
9 自動識別驗證碼與初識Scrapy框架
自動識別驗證碼與初識Scrapy框架
1、多執行緒優化
2、登入古詩文
登入:直接傳送post,然後傳送get
登入:先發送get,獲取一下資訊,然後再發送post,然後傳送get
登入:get、post、get、get。 訪問登入後的頁面
驗證碼,下載到本地,手動輸入
3、自動識別驗證碼
(1)光學識別 tesseract
指令識別
識別率不行,但是可以訓練它 程式碼識別
pip install pytesseract
pip install pillow
通過影象處理處理一下圖片,然後再去識別,提高識別率(2)打碼平臺
(2)打碼平臺
雲打碼4、scrapy
Scrapy是一個非常強大、精悍的Python網路爬蟲框架,它的底層使用Python語言實現的, 為了爬取網站資料,提取結構性資料而編寫的應用框架。 可以應用在包括資料探勘,資訊處理或儲存歷史資料等一系列的程式中。
其最初是為了 頁面抓取 (更確切來說, 網路抓取 )所設計的, 也可以應用在獲取API所返回的資料或者通用的網路爬蟲。
Scrapy 使用了 Twisted非同步網路庫來處理網路通訊。整體架構大致如下:
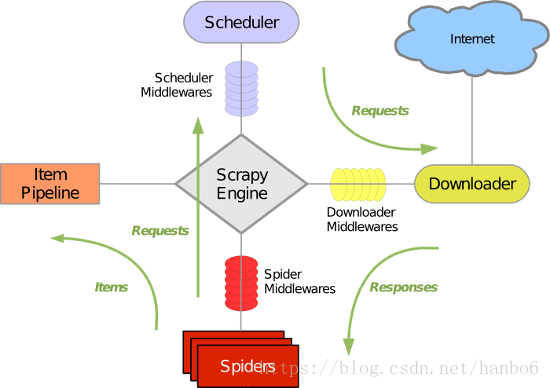
(1)安裝Scrapy
pip install scrapy(2)Acrapy元件
1). 引擎(Scrapy engine)
用來處理整個系統的資料流處理, 觸發事務(框架核心)
2). 排程器(Scheduler)
用來接受引擎發過來的請求, 壓入佇列中, 並在引擎再次請求的時候返回. 可以想像成一個URL(抓取網頁的網址或者說是連結)的優先佇列, 由它來決定下一個要抓取的網址是什麼, 同時去除重複的網址
3). 下載器(Downloader)
用於下載網頁內容, 並將網頁內容返回給蜘蛛(Scrapy下載器是建立在twisted這個高效的非同步模型上的)
4). 爬蟲(Spiders)
爬蟲是主要幹活的, 用於從特定的網頁中提取自己需要的資訊, 即所謂的實體(Item)。使用者也可以從中提取出連結,讓Scrapy繼續抓取下一個頁面
5). 專案管道(Pipeline)
負責處理爬蟲從網頁中抽取的實體,主要的功能是持久化實體、驗證實體的有效性、清除不需要的資訊。當頁面被爬蟲解析後, 將被髮送到專案管道,並經過幾個特定的次序處理資料。
6). 下載器中介軟體(Downloader Middlewares)
位於Scrapy引擎和下載器之間的框架,主要是處理Scrapy引擎與下載器之間的請求及響應。
7). 爬蟲中介軟體(Spider Middlewares)
介於Scrapy引擎和爬蟲之間的框架,主要工作是處理蜘蛛的響應輸入和請求輸出。
8). 排程中介軟體(Scheduler Middewares)
介於Scrapy引擎和排程之間的中介軟體,從Scrapy引擎傳送到排程的請求和響應。
(3)處理流程
Scrapy的整個資料處理流程由Scrapy引擎進行控制,通常的運轉流程包括以下的步驟:
- 引擎詢問蜘蛛需要處理哪個網站,並讓蜘蛛將第一個需要處理的URL交給它。
- 引擎讓排程器將需要處理的URL放在佇列中。
- 引擎從排程那獲取接下來進行爬取的頁面。
- 排程將下一個爬取的URL返回給引擎,引擎將它通過下載中介軟體傳送到下載器。
- 當網頁被下載器下載完成以後,響應內容通過下載中介軟體被髮送到引擎;如果下載失敗了,引擎會通知排程器記錄這個URL,待會再重新下載。
- 引擎收到下載器的響應並將它通過蜘蛛中介軟體傳送到蜘蛛進行處理。
- 蜘蛛處理響應並返回爬取到的資料條目,此外還要將需要跟進的新的URL傳送給引擎。
- 引擎將抓取到的資料條目送入條目管道,把新的URL傳送給排程器放入佇列中。
上述操作中的2-8步會一直重複直到排程器中沒有需要請求的URL,爬蟲停止工作。
(4)建立專案
scrapy startproject xxx(5) 目錄結構解釋
firstbloodpro 工程總目錄
firstbloodpro 工程目錄
__pycache__ 快取目錄
spiders 爬蟲目錄 如:建立檔案,編寫爬蟲規則。
__pycache__ 快取目錄
__init__.py 包的標記
lala.py 爬蟲檔案(*)
__init__.py 包的標記
items.py 定義資料結構的地方(*)設定資料儲存模板,如:Django的Model
middlewares.py 中介軟體
pipelines.py 管道檔案(*)資料處理行為,如:一般結構化的資料持久化
settings.py 配置檔案(*)如:遞迴的層數、併發數,延遲下載等
scrapy.cfg 工程配置資訊(一般不用)主要為Scrapy命令列工具提供一個基礎的配置資訊。(真正爬蟲相關的配置資訊在settings.py檔案中)(6)生成爬蟲檔案
cd firstbloodpro
scrapy genspider xxx www.xxx.com(7)執行命令
cd firstbloodpro/firstbloodpro/spiders
scrapy crawl qiubai
修改settings.py,將遵從robots協議去掉,將UA定製一下
啟動命令中 'qidian'引數為我們定義爬蟲中的name屬性的值
執行流程:
name: spider對應不同的name
start_urls:是spider抓取網頁的起始點,可以包括多個url。
parse():spider抓到一個網頁以後預設呼叫的callback,避免使用這個名字來定義自己的方法。當spider拿到url的內容以後,會呼叫parse方法,並且傳遞一個response引數給它,response包含了抓到的網頁的內容,在parse方法裡,你可以從抓到的網頁裡面解析資料。(8)認識response物件
response.text : 字串格式的內容
response.body : 位元組格式的內容
response.url : 請求的url
response.headers : 響應的頭部
response.status_code : 得到狀態碼
在scrapy裡面,已經為你集成了xpath,直接使用即可
response.xpath('')(9)一鍵指定輸出
scrapy crawl qiubai -o qiubai.json
scrapy crawl qiubai -o qiubai.xml
scrapy crawl qiubai -o qiubai.csv
解決輸出csv有空行問題見部落格
https://blog.csdn.net/qq_38282706/article/details/80279912