
深入理解HashMap及底層實現
概述:HashMap是我們常用的一種集合類,資料以鍵值對的形式儲存。我們可以在HashMap中儲存指定的key,value鍵值對;也可以根據key值從HashMap中取出相應的value值;也可以通過keySet方法返回key檢視進行迭代。以上是基於HashMap的常見應用,但是光會使用是遠遠不夠的,接下來將我們深入剖析HashMap的實現原理並手寫實現一個簡單的HashMap。
HashMap的儲存結構
如圖:
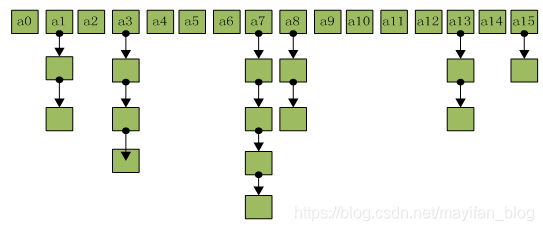
通過圖例我們可以發現,HashMap其實是由陣列和連結串列組合而成的,綜合了二者的優點,可以快速定位並且快速修改資料。陣列的特點:陣列是一種連續的儲存結構,查詢元素快,時間複雜度為O(1),但增刪元素慢,需要移動整個陣列,時間複雜度為O(n);連結串列的特點:連結串列是由一個個節點組成,節點之間通過引用聯絡起來,連結串列查詢元素需要從根節點遍歷,逐個查詢,時間複雜度為O(n),但連結串列增刪資料十分便捷,只要修改節點之間的引用即可實現。HashMap綜合了兩者的優點,我們都知道HashMap是通過key來定位的,接下來介紹一下中間環節具體是如何實現的:
1、獲取hashCode()值
public int hashCode() { int h = hash; if (h == 0 && value.length > 0) { char val[] = value; for (int i = 0; i < value.length; i++) { h = 31 * h + val[i]; } hash = h; } return h; }
hashCode()方法是可以改寫的,對於不同資料型別我們可以採用不同的hashCode()方法,我們獲得的hashCode值是一串數字,不同key值對應的hashCode是不同的,我們一般無法通過一個hashCode值獲取到兩個相同的key值。
2、通過雜湊函式獲取在陣列中儲存的下標位置:我們剛剛只是獲取了一串資料來表示key的身份,但不知道它對應與HashMap的陣列部分的儲存位置,接下來我們還需要一步轉化來獲取一個範圍在陣列長度內的數字,那就是雜湊函式,雜湊函式也不唯一,有很多實現形式,效能也各有不同,但最終目的都是為了獲得一個在長度範圍內的值作為下標。這裡給出一個雜湊函式:
private int hash(K k) { int hashCode=k.hashCode();//獲取HashCode hashCode^=(hashCode>>>12)^(hashCode>>>20); return hashCode^(hashCode>>>7)^(hashCode>>>4); }
其中“^”表示按位異或,“>>>”表示無符號右移。
3、找到具體的節點位置並插入:陣列的每個位置都可能引出一串連結串列結構,這是為了防止發生雜湊碰撞設計的,如果在這個位置原本就為空,那麼直接建立一個新的節點(HashMap的鍵值對儲存在節點中,節點內有key,value,下一個節點的引用等資料 )並存入,如果在下標處已經存在一個節點,當我們再次通過索引準備把一個新的節點存入時,就會發生雜湊碰撞。對於雜湊碰撞我們有如下幾種處理方式:
- 若和之前儲存在此處的節點的key值相同,則更新value即可。
- 若和之前儲存在此處的節點的key值不同,只是因為hashCode相同而都安排在了這個地方,那麼我們會通過新的鍵值對生成新的節點,把它放在原先節點的前面。之後在查詢的時候,我們需要遍歷這兩個節點才能找到對應的key值,獲取value。
- 擴容:當新增的資料較多,滿足陣列擴容條件時(連結串列擴容條件:當節點總數達到設定的節點數閾值後初次發生發生雜湊碰撞,陣列就需要擴容),完美就會建立一個長度為原來兩倍的陣列,把原節點資料遷移到新的陣列,再插入新節點,即可解決雜湊碰撞問題,一般陣列預設的閾值是0.75,陣列的長度一般預設16。
小結:通過以上介紹,我們對於HashMap的儲存形式和資料結構已經有了基本的瞭解,概括一下就是:HashMap通過陣列的結構可以迅速找到儲存的位置,通過連結串列實現了相同hashCode的資料的儲存以及便捷的增刪操作,另外通過擴容機制保證了儲存的高效和陣列長度的自適應。
手寫實現一個簡單的HashMap
接下來我們手寫實現一個簡單的HashMap,可以實現鍵值對儲存,以及通過key值獲取value。
1、Map及節點介面(節點用內部介面實現):
public interface MyMap<K,V>{
public V put(K t,V v); //存方法
public V get(K T); //取方法
interface Entry<K,V> //Entry為Map中的元素,定義一個內部介面
{
public K getKey(); //獲取Key值
public V getValue(); //獲取Value值
}
}
2、MyHashMap類(支援泛型):
public class MyHashMap<K,V> implements MyMap<K, V>
{
private static final int LENGTH=16; //預設定義陣列的初始長度
private static final float LOAD = 0.75f; //預設定義閾值比例
private int length; //主動定義陣列的長度
private float load; //主動定義閾值比例
private int entryUseSize; //記錄map中當前Entry數量
private Entry<K, V>[] table=null;//申明一個數組
/**
* 預設建立HashMap時,指定陣列長度為預設值
*/
public MyHashMap(){
this(LENGTH,LOAD); //呼叫構造方法
}
/**
* 構造方法,在執行時生成對應長度的陣列
* @param length
* @param load
*/
public MyHashMap(int length,float load) {
// TODO Auto-generated constructor stub
this.length=length;
this.load = load;
table = new Entry[this.length];
}
/**
* 修改陣列長度,建立一個新的陣列
* @param length
*/
public void resize(int length)
{
Entry<K,V>[] newTable = new Entry[length]; //建立新的陣列
this.length=length;
this.entryUseSize=0;
rehash(newTable); //內容遷移
}
/**
* 老陣列到新陣列的資料遷移
* @param newTable
*/
public void rehash(Entry<K, V>[] newTable) {
ArrayList<Entry<K,V>> array = new ArrayList<>();
for(Entry<K,V> entry:table) //遍歷陣列table,新增到ArrayList,即取資料,先取出第一個Entry,再在while迴圈中取出後續的資料
{
if(entry!=null)
{
do
{
array.add(entry); //添加當前節點
entry=entry.next;//獲得連結串列中下一個節點的引用
}
while(entry!=null);//若有後續節點,則繼續新增到ArrayList
}
}
table=newTable; //覆蓋舊引用
for(Entry<K,V> entry : array) //遍歷ArrayList開始存放到新陣列
{
put(entry.getKey(),entry.getValue()); //存值
}
}
/**
*
* 節點類,存放資料和指標
* @author mayifan
*
* @param <K>
* @param <V>
*/
class Entry<K,V> implements MyMap.Entry<K, V>
{
private K key; //存放key值
private V value; //存放value值
private Entry<K,V> next; //指向下一個相同hash對應的元素,也是它前一個新增的元素
/**
* 構造方法:定義一個空的節點
*/
public void Entry()
{
}
/**
* 構造方法
* @param key
* @param value
* @param entry
*/
public Entry (K key,V value,Entry<K,V> next){
this.key=key;
this.value=value;
this.next = next;
}
/**
* 獲取節點的key值
*/
public K getKey() {
// TODO Auto-generated method stub
return key;
}
/**
* 獲取節點的value值
*/
public V getValue() {
// TODO Auto-generated method stub
return value;
}
}
/**
* 存放鍵值對的方法
* 新增鍵值對的時候要考慮是否需要擴容
* 擴容條件:當節點總數超過限額後第一次發生hash碰撞,會導致擴容,容量增加一倍,建一個新的陣列,原陣列的資料遷移到新的陣列上,再加上新的節點,刪除原陣列
*/
public V put(K k, V v) {
V oldValue=null;
if(entryUseSize>=length*load) //滿足條件,則擴容
{
resize(2*length);
}
int i = hash(k)&(length-1); //得到Hash值,計算在陣列中的位置。length是2的冪次,(length-1)可以得到全為1的二進位制數。
if(table[i]==null) //該位置為空
{
table[i]=new Entry<K,V>(k,v,null);
entryUseSize++;
}
else //不為空,則逐個比對判斷有沒有重複,如果重複返回源節點
{
Entry<K,V> entry = table[i]; //獲取第一個節點
do
{
if(entry.getKey().equals(k))//若找到相同的key,則更新value
{
oldValue=entry.getValue(); ///獲取節點的原value
entry.value=v;
return oldValue;
}
entry=entry.next; //下一個節點
}
while(entry!=null); //下一個節點不為空,則繼續判斷
Entry<K, V> entry1 = new Entry<K,V>(k, v,table[i]); //新建一個節點指向原節點
table[i]=entry1;
entryUseSize++;
}
return oldValue;
}
/**
* 獲取指定K值的資料
*/
public V get(K k) {
V value = null;
int i = hash(k)&(length-1);
if(table[i]!=null) //table不為null
{
Entry<K, V> entry = table[i]; //獲取entry節點
do
{
if(entry.getKey().equals(k)||entry.getKey()==k)
{
return entry.value;
}
entry=entry.next;
}
while(entry!=null);
}
return value;
}
/**
* 獲取指定key值的hash值(一種雜湊函式)
* @param t
* @return
*/
private int hash(K k) {
int hashCode=k.hashCode();//獲取HashCode
hashCode^=(hashCode>>>12)^(hashCode>>>20);
return hashCode^(hashCode>>>7)^(hashCode>>>4);
}
}
3、測試類(有兩種鍵值對):
public class Test{
public static void main(String[] args)
{
System.out.println("存取int和String鍵值對:");
MyHashMap<Integer, String> mp = new MyHashMap();
mp.put(123, "asdasdad");
mp.put(346,"ddddd");
mp.put(3333, "sssss");
mp.put(4444, "xxxxx");
mp.put(789, "aaaaa");
System.out.println(mp.get(123));
System.out.println(mp.get(346));
System.out.println(mp.get(3333));
System.out.println(mp.get(4444));
System.out.println(mp.get(789));
System.out.println("存取String和String鍵值對:");
MyHashMap<String, String> mp1 = new MyHashMap();
mp1.put("ss", "cvcvv");
mp1.put("aaaa","uu");
mp1.put("dr", "yyy");
mp1.put("qwe", "rrrrr");
mp1.put("vv", "dsfsf");
System.out.println(mp1.get("ss"));
System.out.println(mp1.get("aaaa"));
System.out.println(mp1.get("dr"));
System.out.println(mp1.get("qwe"));
System.out.println(mp1.get("vv"));
}
}
4、輸出結果測試:

以上測試結果表明HashMap的基本概念得到了實現。
關於HashMap一些問題的分析
1、一個key多個value如何實現?
key值是唯一的,但由於鍵值對是以節點的形式儲存,那麼在key值唯一的前提下,可以在節點儲存value1,value2等資料。我們可以寫獲取節點的方法,然後讀取不同value,或者重寫get方法返回陣列,都可以實現一個key獲取多個value。
2、HashMap是否執行緒安全?
答案是否定的,HashTable是執行緒安全的,而HashMap不是,我們在HashMap的底層原始碼中找不到synchronize關鍵字,如果在多執行緒併發訪問的時候是有可能出現錯誤的。那麼如果避免呢?我們需要在程式層面人為地實現同步,確保同一時間只有一個執行緒訪問HashMap。雖然HashMap不是執行緒安全的,但它也有優點,比如效率高,速度快等。
3、為什麼陣列的長度初值為2的指數次?
在進行按位與的時候可以顯現出它的優點,(長度-1)轉化為二進位制可以得到的二進位制各位都是1,不會造成儲存空間的浪費。
4、為什麼計算HashCode時使用31這個奇質數?
如果數值太小會使得最後得到的範圍很小,容易發生雜湊碰撞;如果數值超過100會使得到的數值超出int的範圍;31+1得到的32是2的指數次,可以方便JVM進行移位運算,如:31 * i = (i << 5) - i