
K最近鄰分類演算法原理及例項分析
阿新 • • 發佈:2018-12-31
目錄
- 概述
- 原理
- 要點
- 例項
1、概述
K最近鄰(k-Nearest Neighbor,KNN),指導思想是“近朱者赤,近墨者黑”,由你的鄰居來推斷出你的類別,KNN分類演算法是最簡單的機器學習演算法。
2、原理
從訓練集中找到和新資料最接近的k條記錄,然後根據多數類來決定新資料類別,本質上,KNN是使用距離來計算相似度。
演算法涉及3個主要因素:訓練資料集;距離或相似度的計算衡量;k的大小。
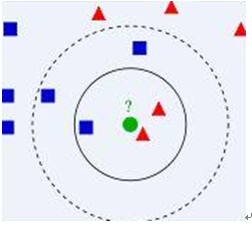
已知兩類“先驗”資料,分別是藍方塊和紅三角,他們分佈在一個二維空間中;
有一個未知類別的資料(綠點),需要判斷它是屬於“藍方塊”還是“紅三角”類;
考察離綠點最近的3個(或k個)資料點的類別,佔多數的類別即為綠點判定類別。
3、要點
- 計算步驟
算距離:給定測試物件,計算它與訓練集中的每個物件的距離;
找鄰居:圈定距離最近的k個訓練物件,作為測試物件的近鄰;
做分類:根據這k個近鄰歸屬的主要類別,來對測試物件分類。
- 相似度的衡量
距離越近應該意味著這兩個點屬於一個分類的可能性越大。
距離不能代表一切,有些資料的相似度衡量並不適合用距離。
相似度衡量方法:包括歐式距離、夾角餘弦等。
簡單應用中,一般使用歐氏距離,但對於文字分類來說,使用餘弦(cosine)來計算相似度就比歐式(Euclidean)距離更合適。
- 類別判定
簡單投票法:少數服從多數,近鄰中哪個類別的點最多就分為該類。
加權投票法:根據距離的遠近,對近鄰的投票進行加權,距離越近則權重越大(權重為距離平方的倒數)
4、例項
- 使用knn演算法來實現對手寫數字的自動識別