手把手教你開發基於深度學習的人臉識別【考勤/簽到】系統
人臉識別介紹
人臉識別技術是一項非接觸式、使用者友好、非配合型的計算機視覺識別技術。隨著機器學習、深度學習等技術的發展,人臉識別的應用正日趨完善和成熟。本文將介紹人臉識別技術如何用於考勤/簽到系統。
本文將主要從以下幾個方面闡述:
- 平臺環境需求
- 涉及的技術點
- 人臉識別系統流程
- 細節設計
平臺環境需求
- 作業系統:Windows 64位
- 第三方庫:OpenCV,Caffe,boost
- 開發語言:C++
- 資料庫:MySQL
技術點
adaboost演算法和CNN用於人臉檢測與定位;
隨機森林演算法/CNN用於人臉關鍵點標定;
卷積神經網路用於人臉特徵提取;
MFC用於設計系統操作介面;
MySQL資料庫用於管理人物-人臉特徵資料庫;
Caffe框架用於上述環節中CNN模型的訓練;
使用Caffe的C++介面進模型行部署和使用;
使用connector C++進行MySQL資料庫的連線。
系統流程
考勤系統主要包含兩個操作:註冊和實時識別記錄。
註冊是指管理員通過軟體介面將需考勤人員登記入庫。 這裡要輸入待考勤人員的資訊。
實時識別記錄是系統自動對來往人群進行人臉識別,並記錄通行者的身份。
進行註冊的流程如下:
開始註冊?人臉檢測特徵提取插入資料庫yes實時識別的流程如下:
開始實時識別?人臉檢測特徵提取搜尋資料庫並記錄身份yes細節設計
人臉檢測
使用OpenCV的人臉檢測器進行人臉的初步檢測,使用Caffe訓練CNN網路進行人臉的二分類判定,將兩部分合在一起完成人臉檢測。此環節需注意根據應用場景調整引數,做到效能與召回率的平衡。
也可使用Python+OpenCV進行視訊中的人臉檢測,參考
人臉關鍵點定位
關鍵點定位的目標是在確知人臉位置的基礎上,精確定位面部的關鍵點,如下圖示意:
獲得面部關鍵點的目的是進行人臉的對齊和標準化。標準化的人臉輸入可以獲得更高的人臉識別精度。
人臉特徵提取
人臉特徵提取是根據上述標準化的人臉區域圖塊,提取出數字化的特徵。即完成從RGB資訊到數值特徵的變換。此環節需要儘量使得同一個人物的不同人臉所提取到的特徵儘可能相似,而不同人物的人臉所提取的特徵儘可能相異。
模型的訓練
人臉識別的CNN網路模型的訓練採用CASIA-Webface資料庫,具體訓練方式參見我的這篇文章。訓練模型的流程參考我的github專案。
本模型在LFW評測集上達到了接近97%的準確率。具備一定的實用性。
模型的部署
部署主要考慮Caffe在Windows平臺的移植,官方的Caffe對Windows系統並不支援,為了使用Caffe的C++介面,我們需要使用Windows版本的Caffe,微軟出了一個版本的Caffe,參考這裡。
MySQL資料庫的使用
MySQL的安裝和配置詳見這裡。
我們使用預設的3306埠,配置好賬戶密碼後,即可建立資料表。
MFC工程的搭建
使用Visual Studio 2013建立MFC工程,設計本軟體的介面。詳細的配置流程參考這裡。
本軟體設計介面如下
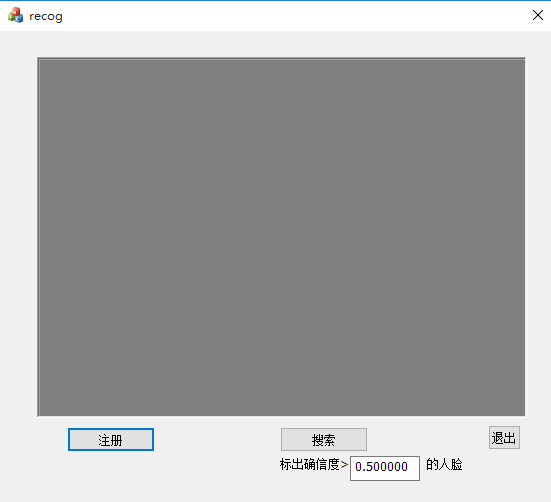
主要包括註冊和搜尋兩個功能。點選註冊時,按鈕下方出現輸入框,用於輸入待考察人物的資訊。
軟體使用
註冊,點選註冊按鈕,並選定需要註冊的人臉。 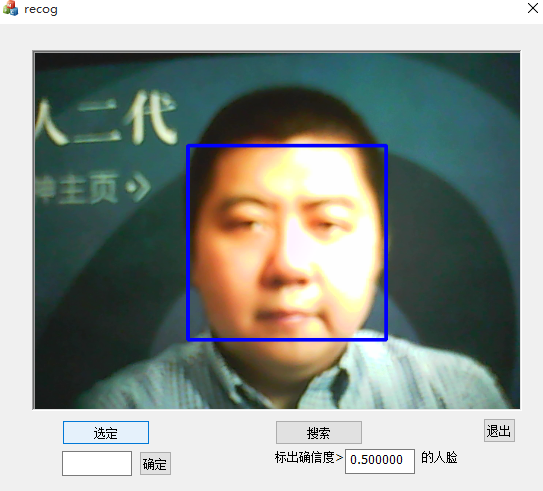
輸入人物資訊,並提交到資料庫。 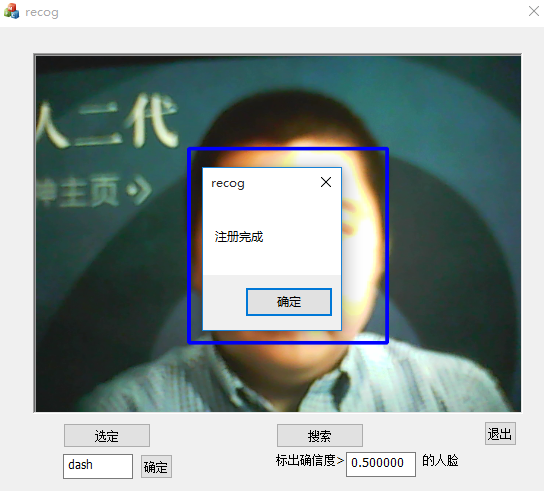
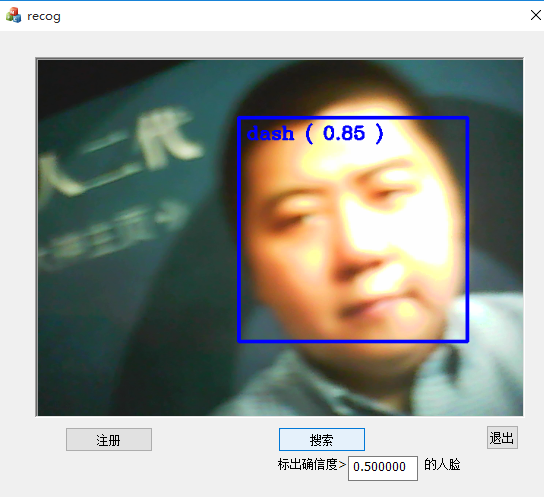
搜尋,點選搜尋,介面中實時識別人物,並將識別到的資訊展示在人臉上。