
Python簡單爬取圖片例項
都知道Python的語法很簡單易上手,也很適合拿來做爬蟲等等,這裡就簡單講解一下爬蟲入門——簡單地爬取下載網站圖片。
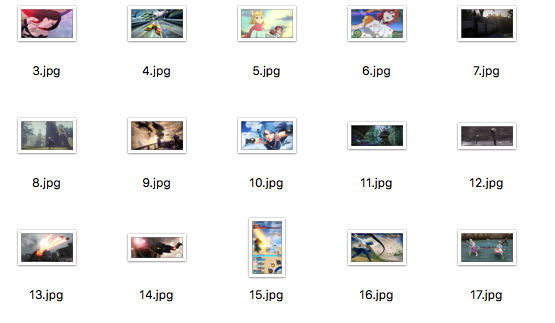
效果
就像這樣自動爬取下載圖片到本地:
程式碼:
其實很簡單,我們直接看下整體的程式碼:
#coding = utf-8
import urllib
import re
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
reg = 'src="(.+?\.jpg)" alt='
imgre = re.compile(reg)
imglist = re.findall(imgre, html)
x = 0 匯入庫:
第一行的utf-8是為了支援中文。
這裡我們匯入了兩個庫,分別是 urllib 和 re。urllib 是用來進行 url 網路請求的,而 re 是一個正則表示式匹配的庫。這裡我們要先對網站進行模擬請求,然後找到網站中的圖片進行下載。
請求網站:
第一個方法:getHtml。
這就是用來模擬瀏覽器訪問網站的,引數 url 是要訪問的網站連結,這裡我們在下面的變數 html 處呼叫了這個方法,其訪問的 url 是一個圖片網站,關於選擇訪問網站還有一點等下要說一下。
在這個方法中,我們先用了 urllib 庫的 urlopen 方法來開啟網站,然後通過 read 方法來獲取網站的原始碼,其實就跟在網頁中“右鍵–>檢查“是一個意思。最後返回了讀取到的網站原始碼。
上面說了要注意的一點是,由於很多網站會禁止人們隨意爬取資料,有反爬蟲的技術,所以在選擇要爬取的網站的時候,最好先通過這個方法獲取網站原始碼,然後 print 輸出 html 變數看一下獲取到的內容是否是正常的網頁原始碼,而不是403之類的禁止訪問,如果被禁止了,那麼自然也不可能爬取到資料了。
找到圖片:
接下來是一個 getImg 方法。
在這個方法中,我們設定了一個正則表示式,用來在網頁原始碼中找到圖片的資源路徑,這個正則表示式要根據不同的網站去具體設定,比如我爬取的這個網站,圖片對應的原始碼是這樣的:
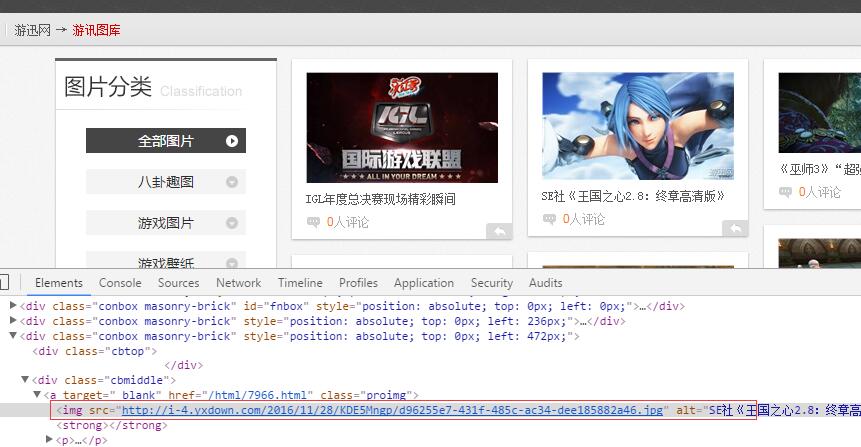
因此我們設定的正則表示式就是 reg = ‘src=”(.+?.jpg)” alt=’ ,其實就是根據圖片資源路徑前後的內容來限制的。
這裡也要注意一點,有的網站做了動靜分離,圖片有其單獨的完整資源路徑,而有的是直接是相對位置,這時候要麼對其路徑進行處理,但大多時候你並不知道怎麼處理才能拼出完整路徑,因此還是找有完整資源路徑的圖片來試驗比較好。
緊接著用 re 庫的 compile 函式將正則表示式轉換成正則表示式物件,然後使用 findall 函式尋找 html 網頁原始碼中包含的匹配 imgre 的所有內容,返回一個序列。我們可以輸出這個序列,可以看到大量圖片資源路徑組成的一個序列,如果沒爬取到,就是個空序列了。
下載圖片
最後一步就是下載圖片,這裡我們用 for 迴圈,將圖片資源路徑中的每個圖片,使用 urllib 庫的 urlretrieve 函式來下載圖片,這個函式其實可以接受很多引數,這裡我們設定了要下載的圖片資源路徑和要命名的名字(我們使用一個變數x來對每個圖片依次命名為0,1,2…),還可以設定下載路徑、用來顯示下載進度的回撥函式等等。如果不設定下載路徑預設會下載到程式碼檔案當前所在的資料夾。
執行
現在,去執行一次程式碼就可以啦,mac本身是支援python的,不用配置環境,直接將程式碼放入一個 .py 檔案中,使用終端進入其檔案位置,敲入 python xxx.py 命令就可以啦。