
CUDA入門(六) 非同步並行執行解析
阿新 • • 發佈:2018-12-30
為了更好地壓榨GPU和CPU,很多時候都使用非同步並行的方法讓主機端與裝置端並行執行,即控制在裝置沒有完成任務請求前就被返回給主機端。
非同步執行的意義在於:首先,處於同一資料流內的計算與資料拷貝都是依次進行的,但一個流內的計算可以和另一個流的資料傳輸同時進行,因此通過非同步執行就能夠使GPU中的執行單元與儲存器單元同時工作,更好地壓榨GPU的效能;其次,當GPU在進行計算或者資料傳輸時就返回給主機執行緒,主機不必等待GPU執行完畢就可以進行進行一些計算,更好地壓榨了CPU的效能。
之前,單單使用GPU的同步函式,會使裝置在完成請求任務前,不會返回主機執行緒,主機執行緒將進入讓步(yield)、阻滯(block)或者自旋(spin)。
下面一個SDK簡單的非同步並行執行的程式:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <memory.h>
#include<time.h>
#include"helper_timer.h"
__global__ void increment_kernel(int *g_data, int inc_value)
{
int idx = blockIdx.x*blockDim.x + threadIdx.x;
g_data[idx] = g_data[idx] + inc_value;
}
int 執行結果:
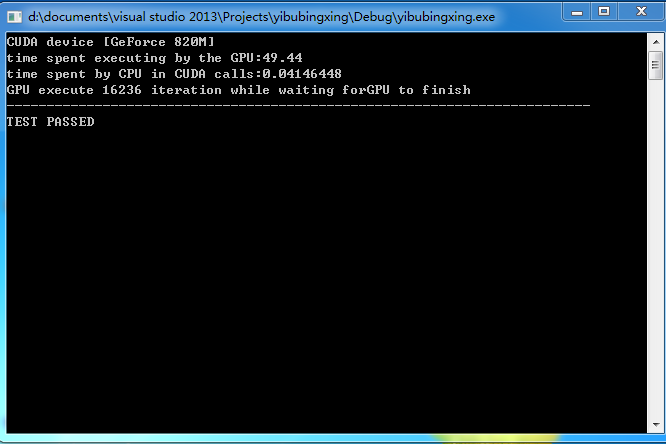
程式碼中
GPU上執行的是對每一個數據進行加26的處理,在CPU上執行加1迭代,
執行結果依次是GPU執行的時間,非同步時CPU呼叫GPU所用的時間,以及在GPU上進行計算時CPU進行迭代的次數。
其中:
void *memset(void *s, int ch, size_t n);
函式解釋:將s中前n個位元組替換為ch並返回s;
memset:作用是在一段記憶體塊中填充某個給定的值,它是對較大的結構體或陣列進行清零操作的一種最快方法。
helper_timer.h在C:\ProgramData\NVIDIA Corporation\CUDA Samples\v7.5\common\inc下是在CUDA取消了cutil.h後包含計時的一個檔案
cudaThreadSynchronize()函式是是CPU與GPU同步