
手寫字型識別 --MNIST資料集
Matlab 手寫字型識別
忙過這段時間後,對於上次讀取的Matlab內部資料實現的識別,我回味了一番,覺得那個實在太小。所以打算把資料換成[MNIST資料集][1]。
基礎思想還是相同的,使用TreeBagger(隨機森林)的演算法來訓練樣本,從而實現學習並且識別。這一次不會和上次那麼草率了….同時分享一些關於TreeBagger的理解。
思想
和我上一個識別花是一樣的。使用演算法訓練訓練樣本,得到一個模型model,從而使用predict函式根據模型對測試樣本進行識別。從而達到手寫字型識別的效果。這裡我使用了Google實驗室的Corinna Cortes和紐約大學柯朗研究所的Yann LeCun的建有一個手寫數字資料庫,訓練庫有60,000張手寫數字影象,測試庫有10,000張。
但是因為這個網站上的四個檔案資源似乎不多,導致下載速度很慢,所以我把他們放在我的雲盤裡,給大家下載。雲盤連結 密碼:7awp
因為裡面的內容全部是用二進位制存的,所以我在的檔案裡也順便把解壓的.m的檔案放進去了,也省得大家到處找。
程式碼實現
因為要匯入的圖片太多,一開始我使用imread時我發現,imread似乎是按照一個特定的檔名順序讀取檔案的,所以對於我這些有順序的圖片,他不能按照順序讀。所以我自己想了個方法來讀取60000張訓練樣本。
for i=1:60000
str = strcat('C:\Users\StevenT\Desktop\mnist資料集\train-images-idx3-ubyte\TrainImage_' 之後用同樣的方法獲得10000個測試樣本。
對於測試標籤和訓練標籤的讀取,直接用textread來讀取就可以了。
lable_test = textread('C:\Users\StevenT 讀取到樣本和標籤之後,對樣本和標籤進行訓練。
model = TreeBagger(500,train_image,lable_train); %使用TreeBagger來對訓練樣本進行訓練,獲得一個model
result = predict(model,test_image); %之後使用model來對測試樣本進行預測,將結果存在result內
result = cell2mat(result); %因為result是cell類的,使用cell2mat轉換成字串最後輸出識別率
sc=double(result) - lable_test;
count=sum(sc(:)==48)/100.0; %sc用來儲存相減的結果,當其等於0(ASCII裡是48)的時候就是識別正確的結果,最終得出識別率整體程式碼
clear all;
clc;
%匯入訓練樣本
for i=1:60000
str = strcat('C:\Users\StevenT\Desktop\mnist資料集\train-images-idx3-ubyte\TrainImage_',num2str(i));
name = strcat(str,'.bmp');
name = char(name);
current_img = imread(name);
current_img = reshape(current_img,1,[]); %將矩陣變形
train_image(i,:) = current_img;
end
train_image=double(train_image);
%匯入測試樣本
for i=1:10000
str = strcat('C:\Users\StevenT\Desktop\mnist資料集\t10k-images-idx3-ubyte\TestImage_',num2str(i));
name = strcat(str,'.bmp');
name = char(name);
current_img = imread(name);
current_img = reshape(current_img,1,[]); %將矩陣變形
test_image(i,:) = current_img;
end
test_image=double(test_image);
lable_test = textread('C:\Users\StevenT\Desktop\mnist資料集\t10k-labels-idx1-ubyte\test_lable.txt');
lable_train = textread('C:\Users\StevenT\Desktop\mnist資料集\train-labels-idx1-ubyte\train_lable.txt');
% lable_train = lable_train(1:100);
% lable_test = lable_test(1:100);
model = TreeBagger(500,train_image,lable_train); %使用TreeBagger來對訓練樣本進行訓練,獲得一個model
result = predict(model,test_image); %之後使用model來對測試樣本進行預測,將結果存在result內
result = cell2mat(result); %因為result是cell類的,使用cell2mat轉換成字串
sc=double(result) - lable_test;
count=sum(sc(:)==48)/100.0; %sc用來儲存相減的結果,當其等於0(ASCII裡是48)的時候就是識別正確的結果,最終得出識別率
這裡請大家把地址改成自己的地址。
這是執行後的工作區
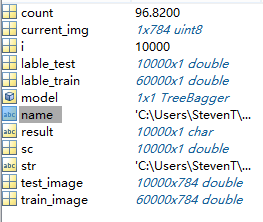
count是識別的準確率,已經達到96.82%了
我的在TreeBagger裡用了50棵決策樹,同時我也嘗試過500棵,講真跑的很久,但是準確率卻只提高了1%,所以我認識到這個決策樹的個數是沒很大影響的…(我的電腦跑的心好累)
這個例子中最重要的莫過於隨機森林TreeBagger這個函式所以我在這裡發一份部落格,我覺得挺好懂的一份(好吧其實是因為有圖)
http://www.36dsj.com/archives/21036
關於演算法的問題吧,我覺得如果不是想搞演算法開發的,還是會用就好:)
以上就是我做的一個小小的手寫識別,後面我會把我的用GUI把自己手寫的數字識別出來的小補充發出來。同時呢,正在學習SVM ,過段時間學的好的話,我會這個也發出來~~
大家共勉:)