
VITAL: Visual Tracking via Adversarial Learning 閱讀筆記
本文概覽
本文是一篇很不錯的關於目標跟蹤演算法的文章,收錄於CVPR2018。
本文主要分析了現有的檢測式跟蹤的框架在模型線上學習過程中的兩個弊病,即:
①、每一幀中正樣本高度重疊,他們無法捕獲物體豐富的變化表徵;
②、正負樣本之間存在嚴重的不均衡分佈的問題;
針對上述問題,本文提出 VITAL 這個演算法來解決,主要思路如下:
①、為了豐富正樣本,作者採用生成式網路來隨機生成mask,且這些mask作用在輸入特徵上來捕獲目標物體的一系列變化。在對抗學習的作用下,作者的網路能夠識別出在整個時序中哪一種mask保留了目標物體的魯邦性特徵;
②、在解決正負樣本不均衡的問題中,本文提出了一個高階敏感損失來減小簡單負樣本對於分類器訓練的影響。
個人評價:本文思路明確,解決問題的方法新穎且有效,實驗效果好,不愧是通過殘酷的CVPR2018篩選後的精品文章!
GAN
①、既然本文是基於GAN思想的一篇文章,然而考慮到有些讀者只是聽說過GAN怎麼怎麼火,怎麼怎麼牛,其實並不太瞭解GAN是個什麼東西,我就儘量簡單通俗的說一下我對GAN思想的理解,用來理解這篇文章應該是夠了(我也是現學現賣~為了看懂本文,特意去看了一下什麼是GAN,已經懂GAN的大神請自動飄過這一段~~~)。
②、什麼是GAN?
首先,假設我們有一個非常先進的測謊儀,這個測謊儀很強大,我們一說謊,它就能“嗶~”一聲,然而它不是完美的,他也是有漏洞的,只是我們難以發現。現在,我們的目標是做一個“說謊儀”,雖然我們本人沒辦法騙過測謊儀,但是我們可以通過訓練一個說謊儀來說謊,並且希望這個說謊儀的謊話能騙過測謊儀就OK了。既然測謊儀很強大,那麼我們在訓練過程中就使用測謊儀,說謊儀沒騙過測謊儀我們就fine-tune說謊儀,直到它戰勝了測謊儀為止。
上述說謊儀和測謊儀博弈的過程就是GAN的主要思想。GAN有兩個元件,分別為:生成器和判別器,這裡,生成器就相當於剛剛說的說謊儀,判別器就相當於測謊儀。我們訓練GAN的主要目的就是想在判別器足夠強大的前提下,訓練生成器讓判別器認為生成器生成的樣本就是“真”樣本,也就是讓說謊儀說一句謊話,希望測謊儀誤認為這是真話,那麼我們認為這個生成器(說謊儀)就訓練成功或者說足夠強大了。
③、一般GAN的數學表達:
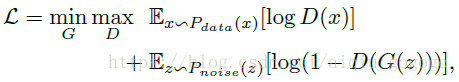
符號解釋:代表一個生成器,是一個服從分佈的隨機噪聲,自然代表生成器對隨機噪聲的處理,D是一個判別器,是一個服從分佈的真實樣本;
解釋:上述公式是一個損失函式,如果覺得難以理解,那我們就先去掉,當只有的時候,上式可以理解為我要得到一個判別器使得後面那一坨最大,後面那一坨什麼時候最大呢?當然是當和差異最大的時候,所以綜上所述,當只有
訓練目的:和相互博弈的最終結果就是,能將服從分佈的隨機噪聲近似轉換為服從分佈的真實樣本,只有這個時候再強也沒什麼辦法了~~~;
結果:訓練結束後,我們扔掉,剩下的就是想要的東西了~他的作用就是給一個隨機噪聲,把它經過變換後與非常相似,以至於我們很難分辨一個圖片是還是;
④、作者指出傳統的GAN並不適合於直接用在目標跟蹤任務中,主要有以下三點原因:
Ⅰ、在目標跟蹤中,輸入網路的資料不是隨機噪聲,而是一個從實際圖片中取樣得到的影象區域塊;
Ⅱ、在目標跟蹤中,我們需要有監督的訓練分類器,而不是像傳統GAN一樣做無監督的訓練;
Ⅲ、在目標跟蹤中,我們最終的目的是獲得分類器,而不是像傳統GAN一樣最終目的是獲得。
Motivation
①、由於基於檢測式跟蹤的框架存在每一幀中正樣本高度重疊的現象,所以他們無法捕獲物體豐富的變化表徵,之前的基於深度學習的跟蹤器們在豐富訓練樣本多樣性上突出的工作較少。一般來說,分類器在學習過程中更加關注距離分類面較近的樣本,也就是更具有判別力的樣本。然而,(※※※INSIGHT※※※)在目標跟蹤中,目標在各幀之間變化迥異,在當前幀認為最有判別力的樣本,在後續幀中未必是最有判別力的,所以用當前幀訓練的模型在後續幀中泛化能力可能較差,因此一些目標短暫的的部分遮擋或者平面外旋轉可能造成模型更新漂移。所以,如何在特徵空間中對正樣本進行增強,從而在豐富目標的變化以更好更魯棒的更新跟蹤器模型,是跟蹤器設計過程中的重要問題。(這一段不知道說明白沒有~)
②、在目標跟蹤問題的模型更新過程中存在明顯的正負樣本比例失調的問題(這個很好理解),因此如何使得跟蹤器的更新更關注有判別力的樣本,削弱那些很簡單的負樣本對跟蹤器更新的影響,對跟蹤器的魯棒性至關重要!
本文方法概述
①,本文在VGG-M模型基礎上進行改進,在最後一個卷積層和第一個全連線層之間增加了一個產生式網路,從而達到在特徵空間增強正樣本的目的。具體的,產生式網路輸入為目標特徵,輸出為一個mask矩陣,該mask矩陣作用於目標特徵後表示目標的一種外觀變化。通過對抗學習,該產生式網路可以產生能保留目標特徵中最魯棒部分的mask矩陣(說白了就是自動判斷特徵中哪部分是目標的魯棒表達,哪部分對目標變化不魯棒,幹掉後者保留前者的智慧mask矩陣)。最終,訓練得到的產生式網路生成的mask矩陣可以對判別力強的特徵進行削弱,防止判別器過擬合於某個樣本。
(這裡,可能會有人提出疑問,削弱有判別力的特徵?有沒有搞錯?當然沒有~聽我解釋:首先,我們要知道判別力強的特徵和魯棒性強的特徵是不一樣的,打個比方——假設我們要跟蹤一個人臉,一開始都是正常的人臉,然後我突然在第100幀的時候往人臉上貼一個小的暴走漫畫!那麼,對於100幀來說,這個暴走漫畫就屬於判別力強的特徵,因為他相對人臉其他部分來說邊緣性強,而且只有人臉這裡有這個漫畫,其他地方都沒有,在第100幀可以合理的認為有漫畫的地方就是人臉,這就是判別力強的特徵。而什麼是魯棒性強的特徵呢?當然是眼睛,眉毛,鼻子,嘴之類的,因為他們始終屬於人臉,並且大部分時候都是可見的,我們根據他們來判斷一個目標框是不是人臉,從長遠角度看是更可靠的,畢竟第150幀你可能撕掉了暴走漫畫,但是你撕不掉鼻子吧~所以,我們希望判別器關注魯棒性強的特徵(因為它具有一般性),削弱判別力強的特徵(因為它具有偶然性));
②、本文提出了一個高階敏感損失來減小簡單負樣本對於分類器訓練的影響,這個道理很簡單,那些明明很容易被分類正確的負樣本其實在訓練過程中也會產生損失,然而不希望網路關注這些損失,因為關注他們反而會使得網路效能變差,實驗證明,本文提出的新的損失函式不但可以提升精度,同時可以加速訓練的收斂。
本文方法——對抗學習in目標跟蹤
①、先上網路結構圖吧:
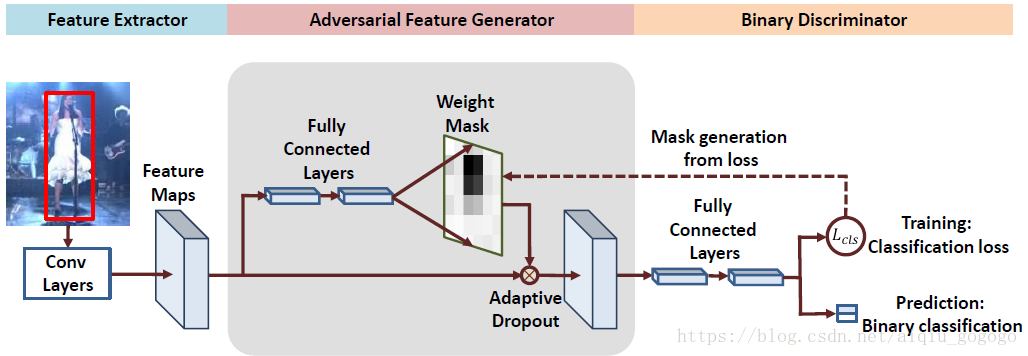
②、在解釋網路結構之前先翻譯幾句作者對方法的重要闡述:
Ⅰ、我們將分類層看作為一個判別器,並且提出了一個用來進行對抗學習的生成器;
Ⅱ、一般來說,已有的GAN都是目的得到一個生成器,用來將一個隨機分佈轉換為一個指定分佈,不像已有的GAN方法,本文的目的在於獲得一個對目標變化魯棒的判別器;
③、網路簡析:在特徵提取和分類器之間增加了一個生成式網路,被用來產生加權的作用於目標的特徵的mask矩陣(目的就是為了在特徵層面豐富目標的多樣性),mask矩陣為單通道的和特徵解析度相同的矩陣,與特徵通道做點乘操作;
④、本文核心損失函式(堅持一下,快結束了):
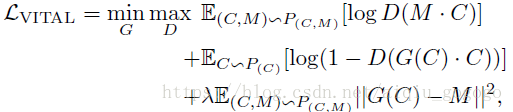
符號解析:代表目標經過VGG-M網路後得到的多通道的特徵,