
哈夫曼樹的搭建與哈夫曼編碼
什麼是哈夫曼樹
在介紹哈夫曼樹前,我們先介紹二叉樹的基本概念,以便大家更好地理解哈夫曼樹:
- 路徑:兩個節點之間分支的連線即兩個節點之間的路徑。
- 路徑長:兩個節點之間路徑所包含分支的和。
- 深度:根節點的深度為0,其子節點的深度為1,往下逐一遞推。
- 子節點數:和普通的樹不同,二叉樹從根節點出發,每個節點最多隻能有兩個子節點。
- 滿二叉樹:除了葉子結點,每個節點都有兩個子節點。
哈夫曼樹是一種最優的二叉樹,它的帶權路徑最短。那麼怎麼算一個二叉樹的權值呢?我們從根節點開始遞推,根節點的權值為0,隨著深度的遞增,權值也遞增,同一深度的節點權值是相同的,每個節點都有它的資料值,每個節點的資料值乘權值累加即可得到樹的權值,哈夫曼樹是帶權路徑最短的樹。如圖:
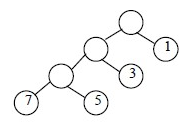
權值1=73+53+32+11=43
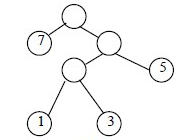
權值2=13+33+52+71=29
比較這兩棵樹的權值我們可以發現:要使帶權路徑最短,較大的數應該靠上放,較小的靠下放。第二張圖才是帶權路徑最短的二叉樹,即最優二叉樹(哈夫曼樹)。
如何生成一棵哈夫曼樹
- 把需要用來構建哈夫曼樹的陣列進行排序。
- 取最小的兩個數作為葉子結點,生成雙親節點,雙親節點的值為二者的值之和。
- 從陣列中刪除這兩個節點,新增生成的雙親節點入陣列並重新排序。
- 重複以上操作直至陣列只剩下一個新生成的節點,它就是哈夫曼樹的根節點。
哈夫曼編碼
哈夫曼樹是最優的二叉樹,帶權路徑最短,這意味著哈夫曼樹上數值較大的節點更加靠近根節點。訊號的傳輸是以位元組為單位的,ASCII碼錶示的255個字元分別可以用一個位元組來表示,一個字元的傳輸需要用到一個位元組(8bit),如果在一段報文中我們只用到了一部分字元,並且不同字元出現的頻率還是不同的,我們能否用一些特殊的方法來對其加工從而壓縮需要傳輸的總位元組數呢?我們試著去縮短那些出現頻率高的字元的編碼表示,聯絡我們學的哈夫曼樹,我們做這樣的假設:從根節點出發,向左記“0”,向右記“1”,在哈夫曼樹中,根節點是不帶資料的,它的左子節點可以用“0”來編碼,左子節點的左子節點用“00”表示,左子節點的右子節點用“01”表示,根節點的右子節點用“1”表示…以此類推,我們可以為樹上所有的節點分配一個編碼,編碼是不重複的,且靠近根節點的那些出現頻次較高的節點對應的編碼較短。這樣我們每個字元對應的編碼表示都會小於等於8位,這極大壓縮了需要傳輸的資料大小。
哈夫曼樹的實現
1、節點類:
這是一種支援泛型的節點類,我們定義了一些方法來操作節點的資料。
public class Node<T> implements Comparable<Node<T>>{ private T data; private int weight; private Node<T> left; private Node<T> right; public Node(T data,int weight) { this.data=data; this.weight=weight; } /** * 獲取節點資料 */ public String toString() { return "data:"+data+" "+"weight:"+weight; } /** * 節點權值比較方法 * @param o * @return */ public int compareTo(Node<T> o) { if(this.weight>o.weight) return 1; else if(this.weight<o.weight) return -1; return 0; } public void setData(T data) { this.data=data; } public void setWeight(int weight) { this.weight=weight; } public T getData() { return data; } public int getWeight() { return weight; } public void setLeft(Node<T> node) { this.left=node; } public void setRight(Node<T> node) { this.right=node; } public Node<T> getLeft() { return this.left; } public Node<T> getRight() { return this.right; } }
2、建樹:
步驟:
1、輸入字串。
2、統計各字元出現的次數,生成ASCII碼陣列。
3、用陣列生成節點並存放在連結串列中。
4、根據字元出現頻率對連結串列中的節點進行排序。
5、根據連結串列中的有序節點生成哈夫曼樹。
6、根據哈夫曼樹獲取輸入字元對應的哈夫曼編碼值,存入HashMap。
public class Create {
public static void main(String[] args)
{
Create ct = new Create();
Scanner sc = new Scanner(System.in);
System.out.println("請輸入一個字串:");
String str = sc.nextLine();
int[] a = ct.getArrays(str);
System.out.println(Arrays.toString(a));
LinkedList<Node<String>> list = ct.createNodeList(a);//把陣列的元素轉為節點並存入連結串列
for(int i=0;i<list.size();i++)
{
System.out.println(list.get(i).toString());
}
Node<String> root = ct.CreateHFMTree(list); //建樹
System.out.println("根節點權重:"+root.getWeight());
System.out.println("列印整棵樹、、、、");
ct.inOrder(root); //列印整棵樹
System.out.println("獲取葉子結點哈夫曼編碼");
HashMap<String,String> map = ct.getAllCode(root);
}
/**
* 通過字串獲取陣列的方法
* @param str
*/
public int[] getArrays(String str)
{
int[] arrays = new int[256];
for(int i=0;i<str.length();i++)
{
int Ascii = str.charAt(i);
arrays[Ascii]++;
}
return arrays;
}
/**
* 把獲得的陣列轉化為節點並存在連結串列中
* @param arrays
* @return
*/
public LinkedList<Node<String>> createNodeList(int[] arrays)
{
LinkedList<Node<String>> list = new LinkedList<>();
for(int i=0;i<arrays.length;i++)
{
if(arrays[i]!=0)
{
String ch = (char)i+"";
Node<String> node = new Node<String>(ch,arrays[i]); //構建節點並傳入字元和權值
list.add(node); //新增節點
}
}
return list;
}
/**
* 對連結串列中的元素排序
* @param list
* @return
*/
public void sortList(LinkedList<Node<String>> list)
{
for(int i=list.size();i>1;i--)
{
for(int j=0; j<i-1;j++)
{
Node<String> node1 = list.get(j);
Node<String> node2 = list.get(j+1);
if(node1.getWeight()>node2.getWeight())
{
int temp ;
temp = node2.getWeight();
node2.setWeight(node1.getWeight());
node1.setWeight(temp);
String tempChar;
tempChar = node2.getData();
node2.setData(node1.getData());
node1.setData(tempChar);
Node<String> tempNode = new Node<String>(null, 0);
tempNode.setLeft(node2.getLeft());
tempNode.setRight(node2.getRight());
node2.setLeft(node1.getLeft());
node2.setRight(node1.getRight());
node1.setLeft(tempNode.getLeft());
node1.setRight(tempNode.getRight());
}
}
}
}
/**
* 建樹的方法
* @param list
*/
public Node<String> CreateHFMTree(LinkedList<Node<String>> list)
{
while(list.size()>1)
{
sortList(list); //排序節點連結串列
Node<String> nodeLeft = list.removeFirst();
Node<String> nodeRight = list.removeFirst();
Node<String> nodeParent = new Node<String>( null ,nodeLeft.getWeight()+nodeRight.getWeight());
nodeParent.setLeft(nodeLeft);
nodeParent.setRight(nodeRight);
list.addFirst(nodeParent);
}
return list.get(0);//返回根節點
}
public HashMap<String, String> getAllCode(Node<String> root)
{
HashMap<String, String> map = new HashMap<>();
inOrderGetCode("", map, root);
return map;
}
/**
* 查詢指定字元的哈弗曼編碼(中序遍歷)
* @param code
* @param st
* @param root
* @return
*/
public void inOrderGetCode(String code ,HashMap<String, String> map,Node<String> root)
{
if(root!=null)
{
inOrderGetCode(code+"0",map,root.getLeft());
if(root.getLeft()==null&&root.getRight()==null)//儲存葉子結點的哈夫曼編碼
{
System.out.println(root.getData());
System.out.println(code);
map.put(root.getData(), code);
}
inOrderGetCode(code+"1",map,root.getRight());
}
}
/**
* 中序遍歷輸出整棵樹
* @param root
* @return
*/
public void inOrder(Node<String> root)
{
if(root!=null)
{
inOrder(root.getLeft());
if(root.getData()!=null)
System.out.println(root.getData());
inOrder(root.getRight());
}
}
}
3、測試:
輸入一字串,選取幾個key值觀察其對應的編碼值是否和理論值相同:
1、輸入字串,獲得了一些節點資料。
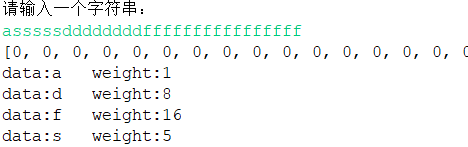
2、排序整理。

3、建樹並返回根節點,列印權值。
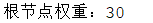
4、列印整棵樹,觀察中序遍歷是否正確。

5、在往HashMap存值前列印字元和編碼的對應關係。
