
從原始碼角度理清memcache快取服務
memcache作為快取伺服器,用來提高效能,大部分網際網路公司都在使用。
前言
文章的閱讀的物件是中高階開發人員、系統架構師。
本篇文章,不是側重對memcache的基礎知識的總結,比如set,get之類的命令如何使用不會介紹。是考慮到,此類基礎知識網路已經有一大把資料,所以更加傾向於深入性的知識點。文章側重的重點是對memcache的原理理清楚、在實戰中自己所遇到的坑、自己的思考心得與理解。
好記性不如爛筆頭,整理文章的初衷是為了加深自己的理解,對知識進行梳理,人的大腦會逐步遺忘,記下來的文字,方便以後查閱。
本文太長,一時看得暈,請挑你你需要的部分看。或者收藏起來,以後有更新部分,可以繼續訪問。筆者以後也會將一些疑惑的知識點,繼續完善到文章中去。
文章為原創,轉摘歡迎你註明出處,謝謝!
一、memcache的原理
關係型資料庫的資料是放入在硬碟上的。磁碟的瓶頸是i/0(機械裝置,靠磁碟片旋轉來定位資料)。
而memchace利用記憶體的速度快,把資料存入到記憶體中。記憶體這個裝置有個特點,斷電後,記憶體裡面的所有資料就會丟失。
基於這個特點,我們在架構的系統中使用memcache時,放入memcache中的資料,最終還是要在磁碟上有備份,不然丟失掉了。沒地方去找了。
memcache本質就是在管理著一大片的記憶體區域。我們的程式去跟memcache提供的介面儲存和獲取資料。注意,這個記憶體,memcache
二、memcache管理記憶體的機制
先了解memcache的資料型別,方便理解後續知識。
memcache只提供了一種資料型別:key->value。key是字串,value也必須是字串。
2.1、額外知識點:作業系統與記憶體的關係
理解一個大前提非常重要:記憶體是作業系統在管理。
作業系統是責與所有硬體交換(硬碟,磁碟,記憶體、外設印表機等)。我們電腦插槽那個記憶體,也是作業系統在統一管理。
於是,在作業系統執行下的所有軟體(mysql,memcache,nginx等等),需要記憶體的時候,都是要去跟作業系統申請記憶體。
軟體向作業系統申請記憶體的辦法
每次跟作業系統申請記憶體的最小單位是頁(page)。就像稱重規定最小單位是克,人自己這麼約定的。
關鍵詞:一次申請的最小單位是頁(page)。
注:並不是說一次只能申請一頁(4kb)。是指只能按照4k*n為單位進行申請記憶體。
作業系統是這樣管理記憶體的:
把記憶體劃分成等份大小的份(一塊一塊的)。這種在作業系統概念中叫做分頁法。
有分頁又有分段,概念容易弄暈了。其實,分段技術早於分頁技術。過去是作業系統是使用分段技術來管理記憶體(程式執行在哪個記憶體區間,這就是段)
但是分段法存在一些缺陷,所以後來作業系統使用分頁法了。
2.2、核心機制:slab機制介紹
memcache借鑑了linux作業系統中的slab管理器的模式,使用slab方式來管理從作業系統申請到的記憶體。
2.2.1、借鑑了linux的slab管理器
slab管理器的來源。在核心中,經常會發生對有限的幾種資料結構頻繁的分配記憶體和回收記憶體,比如程序描述符struct task_struct,索引節點物件struct inode等等。相比4KB或者8KB的物理頁而言,這些物件往往較小,例如程序描述符一般只有1.7KB左右,索引節點物件則更小。那麼對於這種高頻發 生的小資料結構的記憶體分配和回收,是否有可能進行優化呢? 電腦科學家Jeff Bonwick早已關注到這一點。同時他還發現,核心中普通物件進行初始化所需的時間超過了對其進行分配和釋放所需的時間。於是他設想這樣改進:不將記憶體釋放回一個全域性的記憶體池,而是將記憶體保持為針對特定目而初始化的狀態。後續的記憶體分配不需要重複初始化,因為從上次釋放和呼叫析構之後,它已經處於所需的狀態中了。基於這些思路,slab分配器(slab allocator)應運而生。slab分配器主要的功能就是對頻繁分配和釋放的小物件提供高效的記憶體管理。它的核心思想是實現一個快取池,分配物件的時候從快取池中取,釋放物件的時候再放入快取池。
memcache也使用這樣的辦法:模擬實現了一個slab分配器,把從作業系統申請到記憶體快取起來,即便是刪除資料了,這部分記憶體也不會返回給作業系統,只是標識一個狀態"空閒"。目的是方便下回使用。slab管理器的核心思想其實就是:對頻繁使用的小物件進行快取起來,不要釋放掉。最終避免頻繁的申請、釋放操作造成效能問題(耗資源)。
實際上早期的memcache版本並沒有採用slab管理器的思路,後來的版本才改善,使用slab機制。
memcache在使用slab機制出現以前,記憶體的分配是通過對所有記錄簡單地進行malloc和free來進行的(對作業系統申請記憶體和釋放記憶體)。 但是,這種方式會導致記憶體碎片,加重作業系統記憶體管理器的負擔,最壞的情況下, 會導致作業系統比memcached程序本身還慢。Slab Allocator就是為解決該問題而誕生的。
2.2.2、slab class 和slab page、chunks的關係
把相同大小的記憶體塊,歸類到一個組,這個組叫做slab class。這樣子是解決了linux的slab管理器的思想。
memcache向作業系統申請記憶體,是以slab page為單位的,slab page的大小是1m。也就是每次申請1m(這個值可以修改,啟動的時候-I引數指定,最小1K,最大128M)。
注:這個page不是作業系統概念中的page,memcahce中的page與作業系統的page不是一回事。一些文章中用page來稱呼,我以前被誤導了,以為是作業系統概念中的page,作業系統概念中的page,一個單位是4kb。而memcache這裡是1m了。個人理解,memcache之所以要稱呼為page,是因為這是從作業系統申請的記憶體空間,恰好作業系統分配記憶體給應用軟體是以page為單位的。
一個slab page裡面會有很多的chunks(大小相同的記憶體塊),chunks是真正儲存key->value的區域(其實就是劃分出來的記憶體小塊)。
memcache從作業系統申請記憶體,一次跟作業系統申請1m大小的記憶體(1m認為就是一個slab page)。
然後把這個1m的記憶體,分成相等大小的chunks。比如1m=1024kb=1024*1024b=103445504(位元組)。
假設平分的大小是88個位元組。那麼就是103445504/88=90112個chunks。
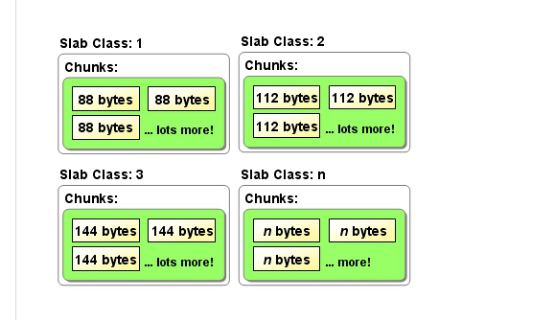
如上圖:slab class 1裡面都是88位元組的chunks。slab class 2裡面都是112位元組的chunks。
一個slab class裡面可能有多個slab page。至少是一個slab page(當chunks不夠用的的時候,就會跟作業系統申請新的slab page加入到slab class中)。如下圖表示slab class裡面有多個slab page了(一個slab calss下面的每個page,其擁有的chunks數量都是一樣的)。
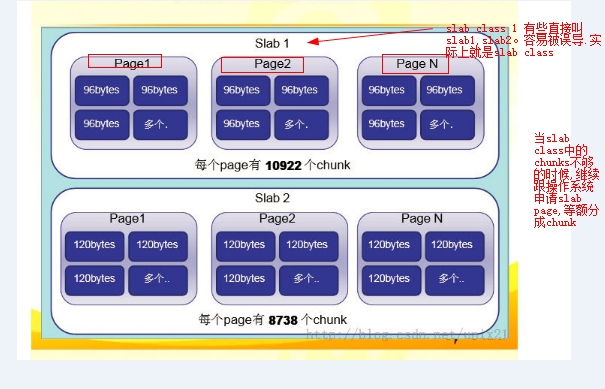
思考:每個slab class中的chunks的大小是由什麼決定的呢?
由上一個slab class中的chunks大小決定。計算公式為:當前slab class中的chunks大小=上一個slab class的chunks大小*增長因子。
增長因子預設是1.25。比如上一個是288,那麼288*1.25=360。下一個slab class中的chunks大小是:360*1.25=456。
注:啟動memcache的時候,第一個slab class裡面的chunks都是48個位元組。這個值是可以配置的。
2.2.3、往memcache新增key的內部機制
新增一個key->value的步驟如下:
1、先定位到合適的slab
判斷邏輯是這樣:新加入一個key->value(也叫item),先計算這個key->value的整體大小。假設是118個位元組。
那麼去slab列表裡面,尋找哪個slab能夠儲存下。最終找到是144位元組的chunks組(slab3)能夠儲存。
思考:為什麼是slab class 3,而不是slab class 4、slab class 5呢?
memcache的計算辦法是,優先選擇最小的slab class。原始碼在slabs.c中的slabs_clsid()函式中。這個函式傳入一個容量進去,返回能夠儲存其容量的slab class編號。
2、定位到合適的slab後
到這一步,現在找到slab3是可以存放。於是進入到slab3裡面去。那slab3裡面有沒有空閒空間來儲存呢?
所以得先看看slab3裡面是不是有空閒的chunks。memcache為每個slab維護了一個空閒連結串列。通俗理解就是:記錄這個slab那些chunks空間是可以用的。包括過期、刪除狀態(標識為軟刪除)。
在該slab class中,會優先選擇過期的chunks空間和刪除掉的chunk進行來儲存,其次將選擇未使用過的chunk(即完全空著,從來沒有用過的chunks)進行儲存。
思考:這樣做的好處是什麼?不要汙染掉真正空閒的地方。空閒的trunk是沒有儲存任何資料的。而被刪除和過期的trunks則裡面儲存了資料,所以優先使用。借鑑這種思想。
通過上面步驟,在當前slab class裡面假設找到了可以用的chunks,那麼返回一個chunks以供使用。
假設當前slab class中沒有可用的chunkns,怎麼辦呢?
此時,memcache就會跟作業系統去申請記憶體了。預設一次申請1m的記憶體空間。申請1m。然後繼續切分。
注意:關於切分,很多這裡沒有說透,以前我被誤導了。這時候其實不是新開slab class。是對當前的slab class 3進行的操作:
當前的slab class 3裡面的chunks都是144個位元組。那麼好,新申請的1m記憶體,就按照144個位元組來切分。計算方法列出來看看:
1m=1024k=1024*2014b=103445504位元組。
103445504/144位元組=718317個塊(chunks)。
這718317個chunks,就會加到slab class 3裡面去。
三、memcahce的監控
使用一個php語言開發的介面管理工具。名稱叫做memadmin。

根據實戰經驗,要注意的一個監控項,就是LRU數。通過這可以看出,是不是發生了記憶體不夠的情況了。如下圖:
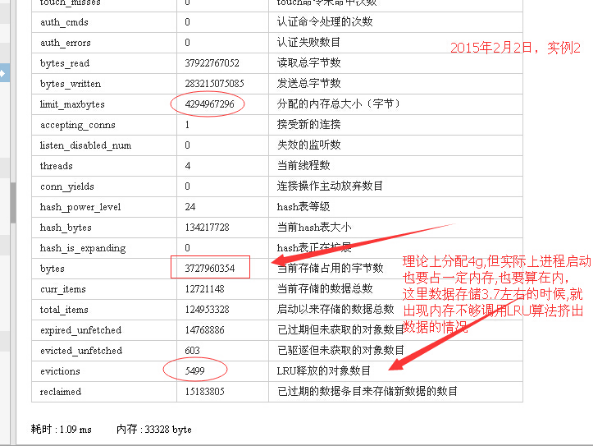
另外一個項,bytes,當前儲存佔用了多少位元組。這個項的值,我們會被誤導。
比如顯示佔據的儲存空間是3.7g。遠遠沒有達到最大分配的記憶體數4g。但是這個階段卻發生了lru剔除資料的現象。
其實有些slab class佔據著記憶體空間。這些記憶體空間並沒有機會被新加入的key->value來使用,於是導致了某些slab class無法繼續申請新的記憶體的現象。
而lru只是針對當前訪問的slab class進行的。並不是針對全域性(所有slab class)進行。
通俗點理解如下:
slab class 1
slab class 2
slab class1 中有大量空閒的記憶體空間,而新加入的key->value都是進入到slab class 2去。slab class2中沒有空閒的記憶體空間了。 memcache就跟作業系統申請記憶體,作業系統沒有足夠的記憶體給予memcache(發生LRU演算法的大前提後續有文字解釋),這個時候 memcache迫不得已了,就會執行lru演算法。
研究這裡的統計值是怎麼算出來的,可以避免被誤導
這個統計值的計算標準是怎麼樣的? 什麼時候會更新呢?
1、新增一個item成功後,會增加統計值。
每次新增一個key,就會讓這個統計項的值增加。可以這麼理解:增加一個key->value成功後,就更新掉那個總數值。比如新增加的 key->value大小是220個位元組,而恰好定位到slab class 3。假設裡面的chunks大小是260個位元組。
實際上統計總數的時候,就會增加260個位元組。雖然只佔220個位元組。但是chunks的機制,260-220=40個位元組,也是空著的,不能被拿來使用(相當於記憶體碎片了),那麼會按照260個位元組來說。
2、delete命令和get命令的時候,會減小統計值。
經我測驗:只有delete和get命令時才會將佔據的記憶體統計值減小值。get命令,會判斷當前讀取的key是否過期,若過期了,則會把對應的記憶體空間標識為可用狀態,同時就會將統計總數值減小。
測驗思路如下:故意新增一個失效期只有50秒的key,這個key的大小是298個位元組。然後去memcache命令列使用stats命令檢視記憶體佔用的空間(或者memadmin介面工具也可以)。因為添加了一個值,於是發現統計總數增加了298個位元組。
50秒過後,再去執行stats命令,發現統計值並沒有變化。
當我使用get命令查詢這個key時,memcache會檢查這個key已經過期,則會自動更新掉統計值。delete命令也是類似。
3、flush_all的用途是將所有的key都設定為過期,執行這個命令所佔記憶體會不會清0呢?
結論:執行flush_all命令後,統計值是不會有變化的。
解釋:使用flush_all是不會訪問到所有key的。只是設定一個類似於這樣的標記:flush_all_time=記錄上一次失效的時間。
思考:從上面做實驗來看,這個統計所佔據的記憶體值,只能做一個大概的。並不不是很準確的。比如一個item佔著記憶體空間260個位元組,實際上這個item已 經過期了。由於一直沒有機會使用get命令讀取這個item,那麼memcache的總數統計項中,並沒有減掉這個260個位元組。所以看起來統計值是接近 4g了。我們會覺得,記憶體是不是不夠用了,其實不必擔憂,重點是看有沒有發生LRU計數項。這個是很重要的資料。
四、memcache的長連線實驗
memcache服務端提供了tcp協議介面來操作。所以paython,java,php都可以基於這個協議來與memcache通訊。
php連結memcache服務端,使用的是memcached擴充套件(客戶端)。
客戶端連結memcache服務端,有長連線和短連線兩種方式。
4.1、短連線與長連線的比較
到底哪種方式效率高? 效能更好呢?
筆者認為是長連線。既然設定了長連線,那麼肯定有它用武之地。當遇到大量的併發請求的時候,長連線可以發揮出效能優勢。主要是基於:tcp連線數會更少。如果大量的客戶端連線memcache服務,在linux可以看到很多的tcp連線。
我的測驗辦法是:使用ab命令去發起大量請求到一個php檔案。而這個php檔案就是去與memcache服務進行互動。馬上在linux使用命令netstat -n -p | grep 11211檢視11211這個埠的tcp連線情況。
使用短連線,看到效果如下:
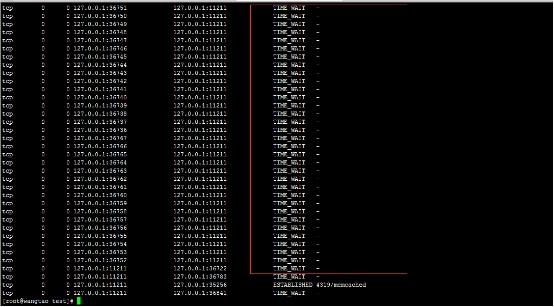

客戶端頻繁地與memcache服務,實際上就是一個這樣的過程:建立連線>釋放連線。
遇到大量的請求,頻繁的建立>釋放tcp連線,是需要耗費linux檔案控制代碼的。會使得linux伺服器檔案控制代碼達到極限。處理不過來。
另外導致的問題是,cpu的負載高。建立和釋放釋放資源(連線),實際上是比較耗費cpu資源的。大量重複建立和釋放連線,會讓cpu的負載變高。
如下命令可以統計指定埠的tcp連線總數:
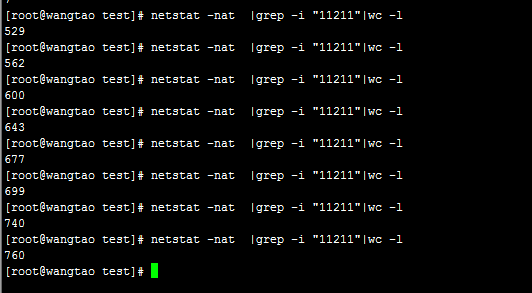
當我使用ab命令併發請求php的時候,從上圖看到11211埠的tcp連線數一直在增加。
使用長連線的效果,同樣使用ab命令併發請求php,
長連線的測驗辦法:可以在linux通過命令,看到即便是請求結束後,還是能夠看到這些連線。
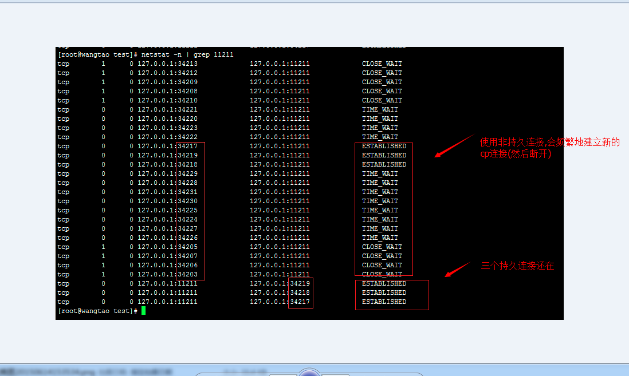
上圖的狀態為established。就是一直在保持連線狀態的tcp連線。
當使用長連線的時候,在linux服務端看到的連線總數,也比較少。
可以預先開多少個連線。
4.2、長連線的優勢
思考:什麼情況下使用長連線,什麼情況下使用短連線呢?
高併發請求下,才能看到長連線帶來的明顯效益:tcp連線複用、資源消耗少(主要是cpu負載)。
很多人表面看覺得,使用長連線(持久連線),會佔著資源一直不釋放掉。消耗太多資源。從直覺上,更加喜歡建立>斷開連線的操作方式,明顯感覺會釋放資 源,所以會減少資源消耗。我們可能以為,來2000個請求,使用持久連線,就會建立2000個連線,即便請求完畢後,2000個連線也一直維護著。於是比 較耗費資源。
持久連線,是一種複用技術。預先建立500個連線,放入連線池裡面。當有請求來的時候,先去連線池裡面看,是 否有空閒狀態的連線,有就拿過來使用。若沒有可用連線,則建立一個連線,用完這個連線後,是釋放掉,還是接著放入連線池呢?可以進行配置的。可以配置連線 池中保持多少個連線在等待請求。
並不是說,2萬個客戶端請求,那麼就要一直維護著2萬個連線。實際上連線池裡面維護的可能是1000個連線(可以自己配置),連線池中這1000個連線是與服務端(比如mysql、memcache)維持著通訊狀態的。
在計算機中有一個經驗:頻繁地建立資源和釋放資源(比如建立連線),帶來的開銷比維護這些資源都要高.維護只需要在記憶體中傳送心跳包,需要的時候從記憶體中調 用出,由於已經在記憶體中了,不用去建立資源了,直接從記憶體中調出來的資料很快的。作業系統linux中著名的slab機制管理記憶體空間,就是基於這個原來 做的。slab管理機制,會將記憶體區域自己維護起來,減少頻繁地申請和釋放記憶體資源,記憶體其實沒有釋放,只是標識了一個狀態:可用、不可用。
需要的時候,直接拿過來使用(避免申請耗費cpu資源)。
現在發現,學到一個思想:頻繁使用的資源,要快取起來。目的是避免頻繁地去申請、釋放。設計一個連線池方案,是一種成熟的技術,不會那麼弱智。
平時大部分應用都用不上連線池
平時我們使用短連線,是建立tcp連線,用完後釋放掉tcp連線。我們習以為常,實際上是因為大部分應用不會遇到連線數瓶頸(建立連線用完只要快速釋放,看起來速度很快),所以沒有使用連線池帶來的好處。
這很像http請求場景:大量的http請求80埠。建立連線>傳輸完資料>斷開連線,也是一次短連線的過程。我們看不到問題。
我們使用資料庫連線池技術(長連線就是維護著一個連線池,叫法不同),平時開發中並不需要使用,而是在高併發情況下,才會看到使用資料庫連線池帶來的明顯效果。
連線池技術是針對高併發情況下進行的優化,在沒達到連線瓶頸的時候,用了跟沒用,看不出明顯速度區別的。
五、思考與解惑
思考1:配置memcahce的最大記憶體空間為2g。那麼,memcache是不在是啟動的時候,就跟作業系統申請那麼多的記憶體空間呢?
不是。如果會一開始就跟作業系統申請這麼多的記憶體。這樣的壞處明顯。比如memcache儲存的資料量一直都維持在1g的容量,而memache就跟操作申請2g記憶體,完全是浪費記憶體資源。memcache預設會建立n個slab cass。但實際上每個slab class也只跟作業系統申請了1m的記憶體。
memcache佔有多少記憶體,key->value的資料越來越多,跟作業系統申請的記憶體越來越多。
思考2:當資料過期時,或者是說將資料刪除後,佔據記憶體有沒有被釋放掉呢?
答案:並沒有。memcache只是對自己維護的記憶體區域標識了一個狀態"空閒"、"已被使用"。其實memcache已經從作業系統申請到的記憶體,比如佔了1g了。並沒有返回給作業系統的。只有等到memcache程序終止掉了,作業系統會自動回收。
memcache其實是故意不返回的,借鑑了slab管理器的思想。記憶體沒有釋放給作業系統,而是自己維護著一個狀態。下一次其他資料需要儲存的時候,直接拿到這些空閒的記憶體儲存資料即可了。
思考3:memcache對資料的過期是如何檢測的?
網上有資料,提到是懶惰刪除法。就是在訪問這個key(使用get命令讀取)的時候,才去判斷此key是否過期。若過期了,則將其佔據了記憶體區域(chunk塊)標識為空閒狀態。
之所以叫做懶惰法,筆者這樣理解:平時並不去主動掃描所有key的過期時間,需要用到這個key的時候,才去判斷過期。這是懶人做法。如果是勤奮的做法,一般開一個垃圾回收執行緒,定期去掃描key,發現過期了,就將此塊記憶體區域標為"空閒"狀態。但是這樣專門開一個執行緒去掃描,需要耗費cpu資源。
懶惰刪除法的缺點是:如果這個key一直沒有去訪問,那麼就永遠不知道有沒有過期(memcache不會標識其記憶體區域為空閒狀態)。那麼這塊記憶體,沒法讓其他key加入進來使用。 造成了記憶體的浪費。
redis吸取了這個教訓,做了一點改進:每次讀取key的時候,選定一個範圍內的資料掃描一次。
思考4:LRU列表、空閒chunks列表、空閒chunks總數統計
筆者在看那個LRU演算法的時候,網上一些資料,看暈了。需要區分一下概念,原始碼才能看得明白邏輯:
新增資料的時候,定位到合適的slab class後(比如slab class3),會去LRU列表中,拿最末尾的一個item,若其時間已經過期,則直接返回記憶體空間使用。
若找不到,則去slab class的空閒空間拿記憶體空間。
得理清楚上面一些概念,不然搞不明白。從網上弄了一張比較好的圖,根據自己的理解,在圖中自己加了一點說明:
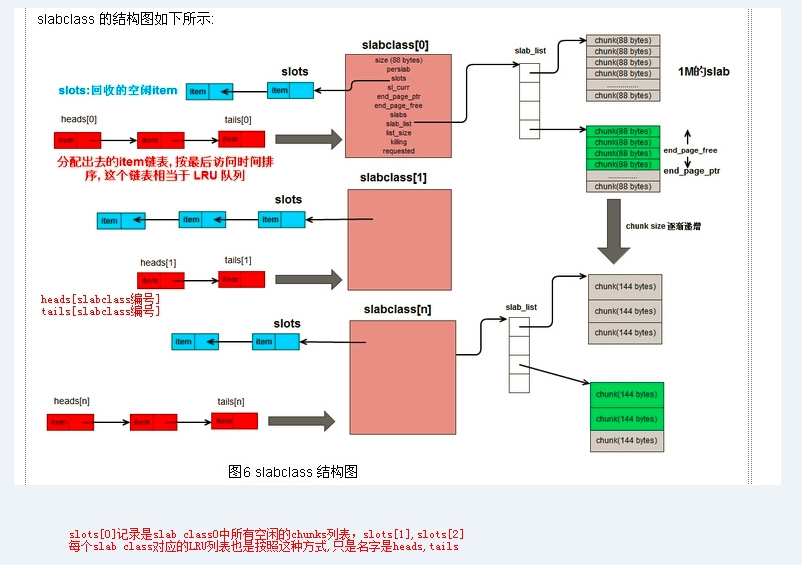
LRU列表: 記錄著一個slab class中最近訪問的item,按照最近訪問時間進行排序。
訪問這個列表,有兩種方式:一種是使用tails,這是從尾部開始訪問,得到的訪問時間離現在最遠的item; 另外一種是使用heads,從頭部開始訪問。得到的訪問時離現在最近的item。
tails[id],id是一個整數,是slab class的編號。每個slab class都有一個tails佇列。使用tails是從尾部開始訪問,如果需要從頭部開始訪問這個列表,那麼就使用heads[i]。
注:尾部的資料,就是相對沒那麼頻繁訪問的,於是memcache優先從尾部拿一個item來判斷是否過期。
空閒item列表slots:原始碼中完整引用是p->slots,p就表示某個指定的slab class。slots中記錄的是可以拿來使用的item(記錄的是哪些,是一個列表)。比如一個item被刪除,或者程式碼檢測到過期時間已經過期,那麼都會把item加到這個空閒列表中去。
sl_curr:原始碼中完整引用是p->sl_curr,儲存是一個整數。統計當前有slab class有多少個空著的item。比如有5個,那麼這個項的值就是5。memcache原始碼中的解釋為:total free items in list
上述項的值更新是怎麼進行的? do_slabs_free()函式中會有如下程式碼:
p->slots = it;//slots是儲存要回收的空閒items,加到裡面去
p->sl_curr++;//給當前slab的空閒item個數+1 。
思考5:LRU演算法是在什麼時候才會執行?
只有當申請不到記憶體的時候。才去做LRU演算法。其實這是一種迫不得已的辦法:沒有記憶體可用了。為了保證資料能儲存進去,只能踢下一些不太使用的資料了
注:有個配置-M可以配置memcache記憶體不夠的時候,禁止資料儲存進去,而不是執行LRU演算法。不過一般不怎麼用,因為資料儲存不進去,使用體驗不好。
怎麼樣才算申請不到記憶體空間呢? 兩種情況可能會出現:
1、memcache去跟作業系統申請記憶體,一方面是作業系統沒有足夠的記憶體分配給memcache(總共4g記憶體,作業系統沒有足夠記憶體分配了)。
2、由於memcache啟動的時候配置了一個最大限制記憶體(啟動時的-m引數),目前memcache佔據的記憶體,已經超過這個數了。
示範:
/usr/local/memcached/bin/memcached -d -m 1024 -u root -l 127.0.0.1 -p 11211
-m指定了2014,單位是m。也就是最大1g記憶體。
更加細化到什麼命令執行:在執行新增item操作的時候,才有可能去執行LRU演算法。get操作不會去執行LRU演算法。get命令記得回去判斷key的過期,然後標識為過期狀態,標識為過期狀態,就加到佇列中了。這樣它佔據的記憶體就可以騰出了使用了。
新增資料涉及到的LRU思路,看原始碼,LRU演算法是在items.c檔案中的do_item_alloc()中執行。筆者通過閱讀原始碼理清楚瞭如下步驟:
步驟1、do_item_alloc()是在新增加key的時候呼叫的。這個函式的作用是:傳入一個key->value,然後函式會計算key->value所需要的大小,比如所需空間是280個位元組。那麼就會去slab calss列表裡面尋找一個能夠儲存下的slab class。找到一個slab class後,就會進入到slab class裡面去搜索了:從LRU列表(LRU列表前面有解釋)的尾部,彈出末尾的一個item。判斷它的過期時間,如果這個item已經過期,正好可以拿其記憶體空間來使用。
步驟2、如果第一步拿到的item沒有過期,然後才考慮,從當前slab class裡面獲取空閒的chunks塊。
步驟3、如果當前slab class裡面沒有空閒的chunks,則會申請一個slab page(1m大小)放入到當前slab class裡面去 (封裝在do_slabs_alloc()中實現)。
步驟4、如果還不成功,那麼就執行LRU演算法了:將LRU列表中,從尾部踢下一個item。LRU列表是按照最近訪問時間來排序的,從尾部踢的一個item,相對來說是最不活躍的item了。
注:每次剔除一個,都會讓計數器(監控中的evitions項)加1的。於是就有我們在監控上去看evitions項的值。
上述步驟,每進行一次若沒有拿不到item空間,那麼會會重複進行5次(封裝在一個for迴圈裡面,迴圈5次)。
函式呼叫關係依次為:
do_store_item()>>do_item_alloc()>>>slabs_alloc()>>do_slabs_alloc()>>do_slabs_newslab()
do_store_item()在memcache.c檔案
do_item_alloc()在items.c檔案
slabs_alloc()在slab.c檔案
do_slabs_alloc()在slab.c檔案
do_slabs_newslab()在slab.c檔案
這部分的原始碼閱讀
看memcache原始碼,在檔案items.c檔案中,裡面的註釋是我根據自己理解加的。


/* +----------------------------------------------------------------------- 整個函式的目的是:尋找合適的slab儲存一個item,最終返回item空間的的引用 +----------------------------------------------------------------------- 使用場景:儲存一個key->value操作的時候。 +-------------------------------------------------------------------- 給定一個key,計算key需要的空間。 把大小傳入slabs_clsid()函式,然後返回slab的編號。如果找不到適合大小的slab,則整個返回0 會先計算key->value所需空間,然後尋找合適的slab class +----------------------------------------------------------------------- */ //原始碼資料參考:http://blog.csdn.net/caiyunl/article/details/7878107 item *do_item_alloc(char *key, const size_t nkey, const int flags, const rel_time_t exptime, const int nbytes, const uint32_t cur_hv) { uint8_t nsuffix; item *it = NULL; char suffix[40]; //給suffix賦值,並返回item總的長度(除去cas的)。總長度用於決定該item屬於哪個slabclass //疑問:value的長度呢? nbytes引數 size_t ntotal = item_make_header(nkey + 1, flags, nbytes, suffix, &nsuffix); /* 從巨集ITEM_ntotal可以看出一個item 的實際長度為 sizeof(item) + nkey + 1 + nsuffix + nbytes ( + sizoef(uint64_t), 如果使用了cas) */ if (settings.use_cas) { ntotal += sizeof(uint64_t); } //傳入大小,返回一個適合此大小儲存的slab編號 unsigned int id = slabs_clsid(ntotal); if (id == 0) return 0;//返回0,則表示從目前的所有slab列表裡面找不到適合儲存的slab class(因為item太大了) //外面呼叫這個函式判斷,只是設定。如果沒有找到合適的slab,為什麼沒有去建立一個slab呢? //do_slabs_newslab /* 每個 slabclass 都擁有一些 slab, 當所有 slab 都用完時, memcached 會給它分配一個新的 slab, do_slabs_newslab 就是做這個工作的. */ mutex_lock(&cache_lock); //優先去slab的佇列尾部尋找過期的item空間,意思是想優先使用這些空間來替換 /* do a quick check if we have any expired items in the tail.. */ int tries = 5;//嘗試多少次 int tried_alloc = 0;/*記錄是否申請記憶體失敗,根據這個值判斷*/ item *search;//這裡只是初始化,值在後面賦值 void *hold_lock = NULL; rel_time_t oldest_live = settings.oldest_live;//使用flush_all命令相關的設定 /*從尾部開始搜尋,因為尾部的time總是最早的,所以就是一種LRU實現 */ search = tails[id];//每個slab有個自己的tails陣列,id就是slab的編號 /* tail這個陣列就是維護的是一個slab按照訪問時間排序的item,應該只保留部分資料。到時候執行lru演算法也踢掉這裡面的item。也就是time時間最小的算是距離現在時間最遠的,就會被踢掉。 */ /* We walk up *only* for locked items. Never searching for expired. * Waste of CPU for almost all deployments */ /* 迴圈5次:從最近訪問的item佇列(tails[id]),尾部開始遍歷5個item看看。 這裡就是一種lru演算法。最近最少使用,其實就是根據訪問時間來排序成一個佇列。 */ for (; tries > 0 && search != NULL; tries--, search=search->prev) { uint32_t hv = hash(ITEM_key(search), search->nkey, 0); /* Attempt to hash item lock the "search" item. If locked, no * other callers can incr the refcount */ /* FIXME: I think we need to mask the hv here for comparison? */ if (hv != cur_hv && (hold_lock = item_trylock(hv)) == NULL) continue; /* Now see if the item is refcount locked */ if (refcount_incr(&search->refcount) != 2) { refcount_decr(&search->refcount); /* Old rare bug could cause a refcount leak. We haven't seen * it in years, but we leave this code in to prevent failures * just in case */ if (search->time + TAIL_REPAIR_TIME < current_time) { itemstats[id].tailrepairs++; search->refcount = 1; do_item_unlink_nolock(search, hv); } if (hold_lock) item_trylock_unlock(hold_lock); continue; } /* Expired or flushed */ /* 先檢查 LRU 佇列中最後一個 item 是否過期, 過期的話就把這個 item空間拿來使用 */ if ((search->exptime != 0 && search->exptime < current_time) || (search->time <= oldest_live && oldest_live <= current_time)) { /*優先選擇最近最少訪問列表中已經過期的一個item來使用*/ itemstats[id].reclaimed++;//替換次數加1,顯示在stats命令中的 reclaimed項 if ((search->it_flags & ITEM_FETCHED) == 0) { itemstats[id].expired_unfetched++; } it = search;//把這個空間返回使用,實際上就是替換掉已經過期的item slabs_adjust_mem_requested(it->slabs_clsid, ITEM_ntotal(it), ntotal);//雖然屬於同一個slabclass,但是長度仍可能不一樣,需要修改一下 do_item_unlink_nolock(it, hv); //將過期的item從雙向連結串列和hash表中除去 /* Initialize the item block: */ it->slabs_clsid = 0; } else if ((it = slabs_alloc(ntotal, id)) == NULL) { /* 1、找不到已經過期的chunks空間(),則slabs_alloc()函式是從當前選擇的slabclass獲取空閒的item空間 2、slabs_alloc()如果找不空閒的chunk空間,會去跟作業系統申請一個page加到當前slab class裡面 3、如何這樣申請記憶體空間失敗的話:就把 LRU 佇列最後一個 item 剔除, 然後分配出來使用(返回) */ tried_alloc = 1;/*記錄是否申請記憶體失敗,1標識為失敗*/ if (settings.evict_to_free == 0) { //==0表示關掉了LRU踢下線演算法,直接不允許存入資料進memcache itemstats[id].outofmemory++; } else { /* 這部分程式碼就是lru的踢下操作了:執行到這裡的時候,已經是迫不得已了: 在當前slab class過期的空間沒找到、空閒的空間也沒有、跟作業系統申請記憶體也失敗 最下策的辦法:甭管了,從LRU列表中踢一下一個來使用吧。 */ itemstats[id].evicted++;//當前的slab被踢下去的總數加1 itemstats[id].evicted_time = current_time - search->time;//最近發生踢下去操作的時間 if (search->exptime != 0) itemstats[id].evicted_nonzero++; if ((search->it_flags & ITEM_FETCHED) == 0) { itemstats[id].evicted_unfetched++;//被剔除的資料中,統計這種資料:從來沒有被獲取過一次的 } it = search; slabs_adjust_mem_requested(it->slabs_clsid, ITEM_ntotal(it), ntotal); /* 把這個 item 從 LRU 佇列和雜湊表中移除 */ do_item_unlink_nolock(it, hv); /* Initialize the item block: */ it->slabs_clsid = 0; /* If we've just evicted an item, and the automover is set to * angry bird mode, attempt to rip memory into this slab class. * TODO: Move valid object detection into a function, and on a * "successful" memory pull, look behind and see if the next alloc * would be an eviction. Then kick off the slab mover bef