
Semantic Autoencoder for Zero-Shot learning閱讀筆記CVPR2017收錄
論文地址:https://arxiv.org/pdf/1704.08345.pdf
程式碼地址:https://elyorcv.github.io/projects/sae
該論文已經被CVPR2017收錄。主要是關於利用語義自編碼器實現zero-shot learning的工作。一定程度上解決了訓練集和測試集的領域漂移(domain shift)問題。整個演算法最核心的地方是在自編碼器進行編碼和解碼時,使用了原始資料作為約束,即編碼後的資料能夠儘可能恢復為原來的資料。該方法在6個數據集上的zero-shot
learning結果都為目前最好。該方法還能解決監督聚類問題(supervised clustering problem),並也能取得目前最好的效果
作者使用了一個十分基礎的自編碼器對原始樣本進行編碼,其結構如圖1所示,其中X為樣本,S為自編碼器的隱層,x^為由隱層還原為樣本的表示。需要注意的是隱藏層S層為屬性層,它不僅僅是原樣本的另一種表示,它同時也有著清晰的語義。
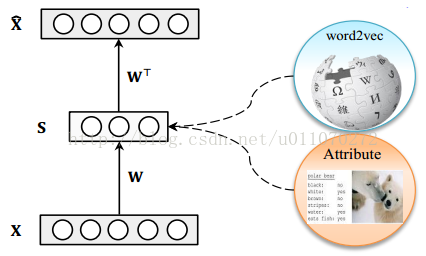
圖1 自編碼器結構
貢獻
(1)提出了一種新的用於zero-shot learning語義自編碼模型;(2)提出了模型對應的高效的學習演算法;(3)演算法具有擴充套件性,可以用於監督聚類問題(supervised clustering問題)。實驗證明,該演算法在多個數據集上能取得最好效果。
對映領域漂移(Projection domain shift)
對於zero-shot learning問題,由於訓練模型時,對於測試資料類別是不可見的,因此,當訓練集和測試集的類別相差很大的時候,比如一個裡面全是動物,另一個全是傢俱,在這種情況下,傳統zero-shot learning的效果將受到很大的影響。
演算法內容
語義自編碼器
上文已經提到了作者所使用的自編碼器,它只有一層隱層,且隱層的維數要小於輸入層的維度。設輸入層到隱層的對映為W,隱層到輸出層的對映為W*,W和W*是對稱的,即有W*等於W的轉置。由於我們希望輸入和輸出儘可能相似,則可設目標函式為:
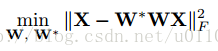
傳統的自編碼器是非監督學習的,但在此問題中,我們希望中間層能夠有語義的含義,能表示類標或者表示樣本屬性。即,加入約束WX=S,其中S是X對應的事先定義好的語義向量,換句話說,每個樣本x都可以表示為一個向量s,這個s是事先定義好的。當加入這樣一個約束之後,就可以使得原本非監督學習的自編碼器變為監督學習的自編碼器,使得自編碼器的中間層表示在合理的空間內。此時目標函式可以表示為:
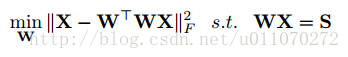
目標函式最優化求解
原目標函式可以表示為:
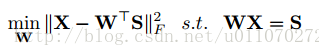
目標函式中,有WX=S,直接使用這樣的約束太強了,可以想象,需要自編碼器的中間層完全等於事先定義好的值,這樣的條件實在是太苛刻了。因此,可以將原式寫成:

這樣同時將約束寫入了目標函式中,也不需要拉格朗日法進行求解了,只需要簡單的步驟就可以進行求解。我們注意到上式是個標準二次型(standard quadratic formulation)的形式,利用矩陣跡的運算進行改寫(Tr(X)=Tr(X轉置),Tr(W轉置乘S)=Tr(S轉置W))
直接求導,讓導等於0,可得:
這個式子可以寫成Sylvester equation的形式,可以使用Bartels-Stewart演算法[1]進行求解。在matlab中有現成的函式,程式碼如圖2所示。最終就可以求得對映函式W。

圖2 matlab程式碼
Zero-shot learning
有了求對映矩陣W的方法,即可以將樣本對映到對應的屬性空間中,即可預測測試樣本的類別。如果讀者很清楚zero-shot learning的概念和基本方法的話,就應該很容易理解了,為了照顧新手,這裡還是說一些具體實現。在實現zero-shot learning時,我們先將資料集分為訓練集和測試集,且兩個資料集的資料類別之間是沒有交集的。利用一些先驗知識得到每種類別的屬性向量表示,通過上文的方法,利用訓練集訓練出對映矩陣W,這樣就可以對測試集中的樣本進行類別的預測。
在此工作中,需要檢驗兩個方面,一個是中間層的準確度,第二是輸出層的準確度。只需要利用對映矩陣W得到測試樣本的中間層表示和輸出表示,與ground truth進行比較,就可以了。
如果我們拋開自編碼器的結構,將問題考慮為普通的學習對映矩陣的問題,即:輸入為X,屬性層為S,希望學習一個對映W,使得S=WX。一般的想法就是構建如下目標函式,並且加入L2-norm作為約束。

在論文[2]中,希望能夠使得屬性層S能夠映射回樣本X,則有
可以看出,本文演算法的目標函式是上述兩種方法的結合,只是去除了L2-norm項。因為本文演算法中隱式包含了這個約束,能夠控制它的值處於一個較為合理的範圍。
監督聚類(supervised clustering)
簡單來說就是通過訓練集訓練出對映W,利用W將測試集的樣本表示為屬性層的表示形式,注意這裡的屬性層是二值化的,並且將其表示為one-hot的形式,這樣就可以用屬性層來表示類別了。之後再進行kmeans聚類,得到測試集合的聚類結果。
實驗結果
資料集:使用了6個數據集供檢測演算法的zero-shot learning能力,分為是:1)Animals with Attributes(AwA).2)CUB-200-2011 Birds(CUB).3)aPascal&Yahoo(aP&Y).4)SUN Attribute(SUN).5)ILSVRC2010(ImNet-1).6)ILSVRC012/ILSVRC2010(ImNet-2)。其中,後兩個資料集是大型的資料集。細節如表1所示。

屬性層:對於前面四個小型資料集,zero-shot learning中用到的中間屬性層有資料集提供;對於大型資料集,通過訓練Wikipedia語料庫進行生成。
樣本特徵:ImNet-1使用AlexNet得到4096維特徵,其他資料集樣本使用GoogleNet得到樣本的1024維特徵。
如表2所示,為本文演算法與其他演算法在不同資料集上的比較結果。其中A表示屬性表示,W表示詞向量表示。可以看到本文演算法的效果最好。

如表3所示,本文演算法目標函式中兩個部分共同存在的重要性,當兩部分同時存在,即對對映函式增加了“可以恢復到原樣本”的約束。由表可知,這個約束對結果的提升非常大。

為了進一步檢測其zero-shot learning效能,作者將測試集中也包括了部分訓練集的類別,這本質上是一種檢測演算法泛化能力的方法。結果如表4所示,可以看到在資料集AwA上要比目前最好的演算法差一點點,在CUB上效果為最好。

作者還比較了演算法的計算時間,由於本文演算法的結構十分簡單,相比之下其他演算法要複雜得多,因此本文演算法速度快很多。如表5所示。

作者還進行了監督聚類(supervised clustering)的檢測。結果如表6、7、8和圖3所示。

總結
細想來,本文提出的演算法思路簡單、模型簡單、實現簡單,但是卻能達到目前最好的效果,實在令人佩服。其實,此演算法最大的亮點就在於由自編碼器結構所形成的對目標函式的約束,這個約束的效果非常明顯。其實這個想法在論文[3]中就有體現(感興趣的可參考http://blog.csdn.net/u011070272/article/details/73293740),其中的linguist prior思想和本文思想如出一轍,不過本文的模型要簡單很多。
參考文獻:
[1]Solution of the matrix equation ax+ xb= c
[2]Ridge regression, hubness, and zero-shot learning.
[3]Automatic Discovery, Association Estimation and Learning of Semantic Attributes for a Thousand Categories