
mysql分割槽方案的研究
筆者覺得,分庫分表確實好的。但是,動不動搞分庫分表,太麻煩了。分庫分表雖然是提高資料庫效能的常規辦法,但是太麻煩了。所以,嘗試研究mysql的分割槽到底如何。
之前寫過一篇文章,http://www.cnblogs.com/wangtao_20/p/7115962.html 討論過訂單表的分庫分表,折騰起來工作量挺大的,需要多少技術去折騰。做過的人才知道有多麻煩
要按照什麼欄位切分,切分資料後,要遷移資料;分庫分表後,會涉及到跨庫、跨表查詢,為了解決查詢問題,又得用其他方案來彌補(比如為了應對查詢得做使用者訂單關係索引表)。工作量確實不小。
從網上也可以看到,大部分實施過的人(成功的)的經驗總結:水平分表,不是必須的,能不做,儘量不做。
一、探討分割槽的原理
瞭解分割槽到底在做什麼,儲存的資料檔案有什麼變化,這樣知道分割槽是怎麼提高效能的。
實際上:每個分割槽都有自己獨立的資料、索引檔案的存放目錄。本質上,一個分割槽,實際上對應的是一個磁碟檔案。所以分割槽越多,檔案數越多。
現在使用innodb儲存較多,mysql預設的儲存引擎從mysiam變為了innodb了。
以innodb來討論:
innodb儲存引擎一張表,對應兩個檔案:表名.ibd、表名.frm。
如果分割槽後,一個分割槽就單獨一個ibd檔案,如下圖:
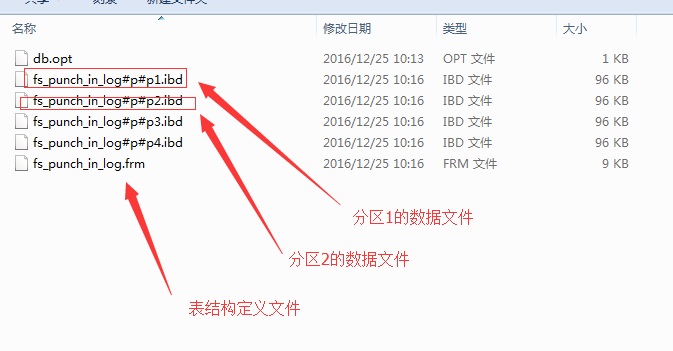
將fs_punch_in_log表拆分成4個分割槽,上圖中看到,每個分割槽就變成一個單獨的資料檔案了。mysql會使用"#p#p1"來命名資料檔案,1是分割槽的編號。總共4個分割槽,最大值是4。
分表的原理,實際上類似,一個表對應一個數據檔案。分表後,資料分散到多個檔案去了。效能就提高了。
分割槽後的查詢語句
語句還是按照原來的使用。但為了提高效能。還是儘量避免跨越多個分割槽匹配資料。
如下圖,由於表是按照id欄位分割槽的。資料分散在多個分割槽。現在使用user_id作為條件去查詢。mysql不知道到底分配在哪個分割槽。所以要去全部分割槽掃描,如果每個分割槽的資料量大,這樣就耗時很長了。
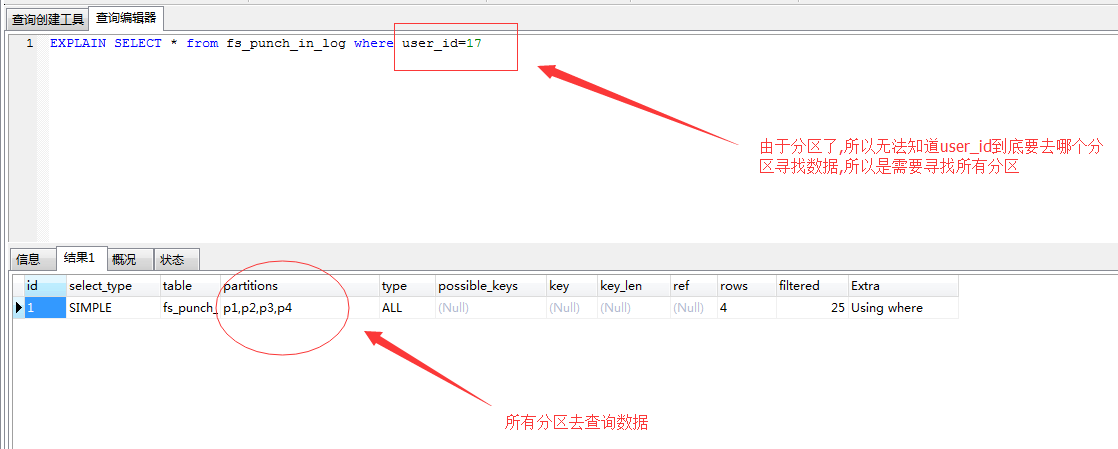
分割槽思路和分割槽語句
id欄位的值範圍來分割槽:在1-2千萬分到p0分割槽,4千萬到-6千萬p1分割槽。6千萬到8千萬p2分割槽。依此推算下去。這樣可以分成很多的分割槽了。
為了保持線性擴容方便。那麼只能使用range範圍來算了。
sql如下
CREATE TABLE `fs_punch_in_log` ( `id` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主鍵自增' , `user_id` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '簽到的使用者id' , `punch_in_time` int(10) UNSIGNED NULL DEFAULT NULL COMMENT '打卡簽到時間戳' , PRIMARY KEY (`id`) )
partition BY RANGE (id) (
PARTITION p1 VALUES LESS THAN (40000000),
PARTITION p2 VALUES LESS THAN (80000000),
PARTITION p3 VALUES LESS THAN (120000000),
PARTITION p4 VALUES LESS THAN MAXVALUE
);
以上語句經過筆者測驗,注意點:
- 按照hash均勻分散。傳遞給分割槽的hash()函式的值,必須是一個整數(hash計算整數計算,實現均勻分佈)。上面的id欄位就是表的主鍵,滿足整數要求。
- partition BY RANGE 中的partition BY表示按什麼方式分割槽。RANGE告訴mysql,我使用範圍分割槽。
情況:如果表結構已經定義好了,裡面有資料了,怎麼進行分割槽呢?使用alter語句修改即可,經過筆者測驗了。
ALTER TABLE `fs_punch_in_log` PARTITION BY RANGE (id) ( PARTITION p1 VALUES LESS THAN (40000000), PARTITION p2 VALUES LESS THAN (80000000), PARTITION p3 VALUES LESS THAN (120000000), PARTITION p4 VALUES LESS THAN MAXVALUE )
注:由於表裡面已經存在資料了,進行重新分割槽,mysql會把資料按照分割槽規則重新移動一次,生成新的檔案。如果資料量比較大,耗時間比較長。
二、四種分割槽型別
mysql分割槽包括四種分割槽方式:hash分割槽、按range分割槽、按key分割槽、list分割槽。
四種有點多,實際上,為了好記,把類再縮小點,就兩大類方式進行分割槽:一種是計算hash值、一種是按照範圍值。
其實分庫分表的時候,也會用到兩大類,hash運算分、按值範圍分。
1、HASH分割槽
有常規hash和線性hash兩種方式。
- 常規hash是基於分割槽個數取模(%)運算。根據餘數插入到指定的分割槽。打算分4個分割槽,根據id欄位來分割槽。
怎麼算出新插入一行資料,需要放到分割槽1,還是分割槽4呢? id的值除以4,餘下1,這一行資料就分到1分割槽。
常規hash,可以讓資料非常平均的分佈每一個分割槽。比如分為4個取,取餘數,餘數總是0-3之間的值(總到這幾個分割槽去)。分配打散比較均勻。
但是也是有缺點的:由於分割槽的規則在建立表的時候已經固定了,資料就已經打散到各個分割槽。現在如果需要新增分割槽、減少分割槽,運算規則變化了,原來已經入庫的資料,就需要適應新的運算規則來做遷移。
實際上在分庫分表的時候,使用hash方式,也是資料量遷移的問題。不過還好。
針對這個情況,增加了線性hash的方式。
- 線性HASH(LINEAR HASH)稍微不同點。
實際上線性hash演算法,就是我們memcache接觸到的那種一致性hash演算法。使用虛擬節點的方式,解決了上面hash方式分割槽時,當新增加分割槽後,涉及到的資料需要大量遷移的問題。也不是不需要遷移,而是需要遷移的資料量小。
在技術實現上:線性雜湊功能使用的一個線性的2的冪(powers-of-two)運演算法則,而常規雜湊使用的是求雜湊函式值的模數。
線性雜湊分割槽和常規雜湊分割槽在語法上的唯一區別在於,在“PARTITION BY”子句中新增“LINEAR”關鍵字。
兩者也有有相同的地方:
- 都是均勻分佈的,預先指定n個分割槽,然後均勻網幾個分割槽上面分佈資料。根據一個欄位值取hash值,這樣得到的結果是一個均勻分佈的值。後面新增新的分割槽多少需要考慮資料遷移。
- 常規HASH和線性HASH,因為都是計算整數取餘的方式,那麼增加和收縮分割槽後,原來的資料會根據現有的分割槽數量重新分佈。
- HASH分割槽不能刪除分割槽,所以不能使用DROP PARTITION操作進行分割槽刪除操作;
考慮以後遷移資料量少,使用線性hash。
2、按照range範圍分割槽
範圍分割槽,可以自由指定範圍。比如指定1-2000是一個分割槽,2000到5000千又是一個分割槽。範圍完全可以自己定。後面我要新增新的分割槽,很容易嗎?
3、按key分割槽
類似於按HASH分割槽,區別在於KEY分割槽只支援計算一列或多列,且MySQL伺服器提供其自身的雜湊函式。必須有一列或多列包含整數值。
4、按list方式分割槽
可以把list看成是在range方式的基礎上的改進版。list和range本質都是基於範圍,自己控制範圍。
range是列出範圍,比如1-2000範圍算一個分割槽,這樣是一個連續的值。
而list分割槽方式是列舉方式。可以指定在1,5,8,9,20這些值都分在第一個分割槽。從list單詞的字面意思命名暗示就是列表,指定列表中出現的值都分配在第幾個分割槽。
三、如何根據業務選擇分割槽型別
1、何時選擇分割槽,何時選擇分表
分表還是比分割槽更加靈活。在程式碼中可以自己控制。一般分表會與分庫結合起來使用的。在進行分表的時候,順帶連分庫方案也一起搞定了。
分表分庫,效能和併發能力要比分割槽要強。分表後,有個麻煩點:自己需要修改程式碼去不同的表操作資料。
比如使用者表分表後,計劃分4個表,每個表4千萬使用者。按照使用者編號取模為4。程式碼很多處要做專門的匹配如下:
每次操作使用者資料,先要根據uid算出是哪個表名稱。然後再去寫sql查詢。 當然,是可以使用資料庫中介軟體來做完成分庫、分表。應用程式碼不用修改。大部分中介軟體是根據他們自己的業務特點定製的,拿來使用,不見得適合自己的業務。所以目前缺少通用的。
如果使用分割槽的方式。程式碼不用修改。sql還是按照原來的方式寫。mysql內部自動做了匹配了。
非常適合業務剛剛起步的時候,能不能做起來,存活期是多久不知。不用把太多精力花費在分庫分表的適應上。 考慮到現在業務才起步,使用分割槽不失為一種既省事又能提高資料庫併發能力的辦法。等以後業務發展起來了,資料量過億了,那個時候經濟實力已增強,再做改進方案不遲。 架構是演變出來的,不是設計出來的。適應當前業務的方案,就是好的方案。 過度設計也是一種負擔:很多技術,企圖一開始就設計出一個多大量的系統,實際上沒有那種量,為了顯示自己技術牛逼。 總結:訪問量不大,但是資料錶行數很多。可以使用分割槽的方式。訪問量大,資料量大,可以重構成分表的方式。
這是因為雖然資料量多,但是訪問量不大,如果使用分表的話,要修改程式碼很多地方,弄起來太麻煩了。投入多,產出少就沒必要了。
2、如何選擇適合自己的分割槽型別 使用分割槽和分表一樣的思想:儘量讓資料均勻分散,這樣達到分流、壓力減小的效果。如果不能均勻分佈,某個分割槽的操作量特別大,出現單點瓶頸。 雖然4種類型的分割槽方式。其實總共兩大類,按範圍分割槽和按hash運算分割槽。 range範圍分割槽,適合按照範圍來切分資料。比如按時間範圍分割槽。 hash,適合均勻分散資料。使用hash分割槽,麻煩點是後續增加分割槽,資料要遷移。有了線性hash分割槽法,這個遷移量減低了很多。 以使用者表為例子,如果要使用分割槽方案。改使用哪種分割槽型別呢?
考慮到user_id一般不會設計成自增數字。有人會奇怪,怎麼不是自增的,我見過好多使用者編號都是自增的! 的確,有自增數字做uid的,不過一般是開源系統為了省事,比如discuz、ecshop等。人家沒那麼多工作量給你設計使用者編號方案。 自增的使用者編號,由於是每次加1進行遞增的。這規律太明顯了,很容易被別有用途的人猜測user_id。再說,別人一看就知道你有多少使用者! 有個原則,設計編號的時候,儘量不要讓外部知道你的生成規律。比如訂單號,如果是逐個加1的訂單號,外界可以猜測出你的業務訂單總數出來。 說一個自增使用者編號的例子。筆者曾經在一家上市網際網路公司,有幾千萬的使用者,uid過去是discuz那一套自增的方式。後來不得不改掉user_id的生成方式。筆者當時負責了這個改造方案。 不是自增的數字,會是這種:註冊一個是1897996,再註冊一個是9689898,外界完全找不到數字的規律。 不是自增的編號,如果使用範圍來分割槽,各個分割槽的資料做不到均勻分佈的。原因如下: 比如說使用者編號為1-200000000的使用者分配到p1分割槽,20000000-40000000分配到p2分割槽,40000000-60000000分配到p3區,這樣類推下去。 由於使用者編號不是自增,註冊分配到的使用者編號,可能是1到2千萬之間的數字,也可能是4千萬到6千萬之間的一個數字。如果被分配到4千萬到6千萬的數字會更多,那麼各個分割槽給到的資料是不均勻的。 故不好使用範圍來分割槽。 比較好的辦法是,使用hash取模,user_id%分割槽數。資料就可以分散均勻到4個分割槽去了。