
一隻有恆心的小菜鳥
級聯分類器
cascade detector detector AdaBoost讀"P. Viola, M. Jones. Rapid Object Detection using a Boosted Cascade of Simple Features[J].CVPR, 2001"筆記
論文的主要貢獻點
提出積分圖(Integral image)的概念。在該論文中作者使用的是Haar-like特徵,然後使用積分圖能夠非常迅速的計算不同尺度上的Haar-like特徵。
使用AdaBoost作為特徵選擇的方法選擇少量的特徵在使用AdaBoost構造分類器。
以級聯的方式,從簡單到複雜逐步串聯分類器,形成級聯分類器。
積分圖
1.首先介紹下 haar-like feature
使用提取特徵而不是直接使用畫素值有兩方面原因:
The most common reason is that features can act to encode ad-hoc domain knowledge that is difficult to learning using a finite quantity of training data.
For this system there is also a second critical motivation for features: the feature based system operates much faster than a pixel-based system.
Haar-like feature是由等面積的正負矩形區域生成的運算元,該論文給出了3種Haar-like feature 運算元,如下圖所示:

Haarlike.JPG
其中A,B分別表示的是水平方向和豎直方向上的梯度,C包含了3個矩形區域,D計算的是對角方向上的梯度。對於不同尺度的運算元可以得到不同尺度下的特徵。該論文中在(24,24)的影象區域內提取了超過18萬個特徵,雖然沒說運算元怎麼構造的。
後來的學者設計了更多更復雜的Haar-like featurs:

haarlikefeature.JPG
haar-like 特徵的haar來源於haar基函式,如下圖:

HaarFunction.jpg
haar特徵就類似二維情形下的haar基函式。
積分圖
積分圖可以藉助於二維積分很容易理解,我們的被積函式是影象的灰度值,定義域是影象區域,那麼可以以積分的方式計算從原點到任意點形成的矩形區域內的畫素和。
例如區間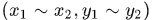 的概率值可以直接使用分佈函式得到:
的概率值可以直接使用分佈函式得到: , Haar-like特徵運算元的區域也是矩形區域,所以在計算haar-like特徵時可以使用積分圖快速的計算。
, Haar-like特徵運算元的區域也是矩形區域,所以在計算haar-like特徵時可以使用積分圖快速的計算。
對於論文中提到的三種特徵運算元,我們假設從左上角座標開始座標索引值依次增大,那麼對於A類特徵值可如下計算:
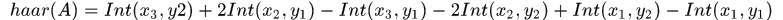
其中 是積分表
是積分表
two-rectangle 特徵需要6次查表,如上式, three-rectangle 特徵需要8次查表, four-rectangle特徵需要9次查表。
基於AdaBoost的特徵選擇
實際應用中,對分類產生較大影響的往往只有少數的特徵,比如傳統的主成分分析方法(PCA)就是用來尋找這些對分類影響較大的特徵,而論文中提取了180000多的特徵,遠遠過完備(180000>>24*24),所以選擇主要的特徵是必要的。文中使用adaboost中的弱分類器實現特徵的選擇,在設計弱分類器時,僅考慮一維特徵,選擇誤差最小的那個分類器作為該輪迭代產生的弱分類器,而對應的維度就是該輪迭代選擇出的特徵。其過程如下表:

adaboostFS.JPG
級聯分類器
文中給出了一種比傳統的AdaBoost分類器更快的分類方法,即級聯分類器。該分類器由若干個簡單的AdaBoost分類器串接得來。假設AdaBoost分類器要實現99%的正確率,1%的誤檢率需要200維特徵,而實現具有99.9%正確率和50%的誤檢率的AdaBoost分類器僅需要10維特徵,那麼通過級聯,假設10級級聯,最終得到的正確率和誤檢率分別為:
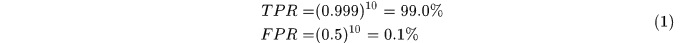
可以看到通過級聯adaboost分類器們能夠使用較少的特徵和較簡單的分類器更快更好的實現分類。
另外在檢測的過程中,因為TPR較高,所以一旦檢測到某區域不是目標就可以直接停止後續檢測。由於在人臉檢測應用中非人臉區域佔大部分,這樣大部分檢測視窗都能夠很快停止,是分類速度得到很大的提高。
級聯分類器的訓練過程
In pratice a very simple framework is used to produce an effective classifier which is highly efficient. Each stage in the cascade reduces the false positive rate and decreases the detection rate. A target is selected for the minimum reduction in false positives and the maximum decrease in detection. Each stage is trained by adding features until the target detection and false positives rate are met ( these rates are determined by testing the detector on a validation set). Stages are added until the overall target for false for false positive and detection rate is met.
預先選定每一層的最大可接受誤檢率fpr(maximum acceptable rate of fpr) 和每一層最小可接受的檢測率(minimum acceptable detection rate)
設定系統整體的可接受誤檢率
初始化. FPR=1, TPR = 1(檢測率)
迴圈. 如果當前
,新增一層adaboost分類器,如果該分類器訓練過程中沒有達到該層最大誤檢率就繼續新增新特徵,新增新特徵時降低閾值,使分類器的檢測率大於給定值,然後更新
每一級分類器使用的訓練集是上一級分類器判定正確的樣本,而其中的錯分的被當作負樣本。這使得下一級的分類器更關注那些更難區分的樣本。


cascade detector 示意圖

cascade.JPG
參考文獻