
【姿態估計】PoseMachine: 通過推理機進行關節姿態估計 Articulated Pose Estimation via Inference Machines
原文地址:http://www.cs.cmu.edu/~vramakri/poseMachines.html
摘要 用於關節人體姿態估計的最先進方法基於部件的圖模型。這些模型通常僅限於樹形結構表示和簡單的引數,以便實現易處理的推理。但是,這些簡單的依賴關係無法捕獲身體部位之間的所有互動。雖然可以定義具有更復雜互動的模型,但是通過難以處理或近似推斷來學習這些模型的引數仍然具有挑戰性。本文不是對學習的圖模型進行推理,而是建立在推理機器框架上,並提出了一種用於關節人體姿態估計的方法。作者的方法融合了不同尺度部分的多個部分和資訊之間的豐富空間的相互作用。此外,作者的方法的模組化框架使得無需專門的優化求解器即可輕鬆實現並有效推理。作者在兩個具有較大姿態變化的具有挑戰性的資料集上分析了作者的方法,並且在這些基準測試中表現優於最新技術水平。
1. 引言
從影象估計人體的關節姿態有兩個主要的複雜思路。第一個起源於下面的鉸接骨架的大量自由度(接近20個),這導致要搜尋高維配置空間。第二個是由於影象中人物外觀的巨大差異。每個部件的外觀可能因配置,成像條件和人與人而異。
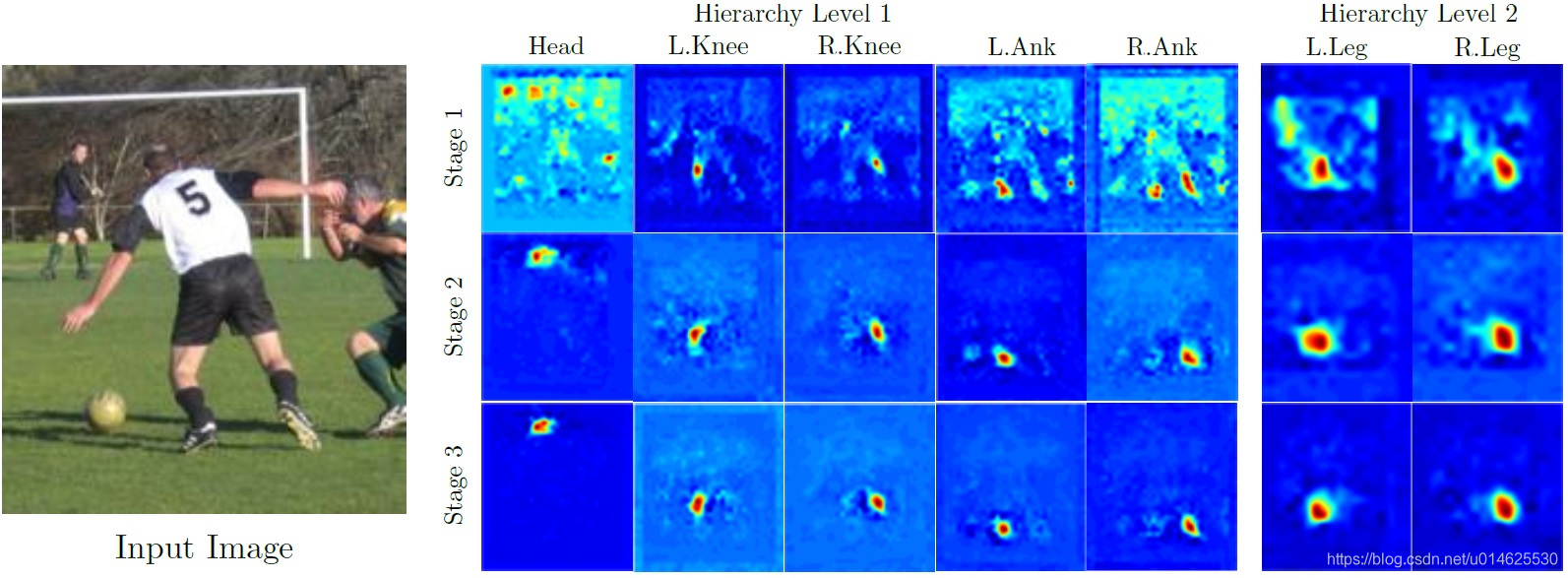
圖1 減少重複計數錯誤。通過更豐富的互動建模,可以防止樹模型中出現的重複計算錯誤。在左邊,作者的方法展示了每個階段人的左腳的置信度。這種置信度很快就會達到一個尖峰。在右邊,樹狀結構模型[5]具有多個峰值的左腳最大邊緣,導致兩條腿被估計在影象中的同一區域。
為了應對這種複雜性,目前的方法[1,2,3,4,5,6]採用圖模型來捕獲零件位置之間的相關性和依賴性。然而,除了最簡單的模型之外,圖模型中的推理在所有模型中都是困難和不精確的,例如樹形結構模型或星形結構模型。這些簡化模型無法捕獲每個部件的位置之間的重要依賴性並導致特徵錯誤。一個這樣的錯誤是重複計數(見圖1)——這在影象的相同區域用於解釋多個部分時發生。出現此錯誤是因為身體部位的對稱外觀(例如,左臂和右臂通常具有相似的外觀),並且身體的不同部分相互遮擋。使用圖模型對此外觀對稱性和自遮擋進行建模需要額外的邊緣並在圖中引入迴圈。這種非樹結構化圖模型通常需要使用近似推理(例如,迴圈置信傳播),這使得引數學習變得困難[7]。
圖模型的第二個限制是,在指定互動型別時,需要仔細考慮定義潛在功能。這種選擇通常由引數形式(如簡單的二次模型)主導,以便實現易處理的推理[1]。最後,為了在實踐中進一步實現有效的推理,許多方法也被限制使用簡單的分類器,例如用於零件檢測的線性模型的混合[5]。這些是由推理的可控性而不是資料的複雜性引導的選擇。這種權衡導致限制性模型不能解決問題固有的複雜性。
作者的方法通過直接訓練推理過程,避免了這種複雜性與易處理性的權衡。作者提出了一種用於鉸接式人體姿態估計的方法,該方法構建了最初用於場景解析的分層推理機[8,9]。從概念上講,所提出的方法,作者稱之為姿態機,是一種順序預測演算法,它模擬訊息傳遞的機制來預測每個變數(部分)的置信度,迭代地改進每個階段的估計。推理機架構特別適合於解決姿態估計中的主要挑戰。首先,它在多個變數之間包含更豐富的互動,減少了重複計算等錯誤,如1圖所示。其次,它直接從資料中學習表達空間模型,而無需指定潛在函式的引數形式。第三,其模組化架構允許使用高容量預測器,這些預測器更適合處理每個部件的高度多模態外觀。靈感來自最近的工作[10,11],它們已經證明了檢測更大的組成零件對改善定位調節更精細部件檢測的重要性,作者通過對零件層次結構進行建模,將這些多尺度線索納入作者的框架中。
作者的貢獻在於該方法同時解決了使用推理機的架構進行關節姿態估計的兩個主要挑戰。此外,作者的方法易於實現,在測試時不需要專門的優化求解器,並且在實踐中是有效的。作者對兩個具有挑戰性的資料集的分析表明,作者的方法改進了現有技術,並提供了一個有效的替代框架來解決明確的人體姿態估計問題。
2. 相關工作
從影象和視訊中估計人體明確的姿態有很多工作要做。作者專注於從單個影象估計2D姿態的方法。從影象中估計姿態的最流行的方法是使用影象結構。圖結構模型[1,2,3,4,5,6],將人體表達為樹狀結構的圖模型,其中運動學先驗可以連線四肢。這些方法在人的所有肢體都可見的影象上是成功的,但是容易出現特徵誤差,例如重複計算影象證據,這是由於未由樹狀結構模型建模的變數之間的相關性而發生的。
目前已經有人已經採用了具有非樹相互作用的圖結構模型[12, 13, 14, 15]估計單個影象中的姿態。這些模型增強了樹結構,以捕獲樹中未連結的部分之間的遮擋關係。對這些模型執行精確推斷通常是難以處理的,需要使用學習和測試時間的近似方法。最近的方法也探索了使用部分層次結構[16, 17],和以對定位區域中較大關節周圍的較小部件為條件的檢測[11, 10, 18, 19],這種方法在規範配置中模擬肢體建模,並且往往更容易檢測。
以上模型通常涉及一定程度的細節建模。例如, [3]通過假設成對的潛在引數形式來模擬變形先驗,並且[5]限制每個部件的外觀屬於混合模型。通常需要這些權衡以實現易於理解的學習和推理。即便如此,學習這些模型的引數通常還包括微調求解器或近似分段方法。作者的方法不需要量身定製的求解器,因為它的模組化架構允許作者利用經過充分研究的演算法來訓練有監督的分類器。
[20]中使用強大的外觀模型,通過使用簡單的樹狀結構模型訓練旋轉相關的部分探測器和頭部和軀幹的獨立部分探測器。在[在[21通過使用多個隨機森林階段來學習更好的部分探測器。然而,這種方法使用樹形結構的圖模型來強制空間一致性。作者的方法概括了使用前一階段的輸出來改進部分的概念定位,以非引數資料驅動的方式學習空間模型,並且不需要設計特定於部分的分類器。
作者的方法與深度學習方法[22]有一些相似之處從廣義上講,它也是一個多層模組化網路。然而,與以全域性方式訓練的深度學習方法(例如,使用反向傳播)相反,每個模組以受監督的方式在本地訓練。
作者的方法將部分定位減少到一系列預測。在文獻中時常重新使用順序預測——將預測因子的輸出從前一階段提供到下一階段。方法如[23,24]將順序預測應用於自然語言處理任務。而[25]探討了使用相鄰畫素分類器的上下文來進行計算機視覺任務。作者的方法基於分層推理機器架構[8,9]將結構化預測任務減少到一系列簡單的機器學習子問題。先前已經在影象和點雲標記應用中研究了推理機[8,26]。在這項工作中,作者的貢獻是擴充套件和分析推理機框架,用於關節姿態估計任務。
3. 姿態推理機
3.1 背景
作者將關節姿態估計問題視為結構化預測問題。也就是說,作者模擬影象中每個解剖部位(作者稱之為部分)的畫素位置 ,其中 是影象中所有 位置的集合。作者的目標是預測所有 部分的結構化輸出 。推理機由一系列多類分類器 組成,它們經過訓練可預測每個部分的位置。在每個階段 ,分類器基於影象資料 的特徵和來自每個 周圍附近的前一分類器的上下文資訊來預測置信度,為每個部分分配位置 。在每個階段,對變數的估計的置信度越來越精確。對於序列的每個階段 ,計算分配 的置信度並表示為
其中
是在每個位置 評估的先前分類器對於第 部分的置信度集合。特徵函式 計算上下文來自分類器先前置信度的特徵, ⊕表示運算子用於向量連線。
與傳統的圖模型(如圖結構)不同,推理機框架不需要通過潛在函式對變數之間的依賴關係進行顯式建模。相反,使用分類器任意組合依賴關係,這可能使變數之間的複雜互動成為可能。通過一系列更簡單的子問題直接訓練推理過程,允許作者使用任何監督學習演算法來解決每個子問題。作者在監督學習中利用最先進的技術,並使用能夠處理多模態變化的複雜預測器。如下一節所述,作者的關節姿態估計方法採用分層均值場推理機的形式 [8] ,其中每個變數使用的上下文資訊來自影象中的比例和空間中的相鄰變數。
與傳統的圖模型(如圖結構)不同,推理機框架不需要通過潛在函式對變數之間的依賴關係進行顯式建模。相反,使用分類器任意組合依賴關係,這可能使變數之間的複雜互動成為可能。通過一系列更簡單的子問題直接訓練推理過程,這樣可以使用任何監督學習演算法來解決每個子問題。作者在監督學習中利用最先進的技術,並使用能夠處理多模態變化的複雜預測器。如下一節所述,作者的關節姿態估計方法採用分層均值場推理機[8]的形式,其中每個變數使用的上下文資訊來自影象中的比例和空間中的相鄰變數。
3.2 合併層次結構
最近的工作 [11,10] 已經表明,以較大複合部件的位置為條件的部件檢測改善了姿態估計效能;然而,這些複合零件通常被構造成形成樹狀圖結構 [16] 。受這些最新進展的啟發,作者設計了一種分層推理機,它類似地編碼影象中不同比例的部件之間的這些相互作用。作者定義了從較小的原子部件到較大的複合部件的部件層次結構。層次結構的每個級別 具有不同型別的部分。在最粗糙的層次上,層次結構捕獲整個身體。下一級由模擬完整肢體的部分組成,而層次結構的最精細級別由模擬周圍區域的小部分組成。作者用 表示層次結構的每個 級別中的部件數量。在下文中,作者將 表示為 階段中的第 水平為 部件預測的分類器,其預測 部分的分數。雖然可以在層次結構的每個層次 中為每個部分 訓練單獨的預測變數,但實際上,作者使用單個多類預測變數,從而在層次結構中對給定特徵向量中的所有部分產生一組置信度。為簡單起見,作者刪除上標並將此多類分類器表示為 。
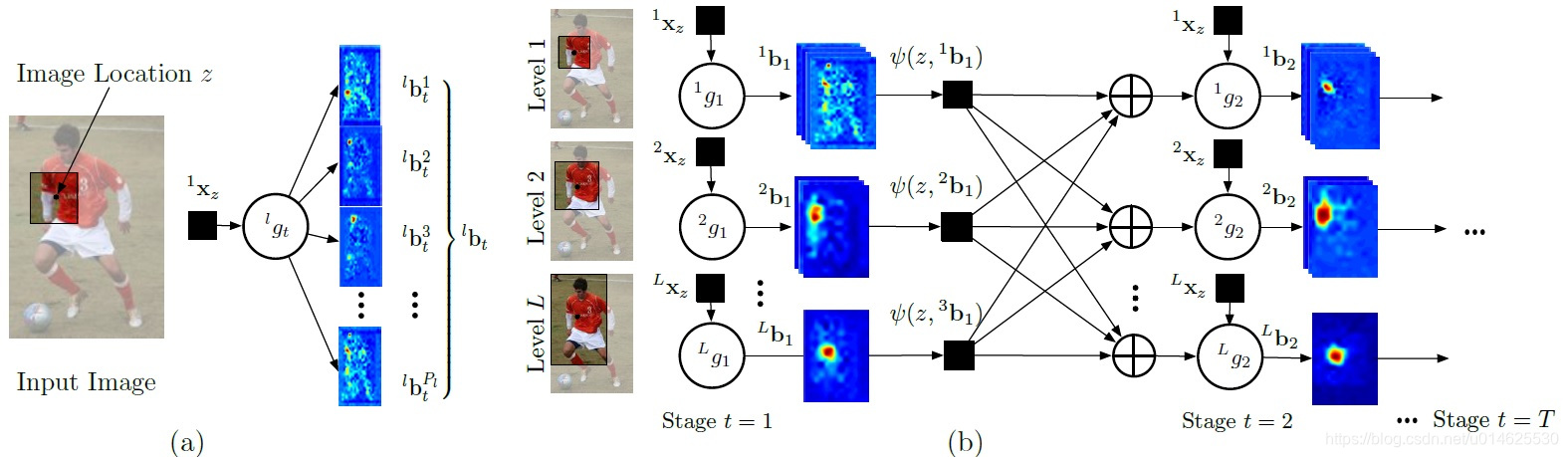
圖2
(a)多級預測。針對層次結構的每個級別訓練單個多類預測器,以將每個影象塊預測為
類中的一個。通過評估影象中的每個補丁,作者建立了一組置信對映
。
(b)姿態推理機的兩個階段。在每個階段,訓練預測器以預測輸出變數的置信度。該圖描繪了在測試時在推理機中傳遞的訊息。在第一階段,預測變數基於在影象塊上計算的特徵產生對每個部分位置的置信度的估計。後續階段預測因子通過上下文特徵函式
使用前一階段輸出中的附加資訊細化這些置信度。
要獲得每個部件位置置信度的初始估計值,在序列的第一階段