
一次NoHttpResponseException問題分析解決
新專案上線遇到NoHttpResponseException的問題,

大概11000筆發到C系統的交易會出現15筆會因這種異常而導致失敗,對月交易量在近三億的系統來說,按照這樣的比例也會有4萬多筆的交易失敗,這種嚴重影響客戶體驗的現象堅決不能容忍。
按照套路網上搜了下這種出現這種異常的原因以及解決辦法,apache網站的解釋是:
In some circumstances,usually when under heavy load, the web server may be able to receive requests but unable toprocess them. A lack of sufficient resources like worker threads is
意思就是當伺服器端由於負載過大等情況發生時,可能會導致在收到請求後無法處理
聯絡了W公司的同事,確認他們的C系統的負載還遠未達到過載的程度,而且我們發到他們B系統的交易從來沒有出現過這種異常,他們也無法解釋這種異常產生的原因。那就抓包看下tcp連線互動的情況。
圖一

圖二
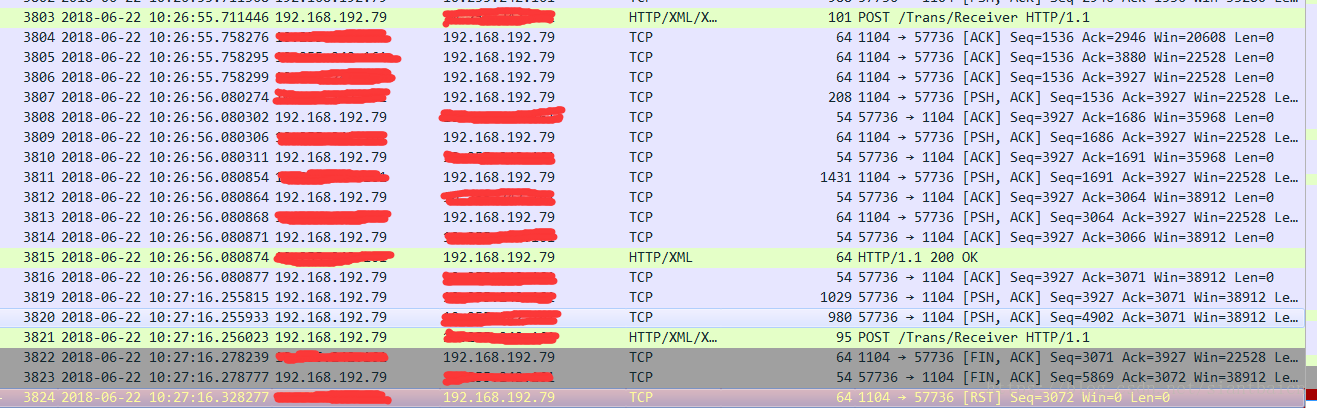
兩筆異常交易的共同點就是(以圖二為例)C系統在2891個包發來了揮手,然後在2893個包RST了連線,導致我方系統第2888、2889發的請求沒有收到響應就異常結束了。
這裡有2個問題(自問自推測):
1. C系統為什麼會發送結束連線的FIN揮手包?
注意到圖二在第2882個包C系統返回前一個請求的響應完成(10:16:25),到第2888個包(10:16:46)我方傳送下一個請求,之間有個21s的空閒間隔,圖一中C系統在發出FIN揮手包之前也有一個20s的空閒間隔,會不會是C系統的伺服器會在每個連線空閒20s後自動就會發起斷開連線呢?再看下圖三正常結束交易的tcp流,也是在收到客戶端的確認包後有20s的空閒間隔。
基本上可以推斷出C系統的伺服器會在連線空閒20s後自動發起斷開連線。

圖三
2. C系統為什麼會直接發出第2893個RST包,而不是發出正常的Ack確認包?
按照圖二的tcp流序列,客戶端發出的第2888個包在收到服務端傳送的第2891個FIN包之前,只個是在客戶端抓的包,請求的網路傳輸時間。C系統的服務端發出的FIN包時很可能還沒收到我方傳送的第2888個請求。即服務端傳送FIN包後,馬上就收到了第2888個請求包,以及第2892個[FIN、Ack]包,自身無法判斷是正常結束,所以就發出來RST包,關閉連線。
我方系統是用httpclient4.3的60s的長連線傳送請求,使用的http1.1協議連線是預設keepalive的,同一個執行緒的多個請求可以複用同一個長連線。正是由於c系統發出FIN包的時間,與我方在連線空閒了20s時仍使用這個連線傳送資料時之間微妙的時間差,所以導致出異常的交易都滿足這樣一個現象:即請求發出去才幾十毫秒就收到了異常。
基本上明確了異常的原因,那解決辦法是?
1. 協調W公司變更配置:前面已經說了我方系統傳送到W公司B系統的交易,沒有出現過這種異常,說明B系統的服務端在我方長連線存在的60s時間裡沒有主動發起斷開此連線,推測B系統的連線最大空閒時間是大於60s。這個需要抓下與B系統的tcp包就可以分析出B系統有沒有主動斷開長連線,空閒多少秒斷開兩個資訊。那可不可以協調W公司,請他們將兩個系統的連線保持最大空閒時間設定為一致呢?這個只能盡力。
2. 優化我方系統:(1)http請求使用重發機制,捕獲NohttpResponseException的異常,重新發送請求,重發3次後還是失敗才停止。由於不知道客戶端捕獲到NohttpResponseException這個異常後,客戶端是否自動關閉了這個連線,每次重發都需要新建連線傳送。新建連線不存在太長的空閒時間問題,因此能夠通過重發解決交易失敗的問題。(2)我方系統主動檢查每個連線的空閒時間,允許設定連線的最大空閒時間M,即客戶端建立的連線空閒M秒後,自動發起斷開連線。只要這個M時間小於服務端的最大空閒時間,將完全避免服務端主動斷開連線導致的異常。
與同事交流,之前鄙司另一個系統到微信支付請求也遇到同樣的NohttpResponseException異常,tcp抓包資訊如下圖:
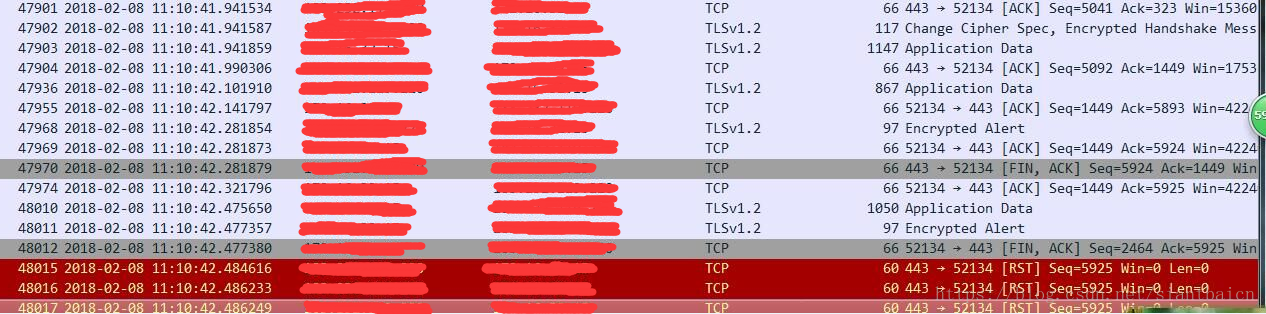
第47970個包是服務端發來的FIN包,收到響應的ack包立刻就想斷開連線(確認是開啟keep-alive的,連線保持),而客戶端又傳送了新的請求包過去,服務端就傳送了三條RST包,斷開了連線。異常的原因推測是apache網站的解釋,對方負載過大主動斷開連線,也按照網站推薦的做法,捕獲異常重發,後面就沒有再遇到因這種異常而引起交易失敗。