識別還是超分辨重現上,深度學習已成為圖片研究的重要技術,但它們的能力並不僅限於這些任務;現在深度學習技術已進入圖片壓縮領域。下面就說說神經網路在影象壓縮領域的應用。
當前主要圖片壓縮演算法
說到影象壓縮演算法,目前市面上影響力比較大的圖片壓縮技術是WebP和BPG
WebP:谷歌在2010年推出的一款可以同時提供有失真壓縮和無失真壓縮的圖片檔案格式,其以VP8為編碼核心,在2011年11月開始可以支援無損和透明色功能。目前facebook、Ebay等網站都已採用此圖片格式。
BPG:知名程式設計師、ffmpeg和QEMU等專案作者Fabrice Bellard推出的影象格式,它以HEVC為編碼核心,在相同體積下,BPG檔案大小隻有JPEG的一半。另外BPG還支援8位和16位通道等等。儘管BPG有很好的壓縮效果,但是HEVC的專利費很高,所以目前的市場使用比較少。
就壓縮效果來說,BPG更優於WebP,但是BPG採用的HEVC核心所帶來的專利費,導致其無法在市場進行大範圍使用。在這種情況下,運用深度學習來設計圖片壓縮演算法就應運而生。
早在 2016 年的時候,谷歌的研究人員就提出了一種基於神經網路的全解析度有損影象壓縮法《Full Resolution Image Compression with Recurrent Neural Networks》(利用迴圈神經網路進行全解析度影象壓縮)。
此後也陸續出現了不少這方面的研究,比如去年的IEEE大會上,來自哈爾濱工業大學的一組研究人員聯合提交了一篇論文《An End-to-End Compression Framework Based on Convolutional Neural Networks
他們在這篇論文中就提出了一種新的基於卷積神經網路的壓縮框架,能夠實現影象的高質量壓縮。這個框架由兩部分組成:一個 ComCNN 用於學習輸入影象中最優的緊湊表示,然後編碼影象,一個 RecCNN 用於重構出高質量的解碼影象。下面集智就說說這篇論文中利用深度學習技術進行影象壓縮的方法。
什麼是影象壓縮?
影象壓縮就是轉換影象的過程,讓影象佔據更少的空間。很多影象如果直接儲存的話或佔據很大的空間,所以出現了不少編解碼器,比如 JPEG 和 PNG,目的就是減少原始影象的大小。
有失真壓縮 VS 無失真壓縮
目前有兩種壓縮形式:有失真壓縮和無失真壓縮。從名字上就能看出來,無失真壓縮能夠恢復原始影象的全部資料,而有失真壓縮則在影象轉換過程中會丟失一些資料。
比如,JPG 就是一種有失真壓縮演算法,而 PNG 就是一種無失真壓縮演算法。

圖:無失真壓縮和有失真壓縮對比
注意右側影象上有很多塊狀的類似馬賽克的透明斑點,這就表示影象的資訊丟失了。同一顏色的相鄰畫素會被壓縮為一個區域以節省空間,但是也會導致實際畫素丟失資訊。當然了,像 JPEG,PNG 等這樣的演算法更復雜些,但上面這個例子應該能很直觀地展示出了有失真壓縮。無失真壓縮很好,不過最終會在硬碟上佔據大量空間。
還有一些更好的圖片壓縮方法,不會損失太多的影象資訊,但是壓縮速度很慢。不少還是使用迭代方法,意味著無法在多個 CPU 和 GPU 上並行執行。因而在日常生活中用起來不太實際。
引入卷積神經網路
如果有什麼東西能夠進行計算,還能近似實現,那就使用神經網路吧。在哈工大的這篇論文中,作者就使用了非常標準的卷積神經網路用來優化影象壓縮。他們的方法不僅能很好地的完成影象壓縮,而且還能應用平行計算,大幅提高了壓縮速度。
這種方法背後的原理就是卷積神經網路非常善於從影象中提取空間資訊,然後將資訊表示為更復雜的形式(比如,只儲存影象的“重要”位元)。作者想借助 CNN 的這種能力來更好地表示影象。
模型架構
作者提出了一種雙元網路架構,第一個網路會提取影象的資訊並生成緊湊的表示(ComCNN),然後用一個標準的編解碼器(比如 JPEG)處理該網路的輸出結果。再通過編解碼器處理後,影象會被傳遞到第二個神經網路,它會“修復”來自編解碼器的影象,試圖恢復原始影象的資訊,這個網路被作者稱為重構 CNN(RecCNN)。這兩個網路都經過迭代訓練,和 GAN 類似。

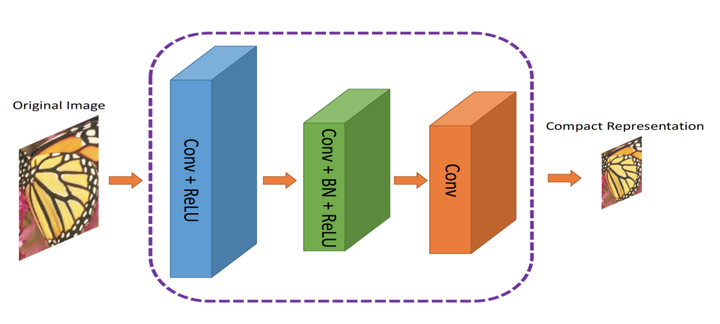
圖:ComCNN模型架構。影象的緊湊表示通過它傳入編解碼器。
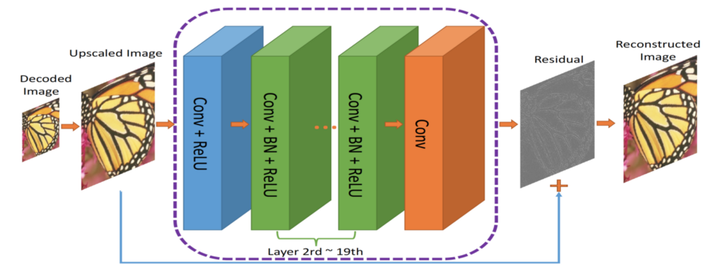

圖:壓縮影象的端到端框架。Co(.) 表示影象壓縮演算法;作者使用了JPEG,JPEG2000和BPG
編解碼器的輸出結果經過解析度提高後,傳輸到 RecCNN 中。RecCNN 會輸出一張最大限度與原始影象一致的照片。
什麼是殘差?
殘差可以看作對編解碼器解碼出的影象進行“優化”的後期處理步驟。神經網路經過學習後,對影象有了豐富的認知,能夠決定“修復”哪些東西。這裡的理念基於深度殘差學習。
損失函式
由於有兩個神經網路,所以應用了兩個損失函式。第一個是用於 ComCNN 網路的損失函式,定義為:
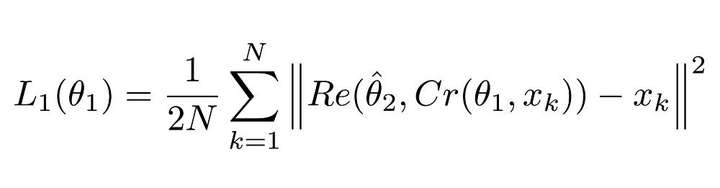

圖:ComCNN的損失函式
解釋
該等式看著很複雜,但實際上它就是個均方誤差(MSE)。這裡的||²表示它們封裝進的向量的正則項。
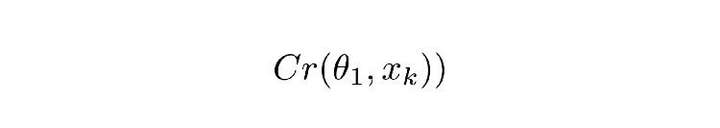

圖:公式1.1
Cr 表示 ComCNN 的輸出結果。θ 表示 ComCNN 的可訓練引數,Xk 表示輸入影象。
Re() 表示 RecCNN,該公式只將公式 1.1 的值傳入 RecCNN 中。估量符號 θ 表示 RecCNN 的可訓練引數。

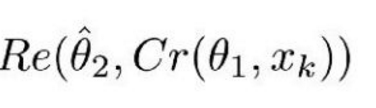
直觀定義
公式 1.0 會讓 ComCNN 修改其權重,從而使影象經過 RecCNN 重建之後,能儘可能地接近原始輸入影象。
第二個是用於 RecCNN 的損失函式,定義如下:
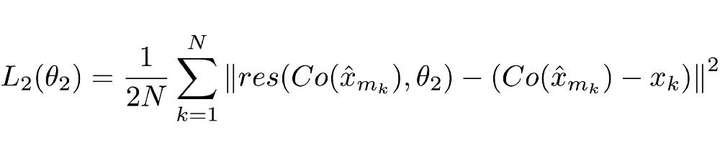
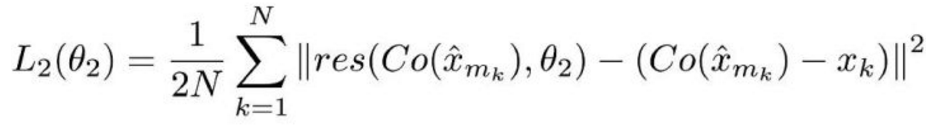
解釋
同樣,這個損失函式看著也很複雜,但實際上仍是個標準的神經網路損失函式——MSE。
Co() 表示編解碼器的輸出結果,估量符號 x 表示 ComCNN 的輸出,θ2 表示 RecCNN 的可訓練引數。Res() 表示神經網路學習的殘差,只是 RecCNN 的輸出結果。值得一提的是,RecCNN 的訓練基於 Co() 和輸入影象,並非直接基於輸入影象。
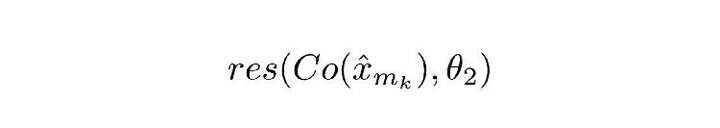
直觀定義
公式 2.0 會讓 RecCNN 修改其權重,讓它的輸出最大限度接近原始影象。
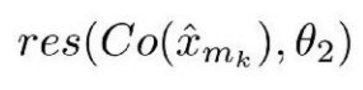
訓練機制
模型以迭代的方式進行訓練,和 GAN 模型的訓練方式相同。其中一個模型的權重固定不變,只更新第二個模型的權重;然後讓第二個模型的權重保持不變,只更新第一個模型的權重。
基準
論文作者將他們的方法和現存方法進行了比較,包括普通的編解碼在內。最終證明他們的方法效果要優於其它方法,在保持較高的壓縮速度的同時,影象的質量也得到了保證。

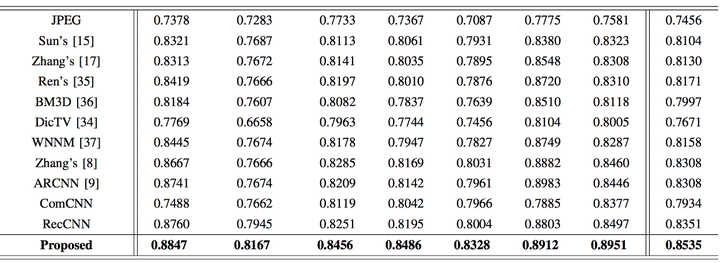
圖:SSIM(結構相似度指數)比較。值越高表示和原圖越相似。加粗值表示論文方法的結果。
結語
本篇論文向我們展示了深度學習技術在影象壓縮領域的應用,不僅壓縮效果比肩當前最先進的方法,而且具有更快的壓縮速度。我們從中也可以看到深度神經網路在諸如影象分類和影象處理等常見任務以外的領域,同樣大有可為。
除了本文講解的這篇論文外,我們也收集了最近出現的一些相關研究成果,比如:
- 《DeepN-JPEG: A Deep Neural Network Favorable JPEG-based Image Compression Framework》(DeepN-JPEG:基於JPEG的深度神經網路影象壓縮框架)
論文地址:
https://arxiv.org/pdf/1803.05788.pdf
- 《Deep Image Compression via End-to-End Learning》(通過端到端學習進行深度影象壓縮)
論文地址:
https://arxiv.org/pdf/1806.01496.pdf
- 《Semantic Perceptual Image Compression using Deep Convolution Networks》(利用深度卷積神經網路進行語義感知影象壓縮)
論文地址:
https://arxiv.org/abs/1612.08712
該論文的程式碼實現地址:
https://github.com/iamaaditya/image-compression-cnn
- 《Real-Time Adaptive Image Compression》(實時自適應影象壓縮)
- https://arxiv.org/pdf/1705.05823.pdf